






前言
DeepSeek公开了一套模型蒸馏的基本范式,同时公开了基于Qwen2.5、Llama3的蒸馏模型。
本文仅为简单介绍DeepSeep模型蒸馏范式的基本流程。
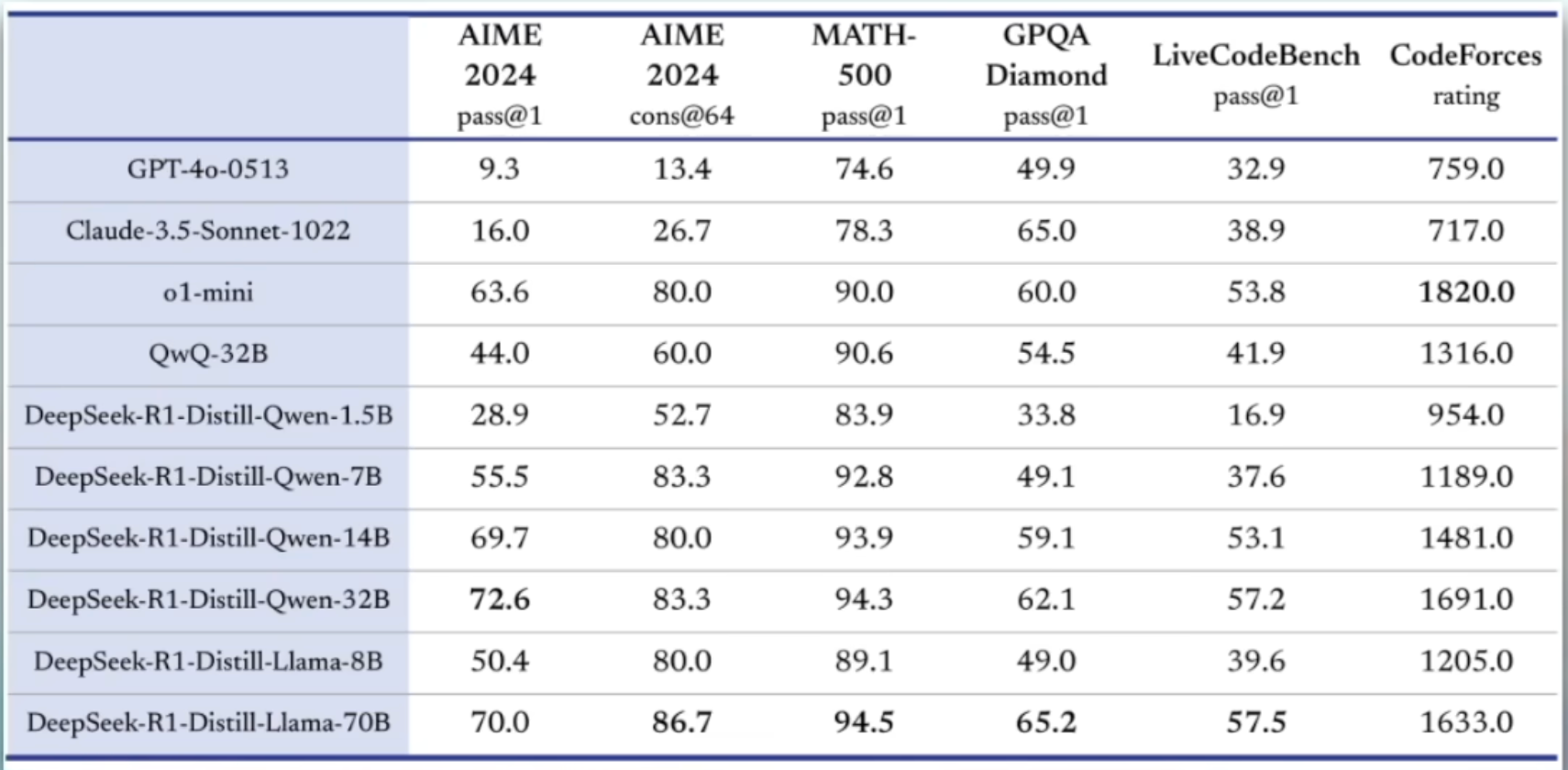
其中,Qwen1.5B的推理性能已经超过了GPT4o,而Qwen32B到推理性能可以达到GPTo1-mini的水平。
- AIME2024pass@1:测试模型在高难度数学推理和问题解决中的一次性表现能力。
- AIME2024cons@64:测试模型在复杂数学任务中的稳定性和一致性能力。
- MATH500pass@1:测试模型在广泛数学知识和高难度数学问题中的一次性解决能力。
- GPQADiamondpass@1:测试模型在跨学科通用知识和复杂问答任务中的一次性表现能力。
- LiveCodeBenchpass@1:测试模型在编程任务中的代码生成和问题解决能力。
- CodeForcesrating:测试模型在算法设计和编程竞赛中的综合表现能力。
模型蒸馏范式

模型厂家对某个模型一般会开源两个版本,Base和Chat。
- Base:只经过了预训练,没有经过全量指令微调,对话可能会胡言乱语,但有更好的调教空间。
- Chat:经过了全量指令微调,有对话能力。
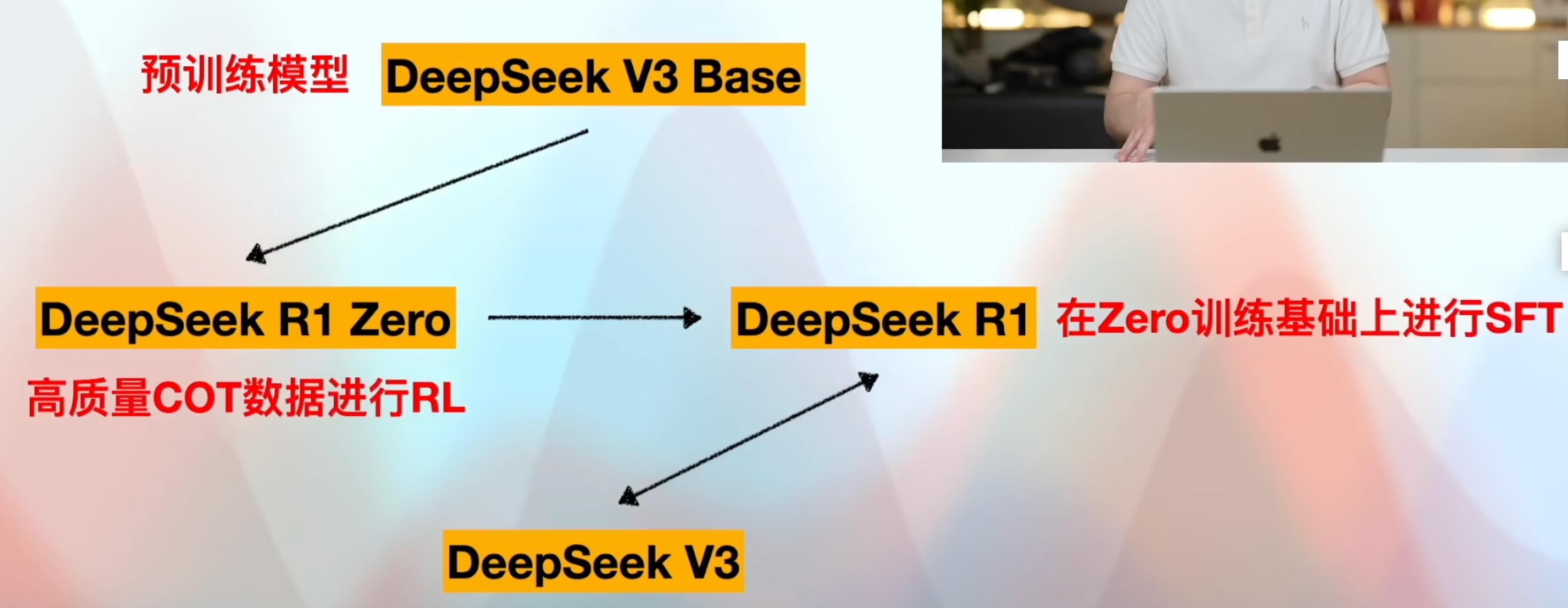
DeepSeek R1提出的模型蒸馏路径:
- 选择某个Base模型。 DeepSeek开源的蒸馏模型都基于Base版本。
- 对Base模型进行全量指令微调,利用高质量的问答数据,数据量不用大,几千条数据。知道基本的对话范式,学会开符、终止符。
- 利用非常大量COT数据进行训练。训练后 会把思考连看成是回答用户内容的一部分,输出时携带思考内容。所以需要经过大量的数据进行微调。
- 经过COT数据微调之后,可能模型还有很多问答上的问题,需要再进行训练。


DeepSeek模型训练路径(简化版)

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









