







目录
1. 数据库简介
1.1 学习数据库的原因
- 测试理论、测试对象、源程序、目标程序、各种文档和数据
- 大部分所有软件的数据都存储在数据库中
- 更深层次的定位bug
- 如从注册界面注册成功的用户,无法登录
- 如用户注册登录都没有问题
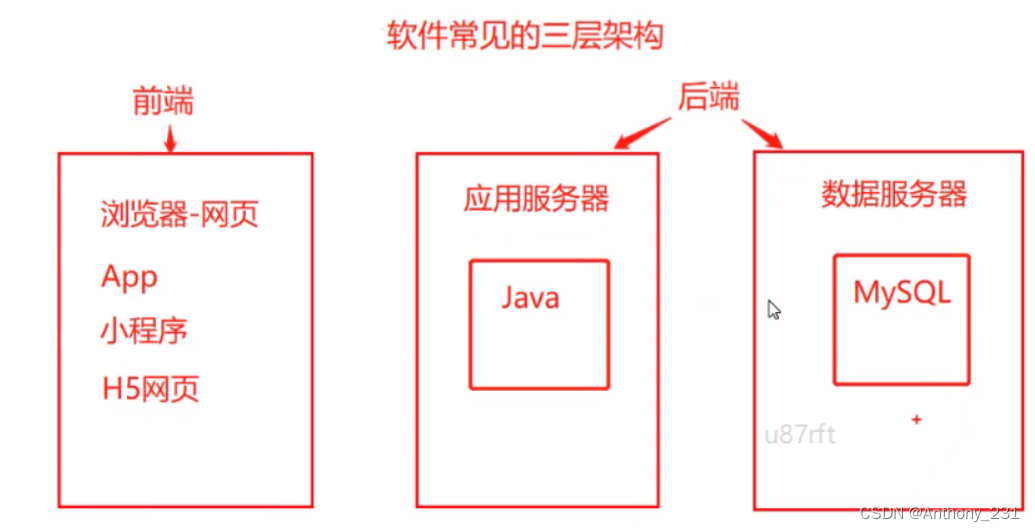
1.2. 数据库概念
数据库(DB):英文时DataBase,简单地说就是存储数据的地方
- DB是DBMS(DataBase Managment System - 数据库管理系统)所创建的管理数据的容器
表(Table): 数据库中存储数据的基本单位,数据按照分类存储到不同的表中
1.3 关系型数据库
概念: 由多张有关联的表组成的数据库
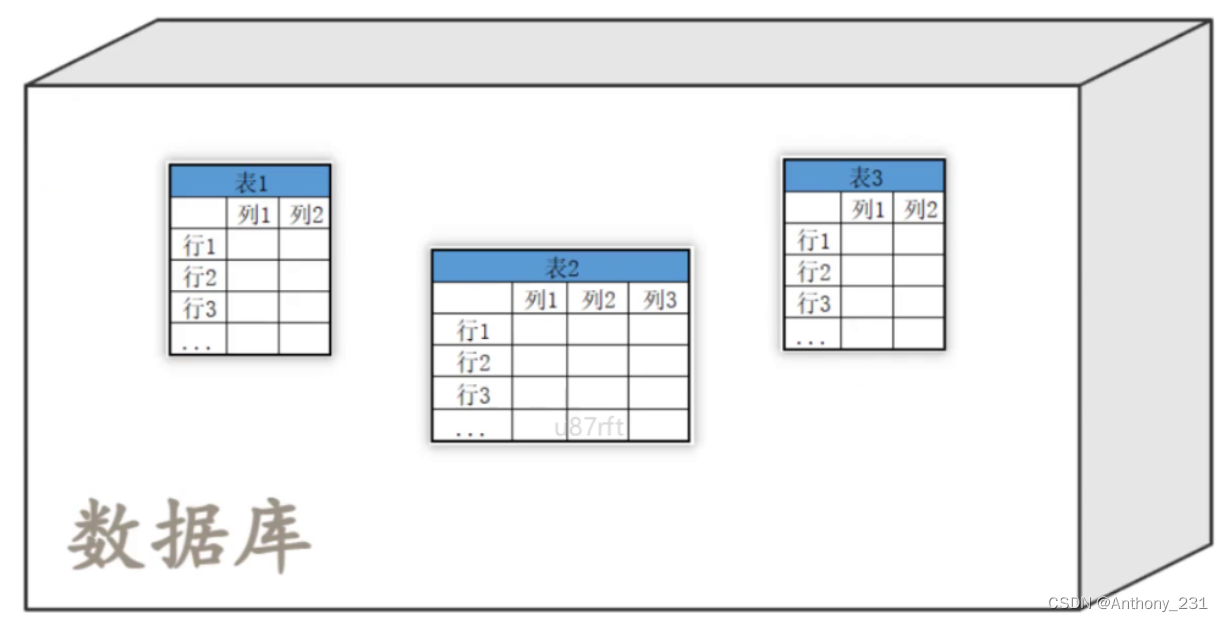
核心元素
- 数据库,表的集合,一个数据中可以有多张表
- 表:有行和列组成的二维表格
- 行:记录(一条记录)
- 列:字段
关系型数据库主要产品:
- Oracle:收费,在大型项目中使用,如:银行,电信等项目
- MySQL:免费,互联网时代使用最广泛的关系型数据库
- SQL Server:微软,微软项目常用
- SQLite:轻量级数据库,主要应用在移动平台
1.4 SQL
- 定义:英文是Structured Query Language,结构化查询语言
- SQL是一门语言,专门用来操作关系型数据库,可以操作Oracle,MySQL,SQL Server,SQLLite等
- SQL语言不区分大小写
1.5 使用命令行连接数据等基本命令
-
本地登录:
- 打开命令行界面:WIN+R,输入cmd并回车
- 在命令行输入:mysql -uroot -p 并回车
- 输入登录密码
-
远程连接
MySQL出于安全考虑,默认关闭远程连接权限,需要提前打开
常用命令
- 显示所有的数据库:show databases;
- 使用指定的数据库:use 数据库名字;
- 查看指定的数据库所有表:show tables;
2. SQL基础
2.1 数据库常用类型
- 整数(int)
- 有符号范围(-2147483648,2147483647)
- 无符号范围(0,4294967295),如: int unsigned,代表设置一个无符号的整数
- 小整数(tinyint)
- 有符号范围(-128,127)
- 无符号范围(0,255),如: tinyint unsigned, 代表设置一个无符号的小整数
- 小数(decimal)
- 如 decimal(5,2),表示共存5位数,小数位占2位(不能超过2位),整数位占3位
- 字符串(varchar)
- 如 varchar(3),表示最多存3个字符,一个中文或者字母都占一个字符
- 日期时间(datetime)
- 范围(1000-01-0100:00:00~9999-12-31 23:59:59),如:'2020-01-01 12:29:59
- 文本(text)
- 用于存储一段无法确定长度的文本内容
2.2 创建表
语法格式
create table 表名(
字段名 数据类型,
字段名 数据类型
)
创建单个字段的表
# 创建表A,字段要求:name(姓名),数据类型:varchar(字符长度),长度为10
create table A(
name varchar(10)
);
创建多个字段的表
# 创建表B,字段要求:id(主键),name(姓名),age(年龄)
create table B(
id int,
name varchar(10),
age tinyint
);
2.2 插入数据
语法格式
insert into 表名(字段名, 字段名, 字段名) values(字段值, 字段值, 字段值);
insert into 表名 values(字段值, 字段值, 字段值);;
添加一条数据
#
# 选择test数据库
use test;
# 向B表添加一条数据
insert into B(id, name, age) values(1, '孙悟空', 20);
添加多条数据
#
# 选择test数据库
use test;
# 向B表添加三条数据
insert into B(id, name, age) values(2, '小安', 18),
(3, '张三', 30),
(4, '李四', 23);
2.3 更新数据
语法格式
update 表名 set 列名 = 值1, 列名 = 值1, 列名 = 值1 where id = 条件;
更新数据,没有where条件时
# 选择test数据库
use test;
# 修改表B,所有人的年龄改为66
update B set age = 66
更新数据,有where条件时
# 选择test数据库
use test;
# 更新B表,将姓名为八戒,年龄改为18
update B set name = '八戒',age = 18 where id = 2;
2.4查询数据
语法格式
select * from 表名;
查询所有字段的数据
# 选择test数据库
use test;
# 在B表查询所有条件的数据
select * from B;
查询指定的字段数据
# 选择test数据库
use test;
# 根据不同条件查询数据
select name,age from B;
2.5 删除数据
语法格式
delete from 表名 where 条件;
删除表中id为1的数据
# 选择test数据库
use test;
# 删除表中id为1的数据
delelte from B where = 1;
删除表B的所有数据
# 选择test数据库
use test;
# 删除表B的所有数据
delelte from B;
2.6 truncate删除数据
语法:
truncate table 表名;
truncate删除表数据,会保留表结构
2.7 drop删除表
语法一:
drop table 表名;
删除表数据和表结构
语法二:
drop table if exist B 表名;
2.8 字段约束
语法格式
create table 表名(
字段名 数据类型 约束,
字段名 数据类型 约束
)
举例
# 创建表B,字段要求:id(主键),name(姓名),age(年龄)
create table B(
id int primary key,
name varchar(10),
age tinyint
);
常用约束
- 主键primary key,表示值时唯一的,不可以重复,auto_increment代表自动增长
- 非空约束not null,此字段不允许为空,
- 默认值default,当不填写此字段时,会使用这个默认值
# 创建表B,字段要求:id(主键),name(姓名),age(年龄)
create table B(
id int primary key auto_increment,
name varchar(10) not null,
age tinyint unsiged default 18
);
3. 条件查询
3.1 数据准备
# 插入数据
-- 创建 student 表
CREATE TABLE student (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
age INT,
gender ENUM('男', '女'),
grade VARCHAR(10),
major VARCHAR(50),
city VARCHAR(50)
);
-- 插入数据
INSERT INTO student (name, age, gender, grade, major, city) VALUES
('张三', 20, '女', '大二', '计算机科学', '北京'),
('李四', 22, '男', '大四', '工程学', '上海'),
('王五', 19, '男', '大一', '生物学', '广州'),
('赵六', 21, '女', '大三', '心理学', '深圳'),
('小红', 20, '女', '大二', '英语', '南京'),
('小明', 23, '男', '大四', '数学', '成都'),
('小丽', 20, '女', '大二', '历史学', '武汉'),
('小华', 22, '男', '大四', '经济学', '重庆'),
('小美', 21, '女', '大三', '化学', '天津'),
('小刚', 19, '男', '大一', '物理学', '杭州'),
('小强', 20, '男', '大二', '政治学', '西安'),
('小雨', 22, '女', '大四', '社会学', '青岛'),
('小莉', 21, '女', '大三', '人类学', '郑州'),
('小龙', 20, '男', '大二', '地理学', '长沙'),
('小梅', 19, '女', '大一', '艺术', '济南'),
('小菲', 21, '男', '大三', '音乐学', '南昌'),
('小琪', 20, '女', '大二', '舞蹈', '合肥'),
('小健', 22, '男', '大四', '戏剧', '太原'),
('小萱', 19, '女', '大一', '电影学', '长春'),
('小刘', 21, '男', '大三', '哲学', '石家庄');
3.2 where
语法:
select * from 表名 where 条件;
举例
# 1. 查询student表中的id为10的数据
select * from student where id = 10;
# 2. 查询product表中的名字(name)是小龙,年龄(age)是20的,城市是(city)是长沙的
select name,age,city from student where name = '小龙' and age = 20 and city = '长沙';
补充:
where关键字也可以再update和delete语句中使用
生活中的软件需要查询数据的场景
- 购物类型的软件: 搜商品,看详情,看评价,看物流信息,看各种订单
- 学生管理系统: 搜学生,看班级信息,看成绩
- 聊天系统: 搜附近,搜在线,看朋友圈,看对方详情,看聊天记录
工作中用到 where 的场景案例
- 搜商品, where 在商品名或者商品介绍中包含搜索的关键字
- 看详情,where id 为 具体某一个商品
- 搜学生,where id或者是姓名 为具体某一个学生
- 搜附近,where 距离 小于 多少公里
3.3 比较运算符
语法:
select * from 表名 where 条件 > 条件;
举例
# 1. 查询student表中的age为20的数据
select * from student where age = 20;
# 2. 查询student表中的age小于20的数据
select * from student where age < 20;
# 3. 查询student表中的age大于21的数据
select * from student where age > 21;
# 4. 查询student表中的age为大于等于23的数据
select * from student where age >= 23;
# 5. 查询student表中的age小于等于19的数据
select * from student where age <= 19;
# 6. 查询student表中的age不等于19的数据
select * from student where age != 22;
3.4 逻辑运算符
- 与
- 或
- 非
语法:
select * from 表名 where 条件 > 条件;
举例
# 1. 查询age年龄小于20,并且gender性别是女的同学记录
select * from student where age < 20 and gender = '女';
# 2. 查询gender性别为女或者grade为大二的的学生记录
select * from student where gender = '女' or grade = '大二';
# 3. 查询city城市是非西安的学生记录
select * from student where city != '西安';
select * from student where not city = '西安';
3.5 模糊查询
生活中的场景
-
精确查询 (等于)
- 开车出入停车场,车牌号经过精确查询后进行缴费
- 去药店买药,报精确会员手机号,以便会员积分
-
模糊查询 (包含)
- 百度,搜索关键字
- 淘宝,根据关键字搜索商品
使用
like实现模糊查询
- %代表任意多个字符
- _代表任意一个字符
语法:
# %代表任意多个字符
select * from 表名 where 条件 like '%关键字';
# _代表任意一个字符
select * from 表名 where 条件 like '_关键字';
举例
# 1. 查询name以“小”开头的学生数据
select * from student where name like '小%';
select * from student where name like '小_';
# 2. 查询name以“六”结尾的学生数据
select * from student where name like '%六';
select * from student where name like '_六';
# 3. 查询name中含有“小”的学生数据
select * from student where name like '%小%';
3.6 范围查询
- 在连续的范围内进行查找
- 再非连续的范围内进行查找
举例
# 1. 查询age年龄为19-23的学生数据
select * from student where age > 19 and age < 23;
select * from student where age between 19 and 23;(包含边界)
# 2. 查询city城市是“西安”或“北京”的学生数据
select * from student where city = '西安' or city = '北京';
select * from student where city in("西安","北京");
# 3. 查询name中含有“小”的学生数据
select * from student where name like '%小%';
3.7 Null
# 数据准备
insert into student(`id`,`name`,`city`) values(21,'赵云','上海');
# 1. 查询gender性别为空的学生记录
select * from student where gender is null;
# 2. 查询gender性别为非空的学生记录
select * from student where gender is not null;
注意
- null再SQL中代表空,不是0,也不是”“,而是什么都没有
- is null判断为空
- is not null判断非空
- null不能用比较运算符判断
4. 别名
表的别名
# 通过as给表格student起一个别名
select * from student as s
# as可以省略
select * from student s
字段的别名
# 通过as给字段起一个别名
select
id as ID,
`name` as 姓名,
age as 年龄,
gender as 性别,
grade as 班级,
major as 专业,
city as 城市
from
student;
5. 排序
升序语法: 从小到大,默认
select * from 表名 order by 字段 asc;
降序语法: 从大到小
select * from 表名 order by 字段 desc;
单字段排序
# 1. 查询student学生数据,按年龄age从小到大排序
select * from student order by age ASC;
# 2. 查询student学生数据,按年龄age从大到小排序
select * from student order by age deSC;
多字段排序
# 3. 查询student学生数据,按年龄age从大到小排序
# 当年龄相同时,按ID从小到大排序
select
*
from
student
order by
age ASC,
id ASC;
当一个select语句出现了where和order by
语法:
select * from 表名 where 条件 order by 字段 asc;
案例
# 4. 查询student所有男学生数据,按班级升序,班级相同时,再按年龄升序
select
*
from
student
where
gender = '男'
order by
grade, age;
6. 聚合函数
6.1 count计数
语法:
select count(字段) as 别名 from 表名;
举例:
# 1. 查询student学生总数
select
count(*) as 学生总数
from
student;
# 2. 根据ID查询student学生总数
select
count(id) as 学生总数
from
student;
# 3. 查询student女学生总数
select
count(id) as 女学生总数
from
student
where
gender = '女';
count(*)和count(id)的区别
- 查询结果是一样的
- 效率不同
- 在大量的数据时,count(id)效率更快
6.2 去重(distinct)关键字
语法:
select count(字段) as 别名 from 表名;
举例:
# 1. 查询student的班级去重
select
distinct grade
from
student;
# 2. 查询student的班级总数
select
count(distinct grade)
from
student;
6.3 最大值max()
语法:
select max(字段) as 别名 from 表名;
举例:
# 1. 查询student的年龄最大
select
max(age)
from
student;
# 2. 查询student的女生的最大年龄
select
max(age)
from
student
where
gender = '女';
6.4 最小值min()
语法:
select min(字段) as 别名 from 表名;
举例:
# 1. 查询student的年龄最小
select
min(age)
from
student;
# 2. 查询student的女生的最小年龄
select
min(age)
from
student
where
gender = '女';
6.5 求和 sum()
语法:
select sum(字段) as 别名 from 表名;
举例:
# 1. 查询student的年龄和
select
sum(age)
from
student;
# 2. 查询student的女生年龄和
select
sum(age)
from
student
where
gender = '女';
6.5 平均值 avg()
语法:
select avg(字段) as 别名 from 表名;
举例:
# 1. 查询student的平均年龄
select
avg(age)
from
student;
# 2. 查询student的女生平均年龄
select
avg(age)
from
student
where
gender = '女';
如果值中含有null,null是不参与计算平均值的
聚合函数不能用到where的条件
7. 数据分组
7.1 分组的实现
分组的实现
- 分组一般需要配合聚合函数来使用
- group by 字段名
- 分组时,先条件再分组
格式
select 聚合函数 from 表名 group by 字段;
select 字段,聚合函数 from 表名 group by 字段;
案例
# 1. 按不同的性别分组,来统计student中男女的总数
select
gender, count(*)
from
student
group by
gender;
# 2. 按不同的性别分组,来统计student中大学的男女的总数
select
gender, count(id) as 3班男女总数
from
student
where
grade = '大学'
group by
gender;
7.2 多字段分组的实现
格式
select
字段1, 字段2, 聚合函数
from
表名
group by
字段1, 字段2;
注意: 按字段的先后顺序,select后的顺序必须与group by顺序一致
案例1: 按不同的班级分组,不同性别分组,来统计student中男女的总数
# 1. 按不同的班级分组,不同性别分组,来统计student中男女的总数
select
grade, gender, count(id)
from
student
group by
grade, gender;
案例2: 按不同的班级分组,不同性别分组,来统计student中男女的总数并按年级升序排序
# 2. 按不同的班级分组,不同性别分组,来统计student中男女的总数并按年级升序排序
select
grade, gender, count(id)
from
student
group by
grade, gender
order by
grade asc;
案例3: 按不同的班级分组,不同地区分组,来统计student中男女的总数并按年级升序排序
# 3. 按不同的班级分组,不同地区分组,来统计student中男女的总数并按年级升序排序
select
grade, city, count(id)
from
student
group by
grade, city
order by
grade;
案例4: 按不同的班级分组,不同性别分组,来统计student中成年的男女的总数并按年级升序排序
# 4. 按不同的班级分组,不同性别分组,来统计student中成年的男女的总数并按年级升序排序
select
grade, gender, count(*)
from
student
where
age > 18
group by
grade, gender
order by
grade;
7.3 分组后的数据筛查
格式
select
字段, 聚合函数
from
表名
group by
字段
having
字段 = 字段值;
案例1:查询student表的男生总数[先统计,再筛选]效率低
# 1. 查询student表的男生总数[先统计,再筛选]效率低
select
gender, count(*)
from
student
where
gender = '男';
案例2: 查询student表的男生总数[先分组,再筛选,再统计]效率高
# 2. 查询student表的男生总数[先分组,再筛选,再统计]效率高
select
gender, count(*)
from
student
group by
gender
having
gender = '男';
案例3: 查询student表,统计年级人数大于3人的班级
# 3. 查询student表,统计年级人数大于3人的班级
select
grade, count(*)
from
student
group by
grade
having
grade > 3;
8. 分页
-
limit 开始行,总数
- 例如:limit 0, 3,表示从第一行开始,显示3行
- 如果是从第一行开始,那么开始行的0可以省略,就limit 0,3可以写成limit 3
# 1. 查询student表前三条数据 select * from student limit 0, 3; # 2. 查询从第四条开始的3条数据(每页3条数据,第二页) select * from student limit 3, 3; # 3. 按照每页四条数据,展示两页 select * from student limit 4,4;
注意:limit总是出现在select语句最后
9. 连接查询
9.1 数据准备
创建表
-- 创建课程表
CREATE TABLE course (
c_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '课程ID',
course_name VARCHAR(100) NOT NULL COMMENT '课程名称',
teacher_name VARCHAR(100) NOT NULL COMMENT '任课教师',
schedule VARCHAR(100) NOT NULL COMMENT '上课时间表',
room_number VARCHAR(20) COMMENT '上课教室编号',
UNIQUE KEY(course_name)
) COMMENT='课程信息表';
-- 创建学生表
CREATE TABLE student (
s_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '学生ID',
student_name VARCHAR(100) NOT NULL COMMENT '学生姓名',
grade INT NOT NULL COMMENT '年级',
class_name VARCHAR(10) NOT NULL COMMENT '班级名称',
gender ENUM('男', '女') NOT NULL COMMENT '性别',
date_of_birth DATE COMMENT '出生日期',
UNIQUE KEY(student_name, grade, class_name)
) COMMENT='学生信息表';
-- 创建成绩表
CREATE TABLE score (
sc_id INT AUTO_INCREMENT PRIMARY KEY COMMENT '成绩ID',
s_id INT COMMENT '学生ID',
c_id INT COMMENT '课程ID',
score DECIMAL(5,2) COMMENT '成绩',
FOREIGN KEY (s_id) REFERENCES student(s_id),
FOREIGN KEY (c_id) REFERENCES course(c_id),
UNIQUE KEY(s_id, c_id)
) COMMENT='成绩信息表';
添加数据
-- 添加课程信息
INSERT INTO course (course_name, teacher_name, schedule, room_number) VALUES
('计算机科学导论', '张老师', '周一 8:00-10:00', 'A101'),
('数据结构与算法', '王老师', '周二 10:00-12:00', 'B201'),
('数据库系统原理', '李老师', '周三 14:00-16:00', 'C301'),
('网络编程', '赵老师', '周四 13:00-15:00', 'D401'),
('人工智能导论', '刘老师', '周五 9:00-11:00', 'E501'),
('软件工程', '孙老师', '周一 14:00-16:00', 'F601'),
('操作系统', '钱老师', '周二 8:00-10:00', 'G701'),
('编译原理', '周老师', '周三 10:00-12:00', 'H801'),
('计算机网络', '吴老师', '周四 15:00-17:00', 'I901'),
('机器学习', '冯老师', '周五 14:00-16:00', 'J1001'),
('数字图像处理', '韩老师', '周一 10:00-12:00', 'K1101'),
('物联网技术', '马老师', '周二 13:00-15:00', 'L1201'),
('大数据分析', '高老师', '周三 16:00-18:00', 'M1301'),
('区块链技术', '肖老师', '周四 9:00-11:00', 'N1401'),
('云计算', '张老师', '周五 11:00-13:00', 'O1501'),
('嵌入式系统', '王老师', '周一 15:00-17:00', 'P1601'),
('信息安全', '李老师', '周二 9:00-11:00', 'Q1701'),
('软件测试', '赵老师', '周三 11:00-13:00', 'R1801'),
('并行计算', '刘老师', '周四 14:00-16:00', 'S1901'),
('计算机图形学', '孙老师', '周五 10:00-12:00', 'T2001');
-- 添加学生信息
INSERT INTO student (student_name, grade, class_name, gender, date_of_birth) VALUES
('张三', 1, '计算机科学与技术1班', '男', '2000-01-05'),
('李四', 2, '计算机科学与技术2班', '男', '1999-08-15'),
('王五', 3, '计算机科学与技术3班', '女', '2001-03-20'),
('赵六', 1, '软件工程1班', '女', '2000-11-10'),
('钱七', 2, '软件工程2班', '男', '1999-04-25'),
('孙八', 3, '软件工程3班', '男', '2001-07-30'),
('周九', 1, '信息安全1班', '女', '2000-02-12'),
('吴十', 2, '信息安全2班', '男', '1999-09-18'),
('郑十一', 3, '信息安全3班', '男', '2001-05-08'),
('王十二', 1, '大数据技术1班', '女', '2000-10-02'),
('赵十三', 2, '大数据技术2班', '女', '1999-01-22'),
('孙十四', 3, '大数据技术3班', '男', '2001-06-14'),
('李十五', 1, '人工智能1班', '男', '2000-03-25'),
('周十六', 2, '人工智能2班', '女', '1999-10-11'),
('吴十七', 3, '人工智能3班', '女', '2001-08-05'),
('郑十八', 1, '网络安全1班', '男', '2000-04-15'),
('王十九', 2, '网络安全2班', '男', '1999-11-30'),
('张二十', 3, '网络安全3班', '女', '2001-09-20'),
('李二十一', 1, '软件测试1班', '女', '2000-05-28'),
('赵二十二', 2, '软件测试2班', '男', '1999-12-10');
-- 添加成绩信息
INSERT INTO score (s_id, c_id, score) VALUES
(1, 1, 85.5),
(2, 2, 78.0),
(3, 3, 90.2),
(4, 4, 92.7),
(5, 5, 88.9),
(6, 6, 75.3),
(7, 7, 81.8),
(8, 8, 87.6),
(9, 9, 79.4),
(10, 10, 83.2),
(11, 11, 91.0),
(12, 12, 84.6),
(13, 13, 77.1),
(14, 14, 89.3),
(15, 15, 92.5),
(16, 16, 86.0),
(17, 17, 80.7),
(18, 18, 88.2),
(19, 19, 82.9),
(20, 20, 90.8);
9.2 内连接
格式
select * from 表1 inner join 表2 on 表2.字段 = 表1.字段;
select * from 表1 inner join 表2 on 表2.id = 表1.id;
内连接最重要的是:找对两张表要关联的字段
案例1:在学生表与课程表,查询学生id与课程id对应的数据[即查询该学生选了哪些课]
# 1. 在学生表与课程表,查询学生id与课程id对应的数据[即查询该学生选了哪些课]
select
*
from
student as s
inner join
course as c
on
s.s_id = c.c_id;
# 2. students表与courses表的内连接,只显示student_name, course_id, score
select
s.student_name as 学生姓名,
sc.c_id as 课程ID,
sc.score as 成绩
from
student as s
inner join
score as sc
on
s.s_id = sc.sc_id;
带有where的内连接
# 1. 查询孙八的成绩,显示姓名,课程号,成绩
select
s.student_name 姓名,
sc.c_id 课程号,
sc.score 成绩
from
student as s
inner join
score as sc
where
s.student_name = '孙八';
9.2.1 多表内连接
# 1. 查询学生选课成绩,显示姓名,课程号,课程,成绩
select
s.student_name 姓名,
c.course_name 课程名,
sc.score 成绩
from
student as s
inner join
score as sc
on
sc.sc_id = s.s_id
inner join
course as c
on
sc.sc_id = c.c_id;
带有where的多表内连接
# 1. 查询吴十的选课成绩,显示姓名,课程,成绩
select
s.student_name 姓名,
c.course_name 课程名,
sc.score 成绩
from
student as s
inner join
score as sc
on
sc.sc_id = s.s_id
inner join
course as c
on
sc.sc_id = c.c_id
where
s.student_name = '吴十';
写SQL三步法

# 1. 查询所有学生的“计算机网络”的选课成绩,显示姓名,课程,成绩
select
s.student_name 学生姓名,
c.course_name 课程,
sc.score 成绩
from
student as s
inner join score as sc on s.s_id = sc.sc_id
inner join course as c on sc.sc_id = c.c_id
where
c.course_name = '计算机网络';
# 2. 查询成绩最高的学生信息,显示姓名,课程,成绩
select
s.student_name 学生姓名,
c.course_name 课程,
sc.score 最高成绩
from
student as s
inner join score as sc on s.s_id = sc.sc_id
inner join course as c on c.c_id = sc.sc_id
where
s.gender = '男'
order by
sc.score desc
limit 1
9.3 外连接
9.3.1 左连接
格式
select
*
from
表名1
left join 表名2 on 表名1.字段 = 表名2.字段;
案例1: 查询所有的学生信息和成绩,包括没有成绩的学生
# 1. 查询所有的学生信息和成绩,包括没有成绩的学生
select
*
from
student s
left join score sc on s.s_id = sc.sc_id;
select
*
from
student s
inner join score sc on s.s_id = sc.sc_id;
9.3.2 右连接
格式
select
*
from
表名1
right join 表名2 on 表名1.字段 = 表名2.字段;
案例1: 查询所有的课程信息,包括没有成绩的学生
# 1. 查询所有的课程信息,包括没有成绩的学生
select
*
from
score sc
right join course c on c.c_id = sc.sc_id;
10. 自关联
10.1 数据准备
创建表
-- 创建行政区划表
CREATE TABLE district (
id INT PRIMARY KEY AUTO_INCREMENT, -- 区划ID
name VARCHAR(100) NOT NULL, -- 区划名称
pid INT, -- 父级区划ID
-- 添加外键约束
FOREIGN KEY (pid) REFERENCES district(id)
);
添加数据
-- 添加15条行政区划数据
INSERT INTO district (name, pid) VALUES ('北京市', NULL); -- 北京市,作为省级,pid为NULL
INSERT INTO district (name, pid) VALUES ('东城区', 1); -- 北京市下的东城区,pid指向北京市的ID
INSERT INTO district (name, pid) VALUES ('西城区', 1); -- 北京市下的西城区,pid指向北京市的ID
INSERT INTO district (name, pid) VALUES ('海淀区', 1); -- 北京市下的海淀区,pid指向北京市的ID
INSERT INTO district (name, pid) VALUES ('天津市', NULL); -- 天津市,作为省级,pid为NULL
INSERT INTO district (name, pid) VALUES ('和平区', 5); -- 天津市下的和平区,pid指向天津市的ID
INSERT INTO district (name, pid) VALUES ('河东区', 5); -- 天津市下的河东区,pid指向天津市的ID
INSERT INTO district (name, pid) VALUES ('河西区', 5); -- 天津市下的河西区,pid指向天津市的ID
INSERT INTO district (name, pid) VALUES ('上海市', NULL); -- 上海市,作为省级,pid为NULL
INSERT INTO district (name, pid) VALUES ('黄浦区', 9); -- 上海市下的黄浦区,pid指向上海市的ID
INSERT INTO district (name, pid) VALUES ('徐汇区', 9); -- 上海市下的徐汇区,pid指向上海市的ID
INSERT INTO district (name, pid) VALUES ('长宁区', 9); -- 上海市下的长宁区,pid指向上海市的ID
INSERT INTO district (name, pid) VALUES ('重庆市', NULL); -- 重庆市,作为省级,pid为NULL
INSERT INTO district (name, pid) VALUES ('渝中区', 13); -- 重庆市下的渝中区,pid指向重庆市的ID
INSERT INTO district (name, pid) VALUES ('大渡口区', 13); -- 重庆市下的大渡口区,pid指向重庆市的ID
INSERT INTO district (name, pid) VALUES ('江北区', 13); -- 重庆市下的江北区,pid指向重庆市的ID
# 1. 查询有什么市
select * from district where pid is null;
# 2. 查询有什么市,有多少个市
select count(*) as 市总数 from district where pid is null;
10.2 自关联案例
注意: 自关联是在同一张表做连接查询
- 一定要找到同一张表可关联的不同字段
格式
select
表1.字段1,
表1.字段2
from
表1 inner join表2 on 表1.字段1 = 表1.字段2
where
条件;
案例
# 1. 查询上海市的所有区
select
d1.`name` 市,
d2.`name` 区
from
district d1 inner join district d2 on d1.id = d2.pid
where
d1.`name` = '上海市';
补充: 自关联是一种关联的思路,并不属于关联方式
10.3 自关联的使用场景
在同一张表中,有父子关系的字段就有可能需要使用
- 例如:行政区划分表
- 例如:电商系统中的商品分类表
11. 子查询
子查询是嵌套在主查询里的
格式
select
*
from
表名
where
条件 > (select 字段 from 表名);
案例
# 1. 查询大于平均年龄的学生记录
# ①查询平均年龄的学生
select
avg(age) as 平均年龄 、
from
student;
# ②查询大于平均年龄的学生记录
select
*
from
student
where
age > (select avg(age) as 平均年龄 from student);
# 2. 在上一个的查询结果中,把班级名称是“网络安全1班”的数据找出来
select * from
(select * from student where age > (select avg(age) as 平均年龄 from student)) s
where class_name = '网络安全1班';
12. 存储过程
定义: 存储在数据库服务端的SQL语句
作用:
- 批处理
- 重复使用
# 1. 创建用户表,字段:id,username,phone,pwd
create table user(
id int primary key auto_increment,
username varchar(20) not null,
phone varchar(20) not null,
pwd varchar(20) not null
);
# 2. 创建数据存储d,录入1000条数据
create procedure d ()
begin -- 存储过程开始
declare i int default 1; -- 定义变量i,初始值为1
while i < 1000
do
insert into user values(i, concat('赵四', i), 13000000000+i, '123456');
set i = i + 1;
end while;
end -- 存储过程结束
# 3. 调用存储过程
call d();
# 4. 删除存储过程
drop procedure d;
13. 非关系型数据库
非关系型数据库,也称 NoSql, 全称为 Not Only SQL,是对关系型数据库的一种补充
非关系型数据库的主要产品
- Redis
- 优缺点: 内存数据库,读写性能碾压mysql,但耗资源,存储数据量有限
- 应用场景:
- 需要高频变更数据时,如:文章点赞数/阅读量
- 频繁访问数据库的高并发场景,如:秒杀
- MongoDB
- 优缺点: 海量数据下,性能优于mysql,但对连表和事务等复杂业务的支持有限
- 应用场景:
- 无复杂业务时,替代mysql
- 拥有内存映射技术,可当作内存数据库使用
14. 物理删除与逻辑删除
- 物理删除:执行的是delete操作,数据从硬盘上删除
- 逻辑删除:执行的是update操作,数据还存在硬盘当中
常见面试题
-
你在测试过程中发现过哪些bug?
-
数据库中有哪些常见的数据类型?【了解】
整数、字符串、小数、日期、文本
- 有没有发现过和数据类型的相关bug?
有,我记得当时开发的是一个商城项目,在一次评审会上,后端设计的数据表里,商品标题用的数类型是varchar(70),
我做了调研,发现10个 字符完全不够,后来建议改为80个字符的限制并最后采取
- 插入数据的SQL命令是什么?【了解】
insert into 表名 values(字段值)
- 什么时候需要插入数据?【了解】
没有硬件设备,如:查询商品出库信息,如果没有出库信息,就可以插入一条出库的数据
- delete、truncate、drop三者的区别?[重点]
- delete删表数据,保留主键记录和表结构
- truncate删表的数据和主键记录,保留表结构
- drop删除表结构和所有的数据
- where和having筛选的区别?【掌握】
- 筛选逻辑
- where对原始数据进行筛选,效率较低
- having对group by分组后的数据进行筛选,效率较高
- having可以使用聚合函数,where不可以
- SQL语句综合书写的顺序【掌握】
- select
- from
- where 条件查询
- group by…having 分组
- order by 排序
- limit 分页
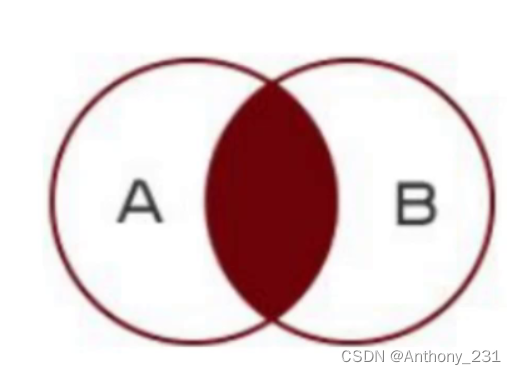
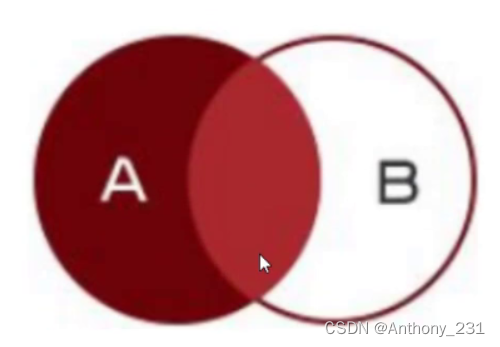
- 内连接,左连接和右连接的区别【重点】
- 内连接,严格显示两张表连接字段相等的数据
- 左连接,显示左表全部数据,包括连接字段相等的数据,如果右表无数据会显示null
- 右连接,显示右表全部数据,包括连接字段相等的数据,如果左表无数据会显示null
- 内连接
- 左连接
- 右连接

-
你什么时候会用到存储过程?【重要】
- 批量添加数据的时候
- 做性能测试时,会使用存储过程帮我们添加海量用户数据
- 对功能做一些极限验证时,例如测试海量商品的分页时,分页功能和分页跳转功能的时候,需要添加数据
- 批量添加数据的时候
-
你在使用redis的过程中,有没有发现过什么bug?【重要】
有,缓存雪崩:遇到一个线上bug,redis缓存在某一时刻失效,大量请求到达MySQL数据库,导致数据库崩溃
解决办法:
-
构建多级缓存,部署多个redis,避免同时过期
-
建议后端程序员,做请求队列机制
12 使用数据库时,遇到过哪些bug?【重点】
- 例如:当时做的OA项目,其中员工表在离职时,功能上使用的是物理删除,我觉得这样不妥,这样的话就不能标识哪个员工是“二进宫”的
- 例如:当时做的是电商项目,其中商品表里,商品下架功能用的是物理删除,我觉得不妥,因为这样的话,再次上架事该商品又得重新操作上架流程,给商家带来困扰,属于用户体验问题。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









