







学习视频:这个up的视频讲解的都很好很详细~
self-Attention|自注意力机制 |位置编码 | 理论 + 代码
学习代码(也是该up主的github)
https://github.com/Enzo-MiMan/cv_related_collections
1 注意力机制(Self-Attention和Multi-Head Attention)
1.1 注意力机制中qkv的通俗理解
若把注意力机制的操作比作在淘宝APP中搜索和查询想要购买的商品,那么:

- q: query,在输入框中进行搜索的关键字
- k: key,被查询的标题,title
- v: value,查询的商品价值,重要程度
- 相似度:q和k相乘获得,得到的是查询的q和被查询的k的相似程度
1.2 自注意力机制中的self理解
每个qkv都是同源的,都来源于自己,比如每一个单词代表的token都有自己的qkv值。
想要计算你和别的token的相似度,就可以使用你的q去乘别人的k。

1.3 QKV进一步理解
在具体的注意力机制的操作中,每一个qkv以及相似度、中间得分和最终得分又是如何获取到的呢?

- Q(query): 用于主动与其他 token 计算相似程度
- K(key): 被用于与其他 token 计算相似程度
- V(value): 表示当前token的重要程度
可以看到,Q和K主要就是用来进行token中的相似度的计算,而value则代表着token中的相似程度。
对于上图中的符号
- a 1 a_{1} a1:一个token,它的qkv分别为 q , k 1 , v 1 q,k_{1},v_{1} q,k1,v1
- α n \alpha_{n} αn: q ∗ k n q*k_{n} q∗kn, a 1 和 a n a_{1}和a_{n} a1和an的相似程度
- b 1 b_{1} b1: α 1 ∗ v 1 \alpha_{1}*v_{1} α1∗v1,根据相似程度计算出token1的最终得分
a 1 a_{1} a1和包括自己的每个token都可以进行上述的自注意力机制计算(先算相似程度再算最后得分),然后就可以得到 b 1 − b 4 b_{1}-b_{4} b1−b4 的4个最后得分,根据这4个得分进行排序,就可以获取到和 a 1 a_{1} a1最相关的token是哪个,这就是注意力机制要进行的操作。
1.4 计算过程详解
1.4.1 如何得到QKV

假设a1-a4都是已经embedding之后的1x2的向量,那么a1-a4分别与W1-W3相乘就可以得到各自的QKV,在这里Q和K都是1x2的向量,V是1x3的向量。(由于W的大小不同)

由于W1-W3是相同的,所以QKV的计算是可并行的。
1.4.2 计算步骤

计算流程:
1. 生成 a 1 − a 4 a_{1}-a_{4} a1−a4各自的Q,K,V值(通过同一个W矩阵得到)。
2. 计算 α \alpha α:Q和K的转置相乘后除以K的长度(除以K的长度是防止梯度下降时出现问题)。(得到的4个数值分别为3.536,0.707,3.536,4.243)
3. 对所有的 α \alpha α取softmax,就可以得到和为1的概率值 α 1 , n ′ \alpha_{1,n}' α1,n′。(得到的4个数值分别为0.245,0.015,0.245,0.196)
4. 对 α 1 , n ′ \alpha_{1,n}' α1,n′再乘上各自的value值,得到x,(数值为[0.245,0.245,0.245],[0,0.015,0.015],[0.245,0.49,0.49],[0.992,0,0])
5. 并且把4个token的x相加,最后得到b1,即第一个token和其他token的重要程度。(数值为[1.482,0.75,0.75])
1.5 注意力机制得到的结果含义
Self-Attention得到的结果b1,b2.b3…可以看作是提取出来的features, 这些features可以用于下游任努的训练和推理,
1.6 位置编码

给a1-a4加一个位置编码来表明他们计算的位置关系。

1.7 代码
import torch.nn as nn
import torch
import matplotlib.pyplot as plt
class Self_Attention(nn.Module):
def __init__(self, dim, dk, dv):
super(Self_Attention, self).__init__()
self.scale = dk ** -0.5
self.q = nn.Linear(dim, dk)
self.k = nn.Linear(dim, dk)
self.v = nn.Linear(dim, dv)
def forward(self, x):
q = self.q(x)
k = self.k(x)
v = self.v(x)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = attn @ v
return x
att = Self_Attention(dim=2, dk=2, dv=3)
x = torch.rand((1, 4, 2))
output = att(x)
对于注意力机制,有几个输入就有几个输出。
1.8 多头注意力机制
计算机可能需要执行好几次注意力才能真正观察到图片中有效的信息,因此执行多头注意力,然后把多头注意力的值进行concat融合。
具体可以看下面这篇文章。
注意力机制(Attention)、自注意力机制(Self Attention)和多头注意力(Multi-head Self Attention)机制详解

from math import sqrt
import torch
import torch.nn as nn
class MultiHeadSelfAttention(nn.Module):
def __init__(self, dim_in, d_model, num_heads=3):
super(MultiHeadSelfAttention, self).__init__()
self.dim_in = dim_in
self.d_model = d_model
self.num_heads = num_heads
# 维度必须能被num_head 整除
assert d_model % num_heads == 0, "d_model must be multiple of num_heads"
# 定义线性变换矩阵
self.linear_q = nn.Linear(dim_in, d_model)
self.linear_k = nn.Linear(dim_in, d_model)
self.linear_v = nn.Linear(dim_in, d_model)
self.scale = 1 / sqrt(d_model // num_heads)
# 最后的线性层
self.fc = nn.Linear(d_model, d_model)
def forward(self, x):
# x: tensor of shape (batch, n, dim_in)
batch, n, dim_in = x.shape
assert dim_in == self.dim_in
nh = self.num_heads
dk = self.d_model // nh # dim_k of each head
q = self.linear_q(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
k = self.linear_k(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
v = self.linear_v(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
dist = torch.matmul(q, k.transpose(2, 3)) * self.scale # batch, nh, n, n
dist = torch.softmax(dist, dim=-1) # batch, nh, n, n
att = torch.matmul(dist, v) # batch, nh, n, dv
att = att.transpose(1, 2).reshape(batch, n, self.d_model) # batch, n, dim_v
# 最后通过一个线性层进行变换
output = self.fc(att)
return output
x = torch.rand((1, 4, 2))
multi_head_att = MultiHeadSelfAttention(x.shape[2], 6, 3) # (6, 3)
output = multi_head_att(x)
2 ViT- Vision Transformer
把transformer应用在CV中。

2.1 图像的patches
由于每个像素都做注意力机制的话计算量太大,vit模型把图像拆分成不同的patches输入模型,一般输入的是16x16=224个patches。

2.2 模型结构

- 把图像切分为14x14=196个patches;
- 把patches都embedding成tokens;
- 额外添加一个可学习的class token,用于最后做分类任务;
- 把所有tokens加上位置信息之后,一共是197个tokens;
- 输入transformer encoder中进行训练;重复操作transformer encoder L次;
- 可以得到197个输出结果(和输入个数相等),但是由于做的是分类任务,所以只需要取出class token,接一个MLP Head,得到分类结果。
2.3 核心代码

from math import sqrt
import torch
import torch.nn as nn
class MultiHeadSelfAttention(nn.Module):
def __init__(self, dim_in, d_model, num_heads=3):
super(MultiHeadSelfAttention, self).__init__()
self.dim_in = dim_in
self.d_model = d_model
self.num_heads = num_heads
# 维度必须能被num_head 整除
assert d_model % num_heads == 0, "d_model must be multiple of num_heads"
# 定义线性变换矩阵
self.linear_q = nn.Linear(dim_in, d_model)
self.linear_k = nn.Linear(dim_in, d_model)
self.linear_v = nn.Linear(dim_in, d_model)
self.scale = 1 / sqrt(d_model // num_heads)
# 最后的线性层
self.fc = nn.Linear(d_model, d_model)
def forward(self, x):
# x: tensor of shape (batch, n, dim_in)
batch, n, dim_in = x.shape
assert dim_in == self.dim_in
nh = self.num_heads
dk = self.d_model // nh # dim_k of each head
q = self.linear_q(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
k = self.linear_k(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
v = self.linear_v(x).reshape(batch, n, nh, dk).transpose(1, 2) # (batch, nh, n, dk)
dist = torch.matmul(q, k.transpose(2, 3)) * self.scale # batch, nh, n, n
dist = torch.softmax(dist, dim=-1) # batch, nh, n, n
att = torch.matmul(dist, v) # batch, nh, n, dv
att = att.transpose(1, 2).reshape(batch, n, self.d_model) # batch, n, dim_v
# 最后通过一个线性层进行变换
output = self.fc(att)
return output
x = torch.rand((1, 4, 2))
multi_head_att = MultiHeadSelfAttention(x.shape[2], 6, 3) # (6, 3)
output = multi_head_att(x)
3 DETR
把目标检测视为集合预测的问题,并且简化了目标检测流程,无需设计anchors也无需NMS。

3.1 模型详解
3.1.1 训练部分

- 图像输入DETR模型中,生成100个预测框(100为预设值);
- 这100个预设框与图片中的真实标注框(假设有2个)进行匈牙利匹配算法,从而从这100个里面筛选出和ground truth最接近的2个预测框;
- 将2个ground truth和2个预测框进行损失函数的计算,更新模型;
- 不断更新模型直到训练结束。
3.1.2 测试部分

- 图像输入DETR模型中,生成100个预测框(100为预设值);
- 设置阈值为0.7,大于阈值的预测框进行保留,小于阈值的删除
- 得到最终预测的标注框。
3.1.3 object queries

object queries是decoder的输入部分,是一个可学习的参数,设置为100,就可以输出得到100个预测框。
3.1.4 模型的组成

- CNN backbone: 得到图片整体特征
- encoder: 图片的feature和位置编码一起输入到encoder中,从而可以得到图像的全局信息
- decoder:encoder的输出(图像全局信息)和object queries做自注意力操作,得到预测框集合的输出
- prediction head:预测头,进行预测结果的输出,分别用于预测类别和坐标信息。
3.2 模型详解
整体结构如下所示。

下面直接引用论文里的原文,说的很清楚。
3.2.1 Backbone
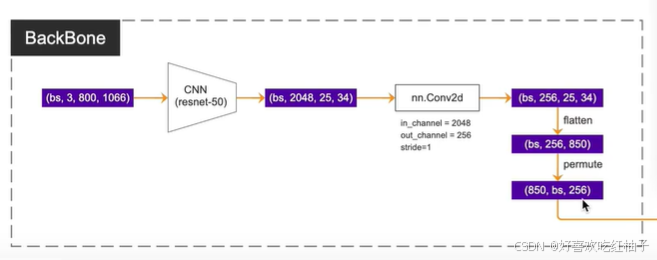
- 输入shape: [bs, channels, h, w]
- CNN-resnet50:[bs, 3, 800, 1066] 经过resnet50的四层残差结构后变为[bs, 2048, 25,34],通道数变为2048,图片大小向上采样32倍;
- nn.Conv2d降低通道数:把通道数从2048降维成256;[bs, 2048, 25,34] -> [bs,256, 25,34]
- flatten:[bs,256, 25,34] -> flatten -> [bs, 256, 850],把h和w相乘变为一个维度;
- permute:[bs,256, 850] -> permute.(2,0,1) -> [850,bs,256]
注:
850就是后面transformer使用的tokens的个数,即一张图片的总的像素个数,256即为一个token的维度。
3.2.2 Encoder
结构

- Image features from the CNN backbone are passed through the transformer encoder, together with spatial positional encoding that are added to queries and keys at every multihead self-attention layer.
从CNN中获取到的图像特征和位置编码相加之后作为encoder部分的Q和K输入,V是没有加位置编码的feature。
QKV进行多头注意力操作,从而得到encoder的输出,即加强过的图像的全局信息
代码
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
注解:
src_mask和src_key_padding_mask两个参数是用来做分割的,不用看
- src:图像特征
- pos: 位置编码
- q=k=src+pos
- value=src
对qkv做自注意力机制,然后根据模型图中的顺序依次完成add,norm等等操作,直到获取到最终的src。
3.2.3 Decoder

- Then, the decoder receives queries (initially set to zero), output positional encoding (object queries), and encoder memory, and produces the final set of predicted class labels and bounding boxes through multiple multihead self-attention and decoder-encoder attention. The first self-attention layer in the first decoder layer can be skipped.
模型的decoder接收:
- queries(初始值为0),shape=(100,256)
- object queries,shape=(100,256)
- -encoder memory(encoder的输出,也是图像的全局信息)
decoder的两个部分的作用如何理解
下部分: 在学习object queries的特征

上部分:结合图像的全局信息和object queries来学习物体的类别和标注框。

代码
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
注解
tgt_key_padding_mask 和 memory_key_padding_mask不管。
- tgt:queries,初始值为0,shape=(100,256)
- memory: encoder的输出,shape=(850,256)
- pos: 位置编码,shape=(850,bs,256)
- query_pos: object queries,shape=(100,256)
对于decoder的第一部分:
- q=k=queries+object queries = tgt+query_pos
- v = queries
对qkv进行注意力机制然后经过一系列add,norm…得到的tgt为第一部分的输出
对于decoder的第二部分:
- q = tgt(第一部分的输出) + object queries
- k = memory+位置编码
- v = memory
对该qkv进行注意力机制然后经过一系列add,norm,FFN…得到最终的tgt,shape为(bs,100,256)
3.2.3 预测头

得到的最终tgt输入到两个全连接层中
- FFN1: 分类层,获得类别,shape = (bs,100,92)
- FFN2:回归层,获得4个坐标, shape = (bs,100,4)
3.3 损失函数



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









