






人工智能
人工智能就是让机器具备人的思维和意识
人工智能三学派
行为主义:基于控制论,构建感知-动作控制系统
符号主义:基于算术逻辑表达式,求解问题时先描述为表达式再求解表达式
连接主义:仿生学,模仿神经元连接关系,如神经网络
神经网络搭建过程
1.准备数据:采集大量“特征/标签"数据
2.搭建网络:搭建神经网络结构
y=x*w+b代入数据计算出y,这一过程就是前向传播
损失函数定义预测值和结果之间的差距,判断w和b的优劣,loss最小时参数会出现最优值
均方误差MSE(y,y_)=(求和(y-y_)^2)/n,即对每个结果求差的平方的均值,可以作为损失函数
损失函数梯度:函数对各参数求偏导后的向量,函数梯度下下降方向是函数减小方向。沿损失函数梯度下降的方向寻找损失函数的最小值得到最优参数的方法就是梯度下降法。梯度下降的公式中会用到学习率lr进行参数优化,lr设置过小收敛过程会十分缓慢,过大则会跳过最小值甚至来回震荡无法收敛。
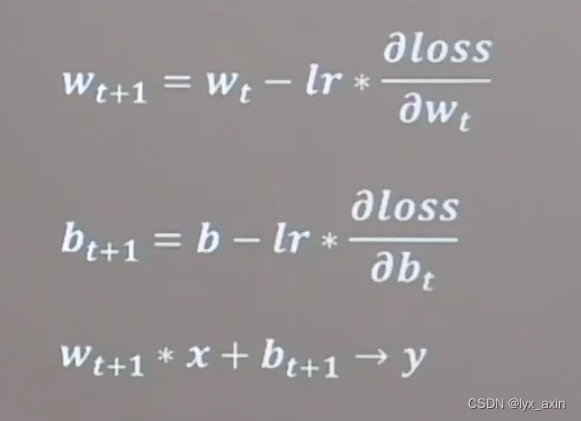
3.优化参数:训练网络获取最佳参数(反向传播)
4.应用网络:将网络保存为模型,输入新数据,输出分类/预测结果
Tensorflow
tensor张量:多维数组(列表) 阶:张量的维度
0阶:标量:单个数字
1阶:向量:v=[1,2,3]
2阶:矩阵:m=[[1,2,3],[4,5,6]]
n阶:张量;t=[[[
tensorflow类型:64位浮点,64位整型,bool类型等等
创建tensor:创建一个张量:tf.constant(张量内容,dtype=数据类型(可选))
直接打印张量会出现张量内容,张量的数据维度(逗号隔开几个位置就是几维张量)以及张量的数据类型等等
可以用tf.convert_to_tensor(a,dtype=tf.int64)将numpy格式转化为tensor格式
tf.zeros(维度) #创建全为0的张量
tf.ones(维度) #创建全为1的张量
tf.fill(维度,指定值) #创建全为指定值的张量
tf.random.normal(维度,mean=均值,stddev=标准差) #生成正态分布的随机数,默认均值为0,标准差为1)
tf.random.normal(shape, mean=0, stddev=1, dtype=None, seed=None) #还有不常用的参数dtype: 输出的类型,默认为tf.float32以及seed: 随机数种子,是一个整数1,2,当设置之后,每次生成的随机数都一样
tf.random.truncated_normal(维度,mean=均值,stddev=标准差)#生成截断式正态分布的随机数,生成的数据都在两倍标准差之内,更集中)
tf.random.uniform(维度,minval=最小值,maxval=最大值) #生成均匀分布随机数
Tensorflow常用函数
tf.cast(张量名,dtype=数据类型) #强制tensor转化为该数据类型
tf.reduce_min(张量名) #计算张量维度上的元素的最小值
tf.reduce_max(张量名) #计算张量维度上的元素的最大值
axis可以控制执行维度axis=0代表跨行,即对列进行操作,axis=1代表跨列,即对行进行操作。如果不指定axis则所有元素参与运算。
tf.Variable(tf.random.normal([2,2],mean=0,stddev=1)) #将变量标记为可训练,标记带训练参数,被标记的变量会在反向传播中记录梯度信息;首先随机生成正态分布随机数(均值为0,标准差为1),再给随机生成的随机数标记为可训练
tensor的四则运算(只有维度相同的张量才可以做四则运算):tf.add(张量1,张量2)加;tf.substract(张量1,张量2)减;tf.multiply(张量1,张量2)乘;tf.devide(张量1,张量2)除;
平方次方与开方:tf.square(
张量名)平方;tf.pow(
张量名,n次方数)次方;tf.sqrt(
张量名)开方
tf.matmul #矩阵乘
标签与特征配对的函数:tf.data.Dataset.from_tensor_slices((输入特征,标签)) numpy和tensor格式都适用
import tensorflow as tf
features = tf.constant([12, 23, 10, 17])
labels = tf.constant([0, 1, 1, 0])
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
print(dataset)
for element in dataset:
print(element)
运行结果如下,可以看到成功配对
<TensorSliceDataset element_spec=(TensorSpec(shape=(), dtype=tf.int32, name=None), TensorSpec(shape=(), dtype=tf.int32, name=None))>
(<tf.Tensor: shape=(), dtype=int32, numpy=12>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
(<tf.Tensor: shape=(), dtype=int32, numpy=23>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: shape=(), dtype=int32, numpy=10>, <tf.Tensor: shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: shape=(), dtype=int32, numpy=17>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
求张量的梯度:tf.GradientTape.gradient(函数,对谁求导),配合Variable函数可以实现损失函数loss对参数w的求导数计算
枚举函数enumerate(列表名/元组名/字符串名):遍历列表/元组/字符串的元素,使用方式:
for index,element in enumerate(seq):
print(index,element)
独热码:在分类问题中常用独热码作为标签标记类别1表示是,0表示非,举例:

此时独热码为010
tf.onr_hot() #将待转换数据转换为独热码的形式输出:tf.one_hot(待转换数据,depth=几分类)
import tensorflow as tf
classes = 3
labels = tf.constant([1,0,2]) # 输入元素的最小值为0,最大值为2
output = tf.one_hot(labels,depth=classes)
print(output)
结果如下:
tf.Tensor(
[[0. 1. 0.]
[1. 0. 0.]
[0. 0. 1.]], shape=(3, 3), dtype=float32)
在通过函数得到结果之后,需要将输出转化为符合概率分布的结果,因此用到tf.softmax(x)函数,该函数核心为如下函数,用完之后的结果和为1.
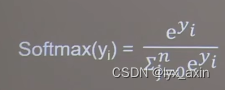
import tensorflow as tf
y = tf.constant([1.01,2.01,-0.66])
y_pro =tf.nn.softmax(y)
print("After softmax , y_pro is :",y_pro)
结果如下:
After softmax , y_pro is : tf.Tensor([0.25598174 0.6958304 0.0481878 ], shape=(3,), dtype=float32)
assign_sub()函数:用于参数自更新
更新参数的返回值并返回
调用assign_sub前,先使用tf.Variable定义变量w为可训练(可自更新)
w.assign_sub(w要自减的大小)
import tensorflow as tf
w = tf.Variable(4)
w.assign_sub(1) # w-=1 即是 w=w-1
print(w)
结果如下:
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=3>
返回张量沿指定维度最大值的索引:tf.argmax(张量名,axis=操作轴)
axis=0返回每一列的最大值的索引,针对行而言
axis=1返回每一行的最大值的索引,针对列而言
import tensorflow as tf
import numpy as np
test = np.array([[1,2,3],[2,3,4],[5,4,3],[8,7,2]])
print(test)
print(tf.argmax(test,axis=0))
print(tf.argmax(test,axis=1))
结果如下
[[1 2 3]
[2 3 4]
[5 4 3]
[8 7 2]]
tf.Tensor([3 3 1], shape=(3,), dtype=int64)
tf.Tensor([2 2 0 0], shape=(4,), dtype=int64)
以上为人工智能的学习笔记,内容来自b站北京大学曹健老师的课程,如有错误,敬请指正!















 5221
5221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









