






《编译原理》实验三:中间代码生成器 lex + yacc 版


项目结构

具体 lex 和 yacc 环境的安装和命令使用自行网上查询吧,我也记不得了,下面一些文件就是上面文件执行相关命令之后生成的
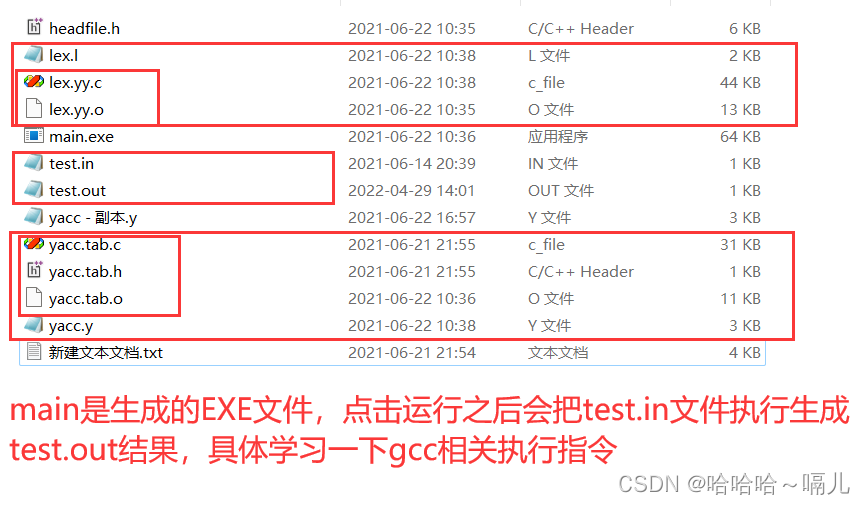
// headfile.h
#ifndef CP_H
#define CP_H
#include <stdio.h>
#include <string.h>
#include <malloc.h>
typedef struct listele
{
int instrno;
struct listele *next;
}listele;
listele* new_listele(int no)
{
listele* p = (listele*)malloc(sizeof(listele));
p->instrno = no;
p->next = NULL;
return p;
}
typedef struct instrlist
{
listele *first,*last;
}instrlist;
instrlist* new_instrlist(int instrno)
{
instrlist* p = (instrlist*)malloc(sizeof(instrlist));
p->first = p->last = new_listele(instrno);
return p;
}
instrlist* merge(instrlist *list1, instrlist *list2)
{
instrlist *p;
if (list1 == NULL) p = list2;
else
{
if (list2!=NULL)
{
if (list1->last == NULL)
{
list1->first = list2->first;
list1->last =list2->last;
}else list1->last->next = list2->first;
list2->first = list2->last = NULL;
free(list2);
}
p = list1;
}
return p;
}
typedef struct node
{
instrlist *truelist, *falselist, *nextlist;
char addr[256];
char lexeme[256];
char oper[3];
int instr;
}node;
int filloperator(node *dst, char *src)
{
strcpy(dst->oper, src);
return 0;
}
int filllexeme(node *dst, char *yytext)
{
strcpy(dst->lexeme, yytext);
return 0;
}
int copyaddr(node *dst, char *src)
{
strcpy(dst->addr, src);
return 0;
}
int new_temp(node *dst, int index)
{
sprintf(dst->addr, "T%d", ++index);
return 0;
}
int copyaddr_fromnode(node *dst, node src)
{
strcpy(dst->addr, src.addr);
return 0;
}
typedef struct codelist
{
int linecnt, capacity;
int temp_index;
char **code;
}codelist;
codelist* newcodelist()
{
codelist* p = (codelist*)malloc(sizeof(codelist));
p->linecnt = 100;
p->capacity = 1024;
p->temp_index = 0;
p->code = (char**)malloc(sizeof(char*)*1024);
return p;
}
int get_temp_index(codelist* dst)
{
return dst->temp_index++;
}
int nextinstr(codelist *dst) { return dst->linecnt; }
int Gen(codelist *dst, char *str)
{
if (dst->linecnt >= dst->capacity)
{
dst->capacity += 1024;
dst->code = (char**)realloc(dst->code, sizeof(char*)*dst->capacity);
if (dst->code == NULL)
{
printf("short of memeory\n");
return 0;
}
}
dst->code[dst->linecnt] = (char*)malloc(strlen(str)+20);
strcpy(dst->code[dst->linecnt], str);
dst->linecnt++;
return 0;
}
char tmp[1024];
int gen_goto_blank(codelist *dst)
{
sprintf(tmp, "goto ");
Gen(dst, tmp);
return 0;
}
int gen_goto(codelist *dst, int instrno)
{
sprintf(tmp, "goto %d", instrno);
Gen(dst, tmp);
return 0;
}
int gen_if(codelist *dst, node left, char* op, node right)
{
sprintf(tmp, "if %s %s %s goto", left.addr, op, right.addr);
Gen(dst, tmp);
return 0;
}
int gen_1addr(codelist *dst, node left, char* op)
{
sprintf(tmp, "%s %s", left.addr, op);
Gen(dst, tmp);
return 0;
}
int gen_2addr(codelist *dst, node left, char* op, node right)
{
sprintf(tmp, "%s = %s %s", left.addr, op, right.addr);
Gen(dst, tmp);
return 0;
}
int gen_3addr(codelist *dst, node left, node op1, char* op, node op2)
{
sprintf(tmp, "%s = %s %s %s", left.addr, op1.addr, op, op2.addr);
Gen(dst, tmp);
return 0;
}
int gen_assignment(codelist *dst, node left, node right)
{
gen_2addr(dst, left, "", right);
return 0;
}
int backpatch(codelist *dst, instrlist *list, int instrno)
{
if (list!=NULL)
{
listele *p=list->first;
char tmp[20];
sprintf(tmp, " %d", instrno);
while (p!=NULL)
{
if (p->instrno<dst->linecnt)
strcat(dst->code[p->instrno], tmp);
p=p->next;
}
}
return 0;
}
/*
int print(codelist* dst)
{
int i;
int j;
for (j=100; j < dst->linecnt; j++);
for (i=100; i < dst->linecnt; i++)
{
if(strcmp(dst->code[i],"goto ")==0)
{
printf("%d: goto %d\n", i, j);continue;
}
printf("%d: %s\n", i, dst->code[i]);
}
printf("%d: halt\n", i);
return 0;
}
/*/
//*
int print(codelist* dst)
{
int i;
for (i=100; i < dst->linecnt; i++)
{
printf("%d: %s\n", i, dst->code[i]);
}
printf("%d: halt\n", i);
return 0;
}
//*/
#endif
// lex.l
%{
#include "yacc.tab.h"
%}
delim [ \t\n\r]
ws {delim}+
letter [A-Za-z]
digit [0-9]
id {letter}({letter}|{digit})*
integer {digit}+
exponent E[+-]?{integer}
number {integer}{exponent}?
real integer(\.integer)?{exponent}?
halt [EOF]
%option noyywrap
%%
if { return( IF ); }
else { return( ELSE ); }
while { return( WHILE ); }
do { return( DO ); }
for { return( FOR ); }
switch { return( SWITCH ); }
case { return( CASE ); }
default { return( DEFAULT ); }
break { return( BREAK ); }
true { return( TRUE ); }
false { return( FALSE ); }
int { return( INT ); }
long { return( LONG ); }
char { return( CHAR ); }
bool { return( BOOL ); }
float { return( FLOAT ); }
double { return( DOUBLE ); }
"<"|"<="|">"|">="|"!="|"==" { filloperator(&yylval, yytext); return( REL); }
"+" { return( '+' ); }
"-" { return( '-' ); }
"*" { return( '*' ); }
"/" { return( '/' ); }
"=" { return( '=' ); }
"{" { return( '{' ); }
"}" { return( '}' ); }
"[" { return( '[' ); }
"]" { return( ']' ); }
"(" { return( '(' ); }
")" { return( ')' ); }
";" { return( ';' ); }
{ws} { }
{id} { filllexeme(&yylval, yytext); return( ID ); }
{number} { filllexeme(&yylval, yytext); return( NUMBER ); }
{real} { filllexeme(&yylval, yytext); return( REAL ); }
{halt} { filllexeme(&yylval, yytext); return( HALT ); }
%%
// yacc.y
%{
#include "headfile.h"
#define YYSTYPE node
#include "yacc.tab.h"
int yyerror();
int yyerror(char* msg);
extern int yylex();
codelist* list;
%}
%token BASIC NUMBER REAL ID TRUE FALSE
%token INT LONG CHAR BOOL FLOAT DOUBLE HALT
%token REL
%token IF ELSE WHILE DO BREAK FOR SWITCH CASE DEFAULT
%left '+' '-'
%left '*' '/'
%%
block : statement { }
;
statement :
IF '(' boolean ')' statement
{
backpatch(list, $3.truelist, $5.instr);
$$.nextlist = merge($3.falselist, $6.nextlist);
}
| WHILE '(' boolean ')' statement
{
backpatch(list, $7.nextlist, $2.instr);
backpatch(list, $4.truelist, $6.instr);
$$.nextlist = $4.falselist;
gen_goto(list, $2.instr);
}
| assignment ';' { $$.nextlist = NULL; }
| HALT { $$.nextlist = NULL; }
;
assignment : ID '=' boolean
{
copyaddr(&$1, $1.lexeme); gen_assignment(list, $1, $3);
}
;
boolean : expression REL expression
{
$$.truelist = new_instrlist(nextinstr(list));
$$.falselist = new_instrlist(nextinstr(list)+1);
gen_if(list, $1, $2.oper, $3);
gen_goto_blank(list);
}
| expression { copyaddr_fromnode(&$$, $1); }
;
expression :
expression '+' expression
{ new_temp(&$$, get_temp_index(list));
gen_3addr(list, $$, $1, "+", $3);
}
| expression '-' expression
{ new_temp(&$$, get_temp_index(list));
gen_3addr(list, $$, $1, "-", $3);
}
| expression '*' expression
{ new_temp(&$$, get_temp_index(list));
gen_3addr(list, $$, $1, "*", $3);
}
| expression '/' expression
{ new_temp(&$$, get_temp_index(list));
gen_3addr(list, $$, $1, "/", $3);
}
| NUMBER { copyaddr(&$$, $1.lexeme); }
;
%%
int yyerror(char* msg)
{
printf("\nERROR: %s\n", msg);
return 0;
}
int main()
{
list = newcodelist();
//打开文件
freopen("test.in", "rt+", stdin);
freopen("test.out", "wt+", stdout);
yyparse();
print(list);
//关闭文件
fclose(stdin);
fclose(stdout);
return 0;
}
// test.in 输入文件
sum = 0;
x = 9;
while (sum <= 100) sum = sum + x;
if (sum > 101) sum = sum - 100;
输出结果


















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









