




Mysql相关知识
慢查询
慢查询:页面加载过慢、接口压测响应时间过长(超过1s)
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
定位方案:
1、开源工具
- 调试工具:Arthas
- 运维工具:Prometheus 、Skywalking
2、MySQL自带慢日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:

配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息 /var/lib/mysql/localhost-slow.log

SQL 执行计划分析与优化
当 SQL 执行很慢时,可以通过 执行计划(Execution Plan) 分析具体的性能瓶颈。
MySQL 提供 EXPLAIN 或 DESC 命令来查看 SELECT 语句的执行过程。
1.常见慢 SQL 场景与优化思路
| 场景 | 典型问题 | 优化手段 |
|---|---|---|
聚合查询(GROUP BY、SUM、COUNT 等) | 聚合前扫描了大量无用数据 | - 使用临时表提前过滤数据 - 添加合适的索引(覆盖索引) |
多表关联查询(JOIN) | 关联条件无索引,导致全表扫描 | - 确保关联字段有索引 - 减少不必要的字段返回( SELECT * → 指定字段) - 优化 JOIN 顺序 |
| 表数据量过大 | 全表扫描或不走索引 | - 建立合适的单列索引或组合索引 - 考虑分表、分区 |
深度分页查询(LIMIT offset, size) | MySQL 需要扫描 offset 条数据后再返回 | - 使用索引进行 基于主键或条件的“游标”分页 - 先查主键 ID 再回表获取数据 |
2. 执行计划分析方法
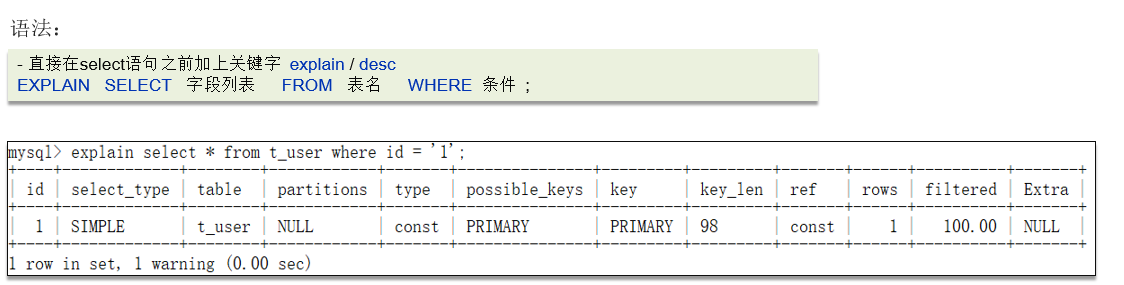
返回字段主要有:
| 字段 | 含义 | 重点关注 |
|---|---|---|
| id | 查询中执行顺序的标识(越大优先执行) | 同层级 id,执行顺序由上到下 |
| select_type | 查询类型(SIMPLE、PRIMARY、SUBQUERY、DERIVED 等) | 是否出现不必要的子查询 |
| table | 当前访问的表 | 是否出现不必要的表 |
| type | 连接类型(性能由好到差:system > const > eq_ref > ref > range > index > ALL) | 避免 ALL(全表扫描) |
| possible_keys | MySQL 可能用到的索引 | 是否存在可用索引 |
| key | 实际使用的索引 | 是否走了预期索引 |
| rows | MySQL 预估扫描的行数 | 值越小越好 |
| Extra | 额外信息(如 Using filesort、Using temporary) | 避免出现 Using filesort、Using temporary |
type字段说明:
- system:表中只有一行数据(系统表),一次就取完。
- const:一次就能通过主键或唯一索引定位到一行数据。
- er_ref:唯一性索引等值匹配,并且在多表 JOIN 时,每次关联只返回一条记录。
- ref:非唯一索引等值匹配,可能返回多行数据。
- range:范围扫描,通过索引取部分数据。
- index:全索引扫描(读取整个索引树,而不是表)。
- all:全表扫描,逐行读取数据。
索引
基本概念
索引(index)是帮助MySQL高效获取的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构(B+树),这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
树结构分析:
-
二叉查找树(Binary Search Tree, BST)
- 特点:
- 每个节点最多包含两个子节点,左子树的值小于根节点,右子树的值大于根节点。
- 查找的平均时间复杂度为 O(log n)。
- 缺陷
- 在极端情况下(如插入的数据是有序的),二叉树会退化为链表,查找效率变为 O(n)。
- 高度不平衡,导致在海量数据场景下难以保证稳定的查询效率。
- 特点:
-
红黑树(Red-Black Tree)
- 特点:
- 一种自平衡二叉查找树,通过颜色标记和旋转操作保持平衡。
- 保证树的高度接近
log n,查找、插入、删除的时间复杂度均为O(log n)。
- 缺陷:
- 虽然避免了退化,但依旧是二叉树结构,树高偏大。
- 对数据库而言,每次查找需要更多的磁盘 I/O,不适合大规模数据场景。
- 特点:
-
B 树(Balance Tree)
- 特点:
- 多路平衡查找树,每个节点可存储多个键值和子节点指针。
- 树的高度较低,减少了查找时的磁盘 I/O 次数。
- 节点既存储索引,也可以存储数据。
- 缺陷:
- 数据分布在所有节点中,范围查询效率较低。
- 顺序遍历性能不如 B+ 树。
- 特点:
-
B+ 树
- 特点:
- B 树的变体,所有数据存储在叶子节点,非叶子节点仅存储索引。
- 叶子节点之间通过链表相连,支持高效的范围查询与顺序遍历。
- 每个节点通常对应一个磁盘页,单次 I/O 可加载更多索引。
- 优势:
- 树高度更低,减少磁盘访问次数。
- 范围查询和排序操作效率极高。
- 查询性能稳定,适合大规模数据场景。
- 特点:
聚集索引和二级索引
聚集索引(聚簇索引):
- 数据存储与索引放到了一块,B+树的叶子节点保存了整行数据。
- 必须有且只能有一个。
- 聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
二级索引(非聚簇/聚集索引):
- 将数据与索引分开存储,B+树的叶子节点保存对应的聚集索引(一般是主键)。
- 可以存在多个。
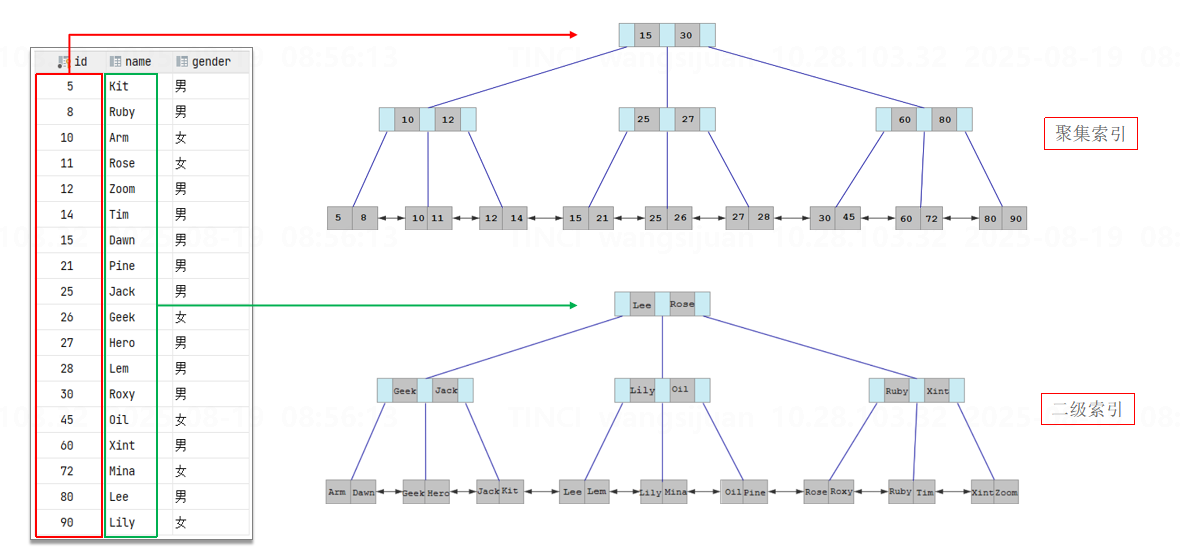
回表查询
通过二级索引找到对应的主键值,到聚集索引中查找整行数据,这个过程就是回表。
示例:select * from user where name = ‘Arm’;
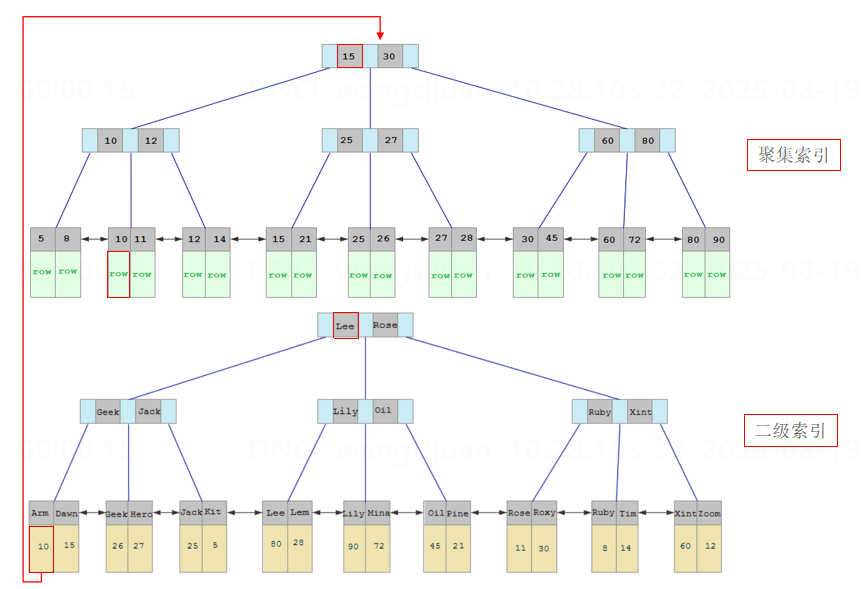
覆盖索引
如果一个查询所需要的列全部都能从索引中直接获取,而不触发回表查询,那么这个索引就称为覆盖索引。这一概念是针对具体查询而言的,无法单纯看索引本身就判定。
索引创建原则
-
针对查询频繁的表建立索引
- 对于数据量大且经常被查询的表,索引可以显著提高查询效率。
- 对于临时表、更新频繁但查询少的表,可以考虑少用或不用索引,以避免维护开销。
-
索引列选择
- 常用作查询条件的列(WHERE)、排序列(ORDER BY)和分组列(GROUP BY)应优先建立索引。
- 选择区分度高(即不同值较多)的列作为索引,区分度越高,索引效率越高。
- 尽量建立唯一索引(UNIQUE),不仅保证数据唯一性,也提升查询性能。
-
字符串类型字段的索引优化
- 对长度较大的字符串字段,可使用前缀索引,只对前 N 个字符建立索引,减少存储开销。
- 前缀长度需兼顾选择性与存储空间,避免过短导致区分度低,过长占用太多空间。
-
联合索引的使用
- 优先使用联合索引(复合索引),减少单列索引数量。
- 联合索引可覆盖查询(即查询所需字段全部在索引中),避免回表,提高查询效率。
- 注意联合索引的列顺序,应遵循“最左前缀原则”,即查询条件中最常用的列放在最左边。
-
索引数量控制
- 索引并非越多越好,过多索引会增加 插入、更新、删除操作 的开销。
- 需要根据查询频率和业务场景,合理平衡查询效率与写入性能。
-
索引列的约束
- 索引列尽量设置为 NOT NULL,避免存储NULL值带来的查询性能下降。
- 对经常需要排序或参与JOIN操作的列,NOT NULL 可以保证索引效率更高。
索引失效的情况
- 违反最左前缀法则
- 复合索引必须按照最左前缀原则来使用,从最左边的列开始匹配。若跳过中间某一列,后续的列无法使用索引。
- 范围查询之后的列失效
- 在复合索引中,如果某一列使用了范围查询(如 >、<、BETWEEN、LIKE ‘abc%’),则它右边的列无法继续利用索引。
- 在索引列上进行运算或函数操作
- 如 WHERE YEAR(create_time) = 2023、WHERE age + 1 = 30,索引列被运算或函数包裹后,无法使用索引。
- 数据类型不一致
- 如字符串字段不加单引号(WHERE phone = 13888888888 而不是 WHERE phone = ‘13888888888’),会触发隐式类型转换,导致索引失效。
- 模糊查询导致索引失效
- LIKE ‘%abc’ 前置 % 会使索引失效,因为无法确定开头位置。
- 但 LIKE ‘abc%’ 可以使用索引(属于范围查询)。
- 使用 OR 连接条件,且两边字段不都带索引
- 例如 WHERE id = 1 OR name = ‘Tom’,如果 id 有索引但 name 没有,那么整个查询会放弃索引。
- 使用 NOT、!=、<>、NOT IN、NOT LIKE 等非等值比较
- 索引一般对等值查询最友好,这些条件往往会导致优化器放弃索引,转为全表扫描。
- IS NULL 或 IS NOT NULL
- IS NULL 有时能用索引(取决于表结构及优化器),但 IS NOT NULL 大概率会失效。
- 使用函数索引但没走函数化查询
- 如果建了函数索引(如 LOWER(email)),查询时必须保持一致,否则无效。
- 数据区分度过低
- 如果某个字段索引的选择性很差(如性别字段仅有 M/F),优化器可能会选择全表扫描而不是走索引。
- 强制使用索引但不合适
- 使用 FORCE INDEX 强行指定索引时,如果优化器判定全表扫描更优,反而会拖慢性能。
sql优化
- 表的设计优化(参考阿里开发手册《嵩山版》)
- 合理选择数据类型:数值型字段要根据实际情况选择 tinyint、int 或 bigint,避免过大浪费存储。
- 字符串类型:char 定长存储效率高,适合固定长度的字段(如身份证号、手机号);varchar 可变长度,适合长度不固定的场景。
- 避免使用 NULL 作为默认值字段,能用 NOT NULL + 默认值代替,减少索引、统计开销。
- 适当的范式设计,必要时结合反范式优化,减少过度 join。
- 索引优化
- 遵循创建原则。
- 避免失效情况。
- sql语句优化
- SELECT 指定字段,避免
SELECT *,减少数据传输和解析开销。 - 避免导致索引失效的写法,如
where date(create_time) = '2025-08-01'。 - union all 优于 union,因为后者会多一次去重操作。
-Join 优化:能用 inner join 就不用 left join、right join;大表 join 小表时尽量把小表放在外层驱动。
- SELECT 指定字段,避免
- 架构层面的优化
- 主从复制、读写分离:读多写少的场景下,通过读写分离缓解主库压力。
- 分库分表:当单库数据量或并发过大时,可以做垂直拆分(按业务划分)或水平拆分(按主键 hash/范围拆分)。
事务
事务
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务特性ACID:
- 原子性(Atomicity):
- 事务中的所有操作要么全部完成,要么全部不完成。
- 如果事务在中途失败,已经执行的操作会被回滚(撤销),数据库恢复到事务开始前的状态。
- 好比银行转账:A 扣款成功但 B 未收款时,必须回滚,保证钱不会“消失”。
- 一致性(Consistency):
- 事务执行前后,数据库必须保持一致性状态。
- 例如转账前后,总金额必须保持不变。
- 事务要遵守数据库的完整性约束(主键约束、外键约束、触发器等)。
- 隔离性(Isolation):
- 多个事务并发执行时,一个事务的执行不应受到其他事务的干扰。
- 根据隔离级别不同(如读未提交、读已提交、可重复读、串行化),事务之间能看到的数据也不同。
- 主要是为了解决 脏读、不可重复读、幻读 等并发问题。
- 持久性(Durability):
- 事务一旦提交,它对数据库的修改就是永久性的,即使系统宕机也不会丢失。
- 一般通过 日志(Redo Log) 来保证。
事务并发问题
事务的并发问题主要是指多个事务同时执行时,由于并发操作数据库,可能导致数据不一致或逻辑错误。常见的事务并发问题有以下几种:
- 脏读(Dirty Read)
- 定义:一个事务读取了另一个未提交事务修改过的数据。
- 问题:如果修改数据的事务回滚了,那么读取事务就读到了“无效数据”。
- 例子:
- 事务A:把余额从100改成50(未提交)。
- 事务B:读取余额=50。
- 事务A:回滚,余额恢复100。
- 事务B读到的50就是“脏数据”。
- 不可重复读(Non-Repeatable Read)
- 定义:在同一个事务中,两次读取同一条记录,却得到了不同的结果。
- 问题:数据在事务过程中被其他事务修改了。
- 例子:
- 事务A:查询余额=100。
- 事务B:把余额改成200并提交。
- 事务A:再次查询余额=200。
- 事务A两次查询结果不一致 → 不可重复读。
- 幻读(Phantom Read)
- 定义:在同一个事务中,前后两次执行相同条件的查询,结果集的行数不同。
- 问题:事务期间有其他事务插入或删除了符合条件的新数据。
- 例子:
- 事务A:查询 age > 20 的人数=10。
- 事务B:插入一条 age=25 的数据并提交。
- 事务A:再次查询 age > 20 的人数=11。
- 多了一行“幻影数据”。
- 丢失更新(Lost Update)
- 定义:两个事务同时更新同一条记录,后提交的事务覆盖了先提交事务的结果。
- 例子:
- 事务A:读取余额=100,修改为90(未提交)。
- 事务B:读取余额=100,修改为80,并提交。
- 事务A:提交,余额变成90。
- 事务B的修改结果丢失。
解决方法:隔离级别(ANSI SQL 定义)
数据库通过事务隔离级别来解决上述问题(级别越高,并发性能越低):
- 读未提交(Read Uncommitted)
- 可能出现:脏读、不可重复读、幻读。
- 读已提交(Read Committed)(Oracle 默认)
- 避免了脏读,但可能出现不可重复读、幻读。
- 可重复读(Repeatable Read)(MySQL InnoDB 默认)
- 避免了脏读、不可重复读,但可能出现幻读。
- InnoDB 通过 MVCC + Next-Key Lock 在多数情况下也避免了幻读。
- 可串行化(Serializable)
- 所有并发事务顺序执行,避免所有问题,但性能最差。
redolog与undolog
数据页(Page):
在 InnoDB 存储引擎中,数据是以 页(Page,默认16KB) 为单位存储在磁盘上的,数据页是磁盘管理的最小单元,页里存放的是实际的行记录(Row Data),以及辅助的管理信息。
缓冲池(buffer pool):
- 位置:位于 主内存,是 InnoDB 最重要的内存结构之一。
- 作用:
- 缓存磁盘上的 数据页(page,16KB),避免频繁读磁盘;
- 在事务执行时,先对缓冲池里的数据页进行修改,而不是直接改磁盘;
- 定期通过 checkpoint 将缓冲池中的脏页(dirty page)刷新到磁盘。
redo log(重做日志)
- 如果只改缓存,万一数据库宕机,数据就丢失了,redo log就是为了解决这一问题而诞生的。
- 在修改缓存页的同时,数据库会写一份 redo log(记录“这个页被怎么改了”)。
- redo log 是 顺序写磁盘,比随机写数据页快很多。
- 当事务提交时,redo log 会被持久化(fsync 写入磁盘),即使宕机,只要有 redo log,就能在恢复时“重做”事务的操作,把缓存中的修改同步到磁盘数据页。
👉 这样保证了事务的 持久性(D in ACID)。
undo log(回滚日志)
- 在修改数据时,不光要考虑宕机,还要考虑 事务回滚 的情况。
- 因为事务有原子性(A in ACID),一旦失败,要能撤销之前的操作。
- 所以在修改数据页时,InnoDB 还会生成 undo log,记录这次操作的“逆操作”:
- 如果是 INSERT,undo log 记录对应的 DELETE;
- 如果是 UPDATE,undo log 记录旧值,以便恢复。
- 回滚时就用 undo log,把缓存页恢复到原来的状态。
👉 这样保证了事务的 原子性和一致性(A、C in ACID)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









