







MapReduce详细工作流程之Map阶段
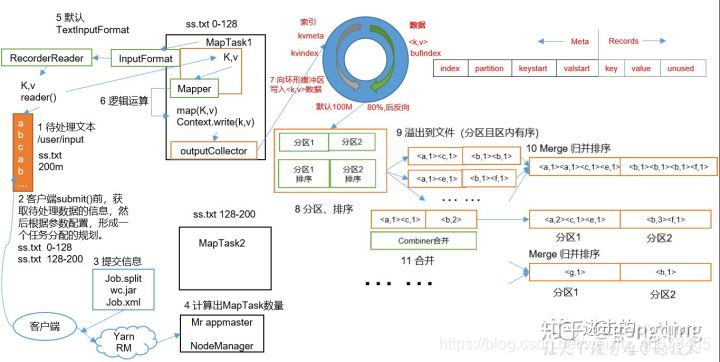
例如图中所示:
- 我们要处理一个200M的文件
- 切片: 在client提交之前,我们需要先将文件按照128M每块进行切片
- 提交: 提交到本地工作环境过Yarn来处理
- 提交时会把每个任务封装成一个job交给Yarn来处理,计算出MapTask数量,每个MapTask并行执行
- MapTask中执行Mapper的map方法,需要k,v作为键值对传递给map方法
- map方法会进行一系列逻辑操作,执行完成后,最后进行写操作
- 需要注意: map方法直接将结果写给reduce的话会制造太多IO操作,失效率变慢,效率降低,因此,map和reduce之间还有一段shuffle操作
- 每个MapTask中的map方法处理完相关逻辑后,先通过outputCollector向环形缓冲区写数据,环形缓冲区分为两部分,一部分是写于文件的元数据信息,另一部分是写入文件的真实信息,环形缓冲区默认大小是100M,当缓存容量达到默认大小的80%时,就会触发溢写(spill)
溢写: 这是一个并行的过程,不会占用map线程资源,整个缓冲区都有溢写比例spill.percent
,默认是0.8,如果map线程过于忙碌,同时溢写线程太慢,map()就会暂停执行去等待溢写完成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









