







海量数据下的分布式事务?
单体项目中 只需要关系型数据库来保证ACID 就行。但是分布式情况下,数据库会分成多个库。想达到这种情况的ACID 是不可行的。
分布式下的事务一致
2PC、3PC、TCC、Saga 和 本地消息表 (单机,性能好)
2PC 二阶段提交
3PC
这些方法,它的强项和弱项都不一样,适用的场景也不一样,所以最好这些分布式事务你都能够
掌握,这样才能在面临实际问题的时候选择合适的方法。这里面,2PC 和本地消息表这两种分布式事务的解决方案,比较贴近于我们日常开发的业务系统。
2PC
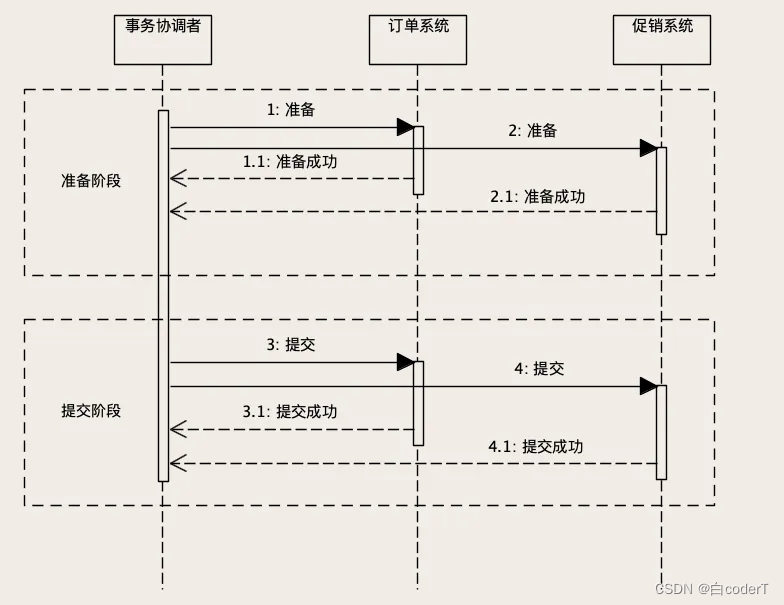
异常情况
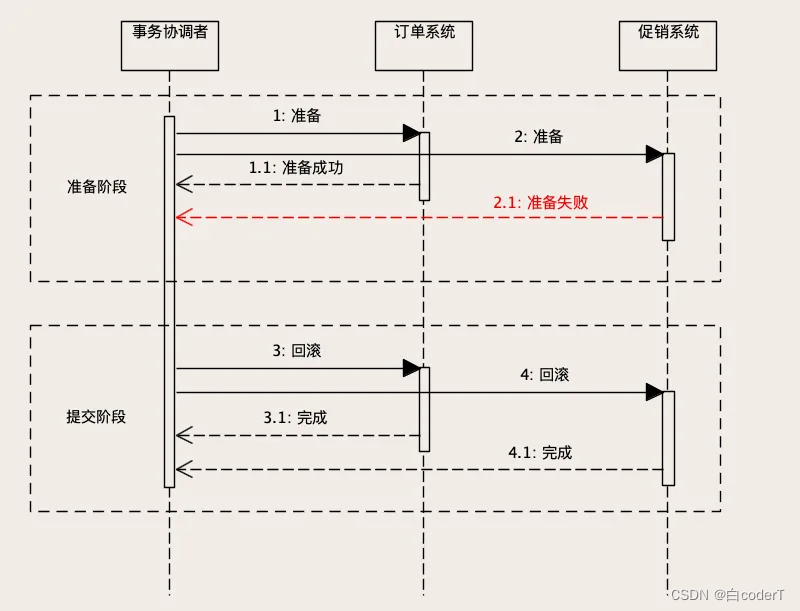
如果准备阶段成功,进入提交阶段,这个时候就“只有华山一条路”,整个分布式事务只能
成功,不能失败。
如果发生网络传输失败的情况,需要反复重试,直到提交成功为止。如果这个阶段发生宕
机,包括两个数据库宕机或者订单服务、促销服务所在的节点宕机,还是有可能出现订单库
完成了提交,但促销库因为宕机自动回滚,导致数据不一致的情况。但是,因为提交的过程
非常简单,执行很快,出现这种情况的概率非常小,所以,从实用的角度来说,2PC 这种
分布式事务的方法,实际的数据一致性还是非常好的。
2PC 是一种强一致的设计,它可以保证原子性和隔离性。只要 2PC 事务完成,订单库和促
销库中的数据一定是一致的状态,也就是我们总说的,要么都成功,要么都失败。
所以 2PC 比较适合那些对数据一致性要求比较高的场景,比如我们这个订单优惠券的场
景,如果一致性保证不好,有可能会被黑产利用,一张优惠券反复使用,那样我们的损失就
大了。
2PC 也有很明显的缺陷,整个事务的执行过程需要阻塞服务端的线程和数据库的会话,所
以,2PC 在并发场景下的性能不会很高。并且,协调者是一个单点,一旦过程中协调者宕
机,就会导致订单库或者促销库的事务会话一直卡在等待提交阶段,直到事务超时自动回
滚。
卡住的这段时间内,数据库有可能会锁住一些数据,服务中会卡住一个数据库连接和线程,
这些都会造成系统性能严重下降,甚至整个服务被卡住。所以,只有在需要强一致、并且并发量不大的场景下,才考虑使用 2PC。
数据库备份
备份
mysqldump -uroot -p test > test.sql
恢复
mysql -uroot test < test.sql
通过时间
mysqlbinlog --start-datetime “2020-02-20 00:00:00” --stop-datetime “2020-02-22 00:00::00”
MySQL HA 如何将“删库跑路”的损失降到最低
通过全量备份加上 Binlog,我们可以将数据库恢复到任何一个时间点,这样至少不会丢数
据了。如果说,数据库服务器宕机了,因为我们有备份数据,完全可以启动一个新的数据库
服务器,把备份数据恢复到新的数据库上,这样新的数据库就可以替代宕机的数据库,继续
提供服务。
但是,这个恢复数据的时间是很长的,如果数据量比较大的话,有可能需要恢复几个小时。
这几个小时,我们的系统是一直不可用的,这样肯定不行。
这个问题怎么解决?很简单,你不要等着数据库宕机了,才开始做恢复,我们完全可以提前
来做恢复这些事儿。
我们准备一台备用的数据库,把它的数据恢复成主库一样,然后实时地在主备数据库之间来
同步 Binlog,主库做了一次数据变更,生成一条 Binlog,我们就把这一条 Binlog 复制到
备用库并立即回放,这样就可以让备用库里面的数据和主库中的数据一直保持是一样的。一
旦主库宕机,就可以立即切换到备用库上继续提供服务。这就是 MySQL 的高可用方案,
也叫 MySQL HA。
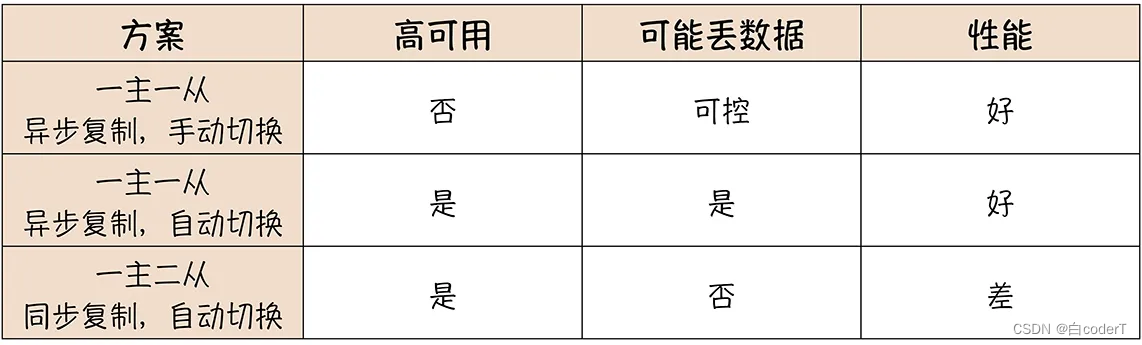
接下来我们说这个方案的问题。当我们对主库执行一次更新操作的时候,主从两个数据库更
新数据实际的时序是这样的
1.在主库的磁盘上写入 Binlog;
2. 主库更新存储引擎中的数据;
3. 给客户端返回成功响应;
4. 主库把 Binlog 复制到从库;
5. 从库回放 Binlog,更新存储引擎中的数据
也就是说,从库的数据是有可能比主库上的数据旧一些的,这个主从之间复制数据的延迟,
称为“主从延迟”。正常情况下,主从延迟基本都是毫秒级别,你可以认为主从就是实时保
持同步的。麻烦的是不正常的情况,一旦主库或者从库繁忙的时候,有可能会出现明显的主
从延迟
有用的案例:
排查慢SQL ,使用查询缓存(排行榜),发现周期性任务。
避免因为个别SQL 拖垮整个库
- 线上环境有1min(时间可以调节)执行一次的脚本。用来杀死SQL 执行超过1min的SQL。这样子即使有慢SQL 也不会导致整个库被带崩
- 在查询窗口前端如果超时,返回静态页面。这样也是可以接受的,不至于影响用户的操作
索引的利弊
增加索引付出的代价是,会降低数据插入、删除和更新的性能。这个也很好理解,增加了索引,在数据变化的时候,不仅要变更数据表里的数据,还要去变更每个索引。
所以,对于更新频繁并且对更新性能要求较高的表,可以尽量少建索引。而对于查询较多更新较少
的表,可以根据查询的业务逻辑,适当多建一些索引。
怎么写 SQL 能更好地使用索引,查询效率更高,这是一门手艺,需要丰富的经验,不是通
过一节课的学习能练成的。但是,我们是有方法,可以评估写出来的 SQL 的查询性能怎么
样,是不是一个潜在的“慢 SQL”。
逻辑不是很复杂的单表查询,我们可能还可以分析出来,查询会使用哪个索引。但如果是比
较复杂的多表联合查询,我们单看 SQL 语句本身,就很难分析出查询到底会命中哪些索
引,会遍历多少行数据。MySQL 和大部分数据库,都提供一个帮助我们分析查询功能:执
行计划。
分析 SQL 执行计划
在 MySQL 中使用执行计划也非常简单,只要在你的 SQL 语句前面加上 EXPLAIN 关键
字,然后执行这个查询语句就可以了。
举个例子说明,比如有一个用户表,包含用户 ID、姓名、部门编号和状态这几个字段:

我带你一起来分析一下这两个 SQL 的执行计划。首先来看 rows 这一列,rows 的含义就
是,MySQL 预估执行这个 SQL 可能会遍历的数据行数。第一个 SQL 遍历了四千多行,这
就是整个 User 表的数据条数;第二个 SQL 只有 8 行,这 8 行其实就是符合条件的 8 条记
录。显然第二个 SQL 查询性能要远远好于第一个 SQL。
为什么第一个 SQL 需要全表扫描,第二个 SQL 只遍历了很少的行数呢?注意看 type 这一
列,这一列表示这个查询的访问类型。ALL 代表全表扫描,这是最差的情况。range 代表
使用了索引,在索引中进行范围查找,因为 SQL 语句的 WHERE 中有一个 LIKE 的查询条
件。如果直接命中索引,type 这一列显示的是 index。如果使用了索引,可以在 key 这一
列中看到,实际上使用了哪个索引。
对于我们日常编写 SQL 的一些优化方法,比如说我刚刚讲的:“尽量不要在 WEHER 条件中,对列做计算”,很多同学只是知道这些方法,但是却不知道,为什么按照这些方法写出来的 SQL 就快?
数据库的服务端,可以划分为执行器 (Execution Engine) 和 存储引擎 (StorageEngine) 两部分。执行器负责解析 SQL 执行查询,存储引擎负责保存数据。
小结
一条 SQL 在数据库中执行,首先 SQL 经过语法解析成 AST,然后 AST 转换为逻辑执行计
划,逻辑执行计划经过优化后,转换为物理执行计划,再经过物理执行计划优化后,按照优
化后的物理执行计划执行完成数据的查询。几乎所有的数据库,都是由执行器和存储引擎两
部分组成,执行器负责执行计算,存储引擎负责保存数据。
分库分表
原则:
数据量大 -> 分表 (MyCat SharedingJDBC)
支持高并大 -> 分库
如何选择 Sharding Key?
分库分表还有一个重要的问题是,选择一个合适的列或者说是属性,作为分表的依据,这个
属性一般称为 Sharding Key。像我们上节课讲到的归档历史订单的方法,它的 Sharding
Key 就是订单完成时间。每次查询的时候,查询条件中必须带上这个时间,我们的程序就
知道,三个月以前的数据查订单历史表,三个月内的数据查订单表,这就是一个简单的按照
时间范围来分片的算法。
选择合适 Sharding Key 和分片算法非常重要,直接影响了分库分表的效果。我们首先来说
如何选择 Sharding Key 的问题。
没什么头绪的问题
把订单表拆分之后,那些和订单有外键关联的表,该怎么处理
小规模的集群建议使用官方的 Redis Cluster,在节点数量不多的情况下,各方面表现都不错。
再大一些规模的集群,可以考虑使用 twemproxy 或者 Codis 这类的基于代理的集群架构,虽然是开源方案,但是已经被很多公司在生产环境中验证过。
相比于代理方案,使用定制客户端的方案性能更好,很多大厂采用的都是类似的架构
缓存穿透:超大规模系统的不能承受之痛
我们上节课讲到了如何构建 Redis 集群,由于集群可以水平扩容,那只要集群足够大,理论上支持海量并发也不是问题。但是,因为并发请求的数量这个基数太大了,即使有很小比率的请求穿透缓存,打到数据库上请求的绝对数量仍然不小。加上大促期间的流量峰值,还是存在缓存穿透引发雪崩的风险。
那这个问题怎么解决呢?其实方法你也想得到,不让请求穿透缓存不就行了?反正现在存储也便宜,只要你买得起足够多的服务器,Redis 集群的容量就是无限的。不如把全量的数据都放在 Redis 集群里面,处理读请求的时候,干脆只读 Redis,不去读数据库。这样就完全没有“缓存穿透”的风险了,实际上很多大厂它就是这么干的。
cancal 接 MQ 实现数据同步
为了保证数据的因果一致性。只能用单线程去同步
但是可以分库分表的思想,因果一致性是他们 id一致,所以还是可以使用并发手段,将id 相同的binlog数据分到同一个分区中同步。进而提高同步效率
NewSQL
CockroachDB
RocksDB
RocksDB是 Facebook 开源的一个高性能持久化 KV 存储。目前,你可能很少见到过哪个项目会直接使用 RocksDB 来保存数据,在未来,RocksDB 大概率也不会像 Redis 那样被业务系统直接使用。那我们为什么要关注它呢?
因为越来越多的新生代数据库,都不约而同地选择 RocksDB 作为它们的存储引擎。在将来,很有可能出现什么样的情况呢?我们使用的很多不同的数据库,它们背后采用的存储引擎都是 RocksDB。
我来给你举几个例子。我们上节课讲到的 CockroachDB 用到了 RocksDB 作为它的存储引擎。再说几个比较有名的, MyRocks这个开源项目,你看它这个名字就知道它是干什么的了。它在用 RocksDB 给 MySQL 做存储引擎,目的是取代现有的 InnoDB 存储引擎。并且,MySQL 的亲兄弟 MariaDB 已经接纳了 MyRocks,作为它的一个可选的存储引擎。
还有大家都经常用的实时计算引擎 Flink,用过的同学都知道,Flink 的 State 就是一个KV 的存储,它使用的也是 RocksDB。还有包括 MongoDB、Cassandra 等等很多的数据库,都在开发基于 RocksDB 的存储引擎。
说到 KV 存储,我们最熟悉的就是 Redis 了,接下来我们就来对比一下 RocksDB 和 Redis这两个 KV 存储。
其实 Redis 和 RocksDB 之间没什么可比性,一个是缓存,一个是数据库存储引擎,放在一起比就像“关公战秦琼”一样。那我们把这两个 KV 放在一起对比,目的不是为了比谁强谁弱,而是为了让你快速了解 RocksDB 能力。
我们知道 Redis 是一个内存数据库,它之所以能做到非常好的性能,主要原因就是,它的
数据都是保存在内存中的。从 Redis 官方给出的测试数据来看,它的随机读写性能大约在
50 万次 / 秒左右。而 RocksDB 相应的随机读写性能大约在 20 万次 / 秒左右,虽然性能
还不如 Redis,但是已经可以算是同一个量级的水平了。
这里面你需要注意到的一个重大差异是,Redis 是一个内存数据库,并不是一个可靠的存
储。数据写到内存中就算成功了,它并不保证安全地保存到磁盘上。而 RocksDB 它是一个
持久化的 KV 存储,它需要保证每条数据都要安全地写到磁盘上,这也是很多数据库产品的
基本要求。这么一比,我们就看出来 RocksDB 的优势了,我们知道,磁盘的读写性能和内
存读写性能差着一两个数量级,读写磁盘的 RocksDB,能和读写内存的 Redis 做到相近的
性能,这就是 RocksDB 的价值所在了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









