







深度优先搜索(DFS)
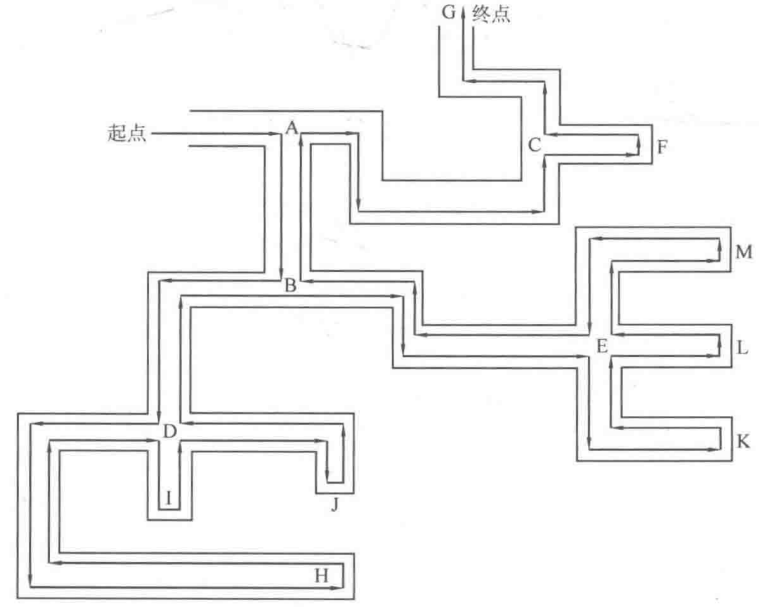
从上图可知,从起点开始前进,当碰到岔道口时,总是选择其中一条岔路前进(例如图中总是先选择最右手边的岔路),在岔路上如果又遇到新的岔道口,仍然选择新岔道口的其中一条岔路前进,直到碰到死胡同才回退到最近的岔道口选择另一条岔路。也就是说,当碰到岔道口时,总是以"深度"作为前进的关键词,不碰到死胡同就不回头,因此把这种搜索的方式称为深度优先搜索(Depth First Search, D F S {\rm DFS} DFS )。
从迷宫的例子还应该注意到,深度优先搜索会走遍所有路径,并且每次走到死胡同就代表一条完整路径的形成。这就是说,深度优先搜索是一种枚举所有完整路径以遍历所有情况的搜索方法。
在上图的迷宫中,把迷宫中的关键结点(岔道口或死胡同)用字母代替,然后来看看在 D F S {\rm DFS} DFS 的过程中是如何体现在这些关键结点上的(已经在图中标记了字母):
1)从第一条路可以得到先后访问的结点为
A
B
D
H
{\rm ABDH}
ABDH,此时
H
{\rm H}
H 到达了死胡同,于是退回到
D
{\rm D}
D ;
再到
I
{\rm I}
I ,但是
I
{\rm I}
I 也是死胡同,再次退回到
D
{\rm D}
D ;
着来到
J
{\rm J}
J ,很不幸
J
{\rm J}
J 还是死胡同,于是退回到
D
{\rm D}
D ;
但是此时
D
{\rm D}
D 的岔路已经走完了,因此退回到上一个岔道口
B
{\rm B}
B 。
2)从
B
{\rm B}
B 到达
E
{\rm E}
E ,接下来又是三条岔路 (
K
、
L
、
M
{\rm K、L、M}
K、L、M ),依次进行枚举:
前往
K
{\rm K}
K ,发现
K
{\rm K}
K 是死胡同,退回到
E
{\rm E}
E ;
前往
L
{\rm L}
L ,发现
L
{\rm L}
L 是死胡同,退回到
E
{\rm E}
E ;
前往
M
{\rm M}
M ,发现
M
{\rm M}
M 是死胡同,退回到
E
{\rm E}
E 。
最后因为
E
{\rm E}
E 的岔路都访问完毕了,于是退回到
B
{\rm B}
B 。
但是
B
{\rm B}
B 的所有岔路(
D
{\rm D}
D 和
E
{\rm E}
E )也都访问完了,因此退回到
A
{\rm A}
A 。
3)访问
A
{\rm A}
A 的另一个岔路可以到达
C
{\rm C}
C ,而
C
{\rm C}
C 仍然有两条岔路(
F
{\rm F}
F 和
G
{\rm G}
G ),
于是先访问
F
{\rm F}
F ,发现
F
{\rm F}
F 是死胡同,退回到
C
{\rm C}
C ;
再访问
G
{\rm G}
G ,发现是出口,
D
F
S
{\rm DFS}
DFS 过程结束,
整个 D F S {\rm DFS} DFS 过程中先后访问结点的顺序为 A B D H I J E K L M C F G {\rm ABDHIJEKLMCFG} ABDHIJEKLMCFG 。
例一
接下来讲解一个例子,读者需要从中理解其中包含的 D F S {\rm DFS} DFS 思想:
有
n
{\rm n}
n 件物品,每件物品的重量为 w[i] ,价值为c[i]。现在需要选出若干件物品放入一个容量为
V
{\rm V}
V 的背包中,使得在选入背包的物品重量和不超过容量
V
{\rm V}
V 的前提下,让背包中物品的价值之和最大,求最大价值。(
1
≤
n
≤
20
{\rm 1 \le n \le 20}
1≤n≤20 )
这样的话,对每件物品都有选或者不选两种选择,而这就是所谓的“岔道口”。
题目要求选择的物品重量总和不能超过
V
{\rm V}
V ,因此一旦选择的物品重量总和超过
V
{\rm V}
V ,就会到达“死胡同”,需要返回最近的“岔道口”。
显然,每次都要对物品进行选择,因此 D F S {\rm DFS} DFS 函数的参数中必须记录当前处理的物品编号 i n d e x {\rm index} index 。而题目中涉及了物品的重量与价值,因此也需要参数来记录在处理当前物品之前,已选物品的总重量 s u m W {\rm sumW} sumW 与总价值 s u m C {\rm sumC} sumC 。于是 D F S {\rm DFS} DFS 函数看起来是这个样子:
void DFS(int index, int sumW, int sumC) { ... }
1)如果选择不放入
i
n
d
e
x
{\rm index}
index 号物品,那么
s
u
m
W
{\rm sumW}
sumW 与
s
u
m
C
{\rm sumC}
sumC 就将不变,接下来处理
i
n
d
e
x
+
1
{\rm index+1}
index+1 号物品,即前往DFS(index + 1, sumW, sumC)这条分支。
2)而如果选择放入
i
n
d
e
x
{\rm index}
index 号物品那么
s
u
m
W
{\rm sumW}
sumW 将增加当前物品的重量w[index],
s
u
m
C
{\rm sumC}
sumC 将增加当前物品的价值c[index],接着处理
i
n
d
e
x
+
1
{\rm index+1}
index+1 号物品,即前往DFS(index + 1, sumW + w[index], sumC + c[index])这条分支。
一旦 i n d e x {\rm index} index 增长到了 n {\rm n} n ,则说明已经把 n {\rm n} n 件物品处理完毕(因为物品下标为从 0 {\rm 0} 0 到 n − 1 {\rm n-1} n−1 ),此时记录的 s u m W {\rm sumW} sumW 和 s u m C {\rm sumC} sumC 就是所选物品的总重量和总价值。如果 s u m W {\rm sumW} sumW 不超过 V {\rm V} V 且 s u m C {\rm sumC} sumC 大于一个全局的记录最大总价值的变量 m a x V a l u e {\rm maxValue} maxValue ,就说明当前的这种选择方案可以得到更大的价值,于是用 s u m C {\rm sumC} sumC 更新 m a x V a l u e {\rm maxValue} maxValue 。
下面的代码体现了上面的思路,请注意“岔道口”和“死胡同”在代码中是如何体现的:
#include <iostream>
using namespace std;
const int maxn = 30;
int n, V, maxValue = 0; //物品件数n,背包容量V,最大价值maxValue
int w[maxn], c[maxn]; //w[i]为每件物品的重量,c[i]为每件物品的价值
//DFS,index为当前处理的物品编号
//sumW和sumC分别为当前总重量和当前总价值
void DFS(int index, int sumW, int sumC) {
if (index == n) { //已经完成对n件物品的选择(死胡同)
if (sumW <= V && sumC > maxValue)
maxValue = sumC; //不超过背包容量时更新最大价值maxvalue
return;
}
//岔道口
DFS(index + 1, sumW, sumC); //不选择第index件物品
DFS(index + 1, sumW + w[index], sumC + c[index]); //选择第index件物品
}
int main() {
cin >> n >> V;
for (int i = 0; i < n; i++)
cin >> w[i]; //每件物品的重量
for (int i = 0; i < n; i++)
cin >> c[i]; //每件物品的价值
DFS(0, 0, 0); //初始时为第0件物品、当前总重量和总价值均为0
cout << maxValue << endl;
return 0;
}
输入数据:
5 8 //5件物品,背包容量为8
3 5 1 2 2 //物品重量
4 5 2 1 3 //物品价值
输出结果:
10
可以注意到,由于每件物品有两种选择,因此上面代码的复杂度为 O ( 2 n ) {\rm O(2^n)} O(2n) ,这看起来不是很优秀。但是可以通过对算法的优化,来使其在随机数据的表现上有更好的效率。在上述代码中,总是把 n {\rm n} n 件物品的选择全部确定之后才去更新最大价值,但是事实上忽视了背包容量不超过 V {\rm V} V 这个特点。也就是说,完全可以把对 s u m W {\rm sumW} sumW 的判断加入“岔道口”中,只有当 s u m W ≤ V {\rm sumW \le V} sumW≤V 时才进入岔道,这样效率会高很多,代码如下:
void DFS(int index, int sumW, int sumC) {
if (index == n)
return; //已经完成对n件物品的选择
DFS(index + 1, sumW, sumC);//不选第index件物品
//只有加入第index件物品后未超过容量V,才能继续
if (sumW + w[index] <= V) {
if (sumC + c[index] > maxValue)
maxValue = sumC + c[index]; //更新最大价值maxValue
DFS(index + 1, sumW + w[index], sumC + c[index]); //选择第index件物品
}
}
可以看到,原先第二条岔路是直接进入的,但是这里先判断加入第 i n d e x {\rm index} index 件物品后能否满足容量不超过 V {\rm V} V 的要求,只有当条件满足时才更新最大价值以及进入这条岔路,这样可以降低计算量,使算法在数据不极端时有很好的表现。这种通过题目条件的限制来节省 D F S {\rm DFS} DFS 计算量的方法称作剪枝(前提是剪枝后算法仍然正确)。剪枝是一门艺术,学会灵活运用题目给出的条件,可以使得代码的计算量大大降低,很多题目甚至可以使时间复杂度下降好几等级。
例二
上面的这个问题给出了一类常见 D F S {\rm DFS} DFS 问题的解决方法,枚举从 N {\rm N} N 个整数中选择 K {\rm K} K 个数的所有方案。
例如这样一个问题:
给定 N {\rm N} N 个整数(可能有负数),从中选择 K {\rm K} K 个数,使得这 K {\rm K} K 个数之和恰好等于一个给定的整数 X {\rm X} X ;如果有多种方案,选择它们中元素平方和最大的一个。数据保证这样的方案唯一。例如,从4个整数 { 2 , 3 , 3 , 4 } {\rm \{2,3,3,4 \} } {2,3,3,4} 中选择2个数,使它们的和为6,显然有两种方案 { 2 , 4 } {\rm \{2,4 \} } {2,4} 与 { 3 , 3 } {\rm \{ 3,3 \} } {3,3} ,其中平方和最大的方案为 { 2 , 4 } {\rm \{2,4 \} } {2,4} 。
与之前的问题类似,此处仍然需要记录当前处理的整数编号 i n d e x {\rm index} index ;由于要求恰好选择 K {\rm K} K 个数,因此需要一个参数 n o w K {\rm nowK} nowK 来记录当前已经选择的数的个数;另外,还需要参数 s u m {\rm sum} sum 和 s u m S q u {\rm sumSqu} sumSqu 分别记录当前已选整数之和与平方和。于是 D F S {\rm DFS} DFS 就是下面这个样子:
void DFS(int index, int nowK, int sum, int sumSqu) { ... }
此处主要讲解如何保存最优方案,即平方和最大的方案。首先,需要一个数组temp,用以存放当前已经选择的整数。这样,当试图进入“选
i
n
d
e
x
{\rm index}
index 号数”这条分支时,就把A[index]加入temp 中;而当这条分支结束时,就把它从temp中去除,使它不会影响“不选
i
n
d
e
x
{\rm index}
index 号数”这条分支。接着,如果在某个时候发现当前已经选择了
K
{\rm K}
K 个数,且这
K
{\rm K}
K 个数之和恰好为
X
{\rm X}
X 时,就去判断平方和是否比已有的最大平方和
m
a
x
S
u
m
S
q
u
{\rm maxSumSqu}
maxSumSqu 还要大:如果确实更大,那么说明找到了更优的方案,把temp赋给用以存放最优方案的数组ans。这样,当所有方案都枚举完毕后,ans存放的就是最优方案,
m
a
x
S
u
m
S
q
u
{\rm maxSumSqu}
maxSumSqu 存放的就是对应的最优值。
下面给出代码:
#include <iostream>
#include <vector>
using namespace std;
//序列A中n个数选k个数使得和为x,最大平方和为maxSumSqu
const int maxn = 30;
int n, k, x, maxSumSqu = -1, A[maxn];
//temp存放临时方案,ans存放平方和最大的方案
vector<int> temp, ans;
//当前处理index号整数,当前已选整数个数为nowK
//当前已选整数之和为sum,当前已选整数平方和为sumSqu
void DFS(int index, int nowK, int sum, int sumSqu) {
if (nowK == k && sum == x) { //找到k个数的和为x
if (sumSqu > maxSumSqu) { //如果比当前找到的更优
maxSumSqu = sumSqu; //更新最大平方和
ans = temp; //更新最优方案
}
return;
}
//已经处理完n个数,或者超过k个数,或者和超过x,返回
if (index == n || nowK > k || sum > x)
return;
//选index号数
temp.push_back(A[index]);
DFS(index + 1, nowK + 1, sum + A[index], sumSqu + A[index] * A[index]);
temp.pop_back();
//不选index号数
DFS(index + 1, nowK, sum, sumSqu);
}
int main() {
//输入n,k,x
cin >> n >> k >> x;
for (int i = 0; i < n; i++)
cin >> A[i];
DFS(0, 0, 0, 0);
//存在满足条件的选择方案
if (ans.size() != 0)
for (int i = 0; i < ans.size(); i++)
cout << ans[i] << "\t";
return 0;
}
输入数据:
4 2 6
2 3 3 4
输出结果:
2 4















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









