









脚本部分有的是网上搜集的,有的是自己写的
脚本
图片爆破宽高等脚本在ctf misc 图片题知识点中
零宽字符查找
快速判断文件中存在哪几种零宽字符
zero_list = ['\u200a','\u200b','\u200c','\u200d','\u200e','\u200f','\u202a','\u202c','\u202d','\u2062','\u2063','\ufeff']
ans = []
f = open(r'E:\desktop\ikun.txt','r',encoding='utf-8')
re = f.read()
f.close()
for i in zero_list:
if i in re:
ans.append(i)
if len(ans) != 0:
print('fonud: '+str(ans)[1:-1].replace(',',' '))
else:
print('not found')
二进制转二维码
运行之前先改好图片边长,即MAX的值,例如二进制字符串长度为625(25*25),这里就改成25
import PIL
from PIL import Image
MAX = 25 #图片边长
img = Image.new("RGB",(MAX,MAX))
str='1111111001110010001111111100000100001111010100000110111010011100010010111011011101010111100001011101101110101010101000101110110000010011000101010000011111111010101010101111111000000000100000110000000011000111011101101000110000001000010110010010010100010011110100001110111001100111101001010110010010011000001001100001001101000111100011111101110010100010110111110011011111101111000110110010010101101100100011110011111111111011100000000101100011000101001111111010010100101010001100000101010101010001100110111010001001111111100101011101000011001011110111101110100100110010010000110000010110000110110110011111111011010000101110101'
i = 0
for y in range (0,MAX):
for x in range (0,MAX):
if(str[i] == '1'):
img.putpixel([x,y],(0, 0, 0))
else:
img.putpixel([x,y],(255,255,255))
i = i+1
img.show()
img.save("flag.png")
base64
base64异或
import base64
s='TkVLTFdUQVpvUlNda1ZXRUpAZVldTltgJCQhLCAgGSknPjc='
s=base64.b64decode(s)
for i in range(256):
flag=""
k=0
for j in s:
res=j^(k+i)
flag+=chr(res)
k+=1
print(i,flag)
base64隐写加密(py2)
# -*- coding: cp936 -*-
import base64
flag = 'Tr0y{Base64isF4n}' # flag
bin_str = ''.join([bin(ord(c)).replace('0b', '').zfill(8) for c in flag])
base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
with open('0.txt', 'rb') as f0, open('1.txt', 'wb') as f1: # '0.txt'是明文, '1.txt'用于存放隐写后的base64
for line in f0.readlines():
rowstr = base64.b64encode(line.replace('\n', ''))
equalnum = rowstr.count('=')
if equalnum and len(bin_str):
offset = int('0b' + bin_str[:equalnum * 2], 2)
char = rowstr[len(rowstr) - equalnum - 1]
rowstr = rowstr.replace(char, base64chars[base64chars.index(char) + offset])
bin_str = bin_str[equalnum * 2:]
f1.write(rowstr + '\n')
base64隐写解密(py2)
# -*- coding: cp936 -*-
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
#https://tr0y.wang/2017/06/14/Base64steg/
with open('1.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = ''.join(line.split())
rowb64 = ''.join(stegb64.decode('base64').encode('base64').split())
offset = abs(b64chars.index(stegb64.replace('=', '')[-1]) - b64chars.index(rowb64.replace('=', '')[-1]))
equalnum = stegb64.count('=') # no equalnum no offset
if equalnum:
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print ''.join([chr(int(bin_str[i:i + 8], 2)) for i in xrange(0, len(bin_str), 8)]) # 8位一组
1-5位的crc32碰撞
6位的碰撞已经有现成的工具了
# coding:utf-8
"""
Author:spaceman
"""
import binascii
import string
from time import sleep
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(s)
return True
except (TypeError, ValueError):
pass
return False
# 进度条
def progress(percent=0, width=40):
left = width * percent // 95
right = width - left
print ('\r[', '#' * left, ' ' * right, ']',f' {percent:.0f}%',sep='', end='', flush=True)
# 一位字节
def crc1(strs,dic):
strs = hex(int(strs,16))
rs = ''
for i in dic:
s = i
if hex(binascii.crc32(s.encode())) == strs:
rs += s
print (strs+' : '+s)
return rs
# 两位字节
def crc2(strs,dic):
strs = hex(int(strs,16))
rs = ''
for i in dic:
for j in dic:
s = i + j
if hex(binascii.crc32(s.encode())) == strs:
rs += s
print (strs+' : '+s)
return rs
# 三位字节
def crc3(strs,dic):
strs = hex(int(strs,16))
rs = ''
for i in dic:
for j in dic:
for k in dic:
s = i+j+k
if hex(binascii.crc32(s.encode())) == strs:
rs += s
print (strs+' : '+s)
return rs
# 四位字节
def crc4(strs,dic):
strs = hex(int(strs,16))
rs = ''
it = 1
for i in dic:
for j in dic:
for k in dic:
for m in dic:
s = i+j+k+m
if hex(binascii.crc32(s.encode())) == strs:
rs += s
print ()
print (strs+' : '+s)
print ('\n')
progress(it)
sleep(0.1)
it += 1
return rs
# 五位字节
def crc5(strs,dic):
strs = hex(int(strs,16))
rs = ''
it = 1
for i in dic:
progress(it)
for j in dic:
for k in dic:
for m in dic:
for n in dic:
s = i+j+k+m+n
if hex(binascii.crc32(s.encode())) == strs:
rs += s
print ()
print (strs+' : '+s)
print ('\n')
sleep(0.1)
it += 1
return rs
# 计算碰撞 crc
def CrackCrc(crclist,length):
print ()
print ("正在计算...")
print ()
dic = ''' !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~''' # 碰撞需要的字符字典
dic = dic[::-1]
text = ''
for i in crclist:
if length == '1':
text += crc1(i,dic)
if length == '2':
text += crc2(i,dic)
if length == '3':
text += crc3(i,dic)
if length == '4':
text += crc4(i,dic)
if length == '5':
text += crc5(i,dic)
print ('\n')
if text == '':
print ("碰撞失败,无结果")
exit()
print ("字符顺序组合:",end=' ')
print ()
print (text)
print ()
input("回车确认结束程序...")
# 主函数
print ('''
##############################
###### Author:spaceman ######
### Thank you for your use ###
##############################
''')
listcrc = [] # 用于存储crc值
length = (input("请输入文本字节大小(1-5):")) # 即文本内容大小,如文本内容为flag,大小即为4
if is_number(length) == False or length not in ("1,2,3,4,5"):
exit("非指定数字,退出")
print ()
while 1:
crc = input('请输入crc值(例如:d1f4eb9a,输入n完成输入):')
if crc == 'n':
break
crc = '0x'+crc
if len(crc) != 10:
print ("rcr长度不对,请重新输入")
continue
listcrc.append(crc)
CrackCrc(listcrc,length)
将十进制数写入文件中
x=[55,122,188,175,175]
f=b''
for i in x:
f += i.to_bytes(1,'big')
out=open("1.7z","wb")
out.write(f)
usb流量
键盘流量
先tshark导出数据
┌──(volcano㉿kali)-[~/桌面]
└─$ tshark -r whereiskey.pcapng -T fields -e usb.capdata | sed ‘/^\s*$/d’ > out.txt
然后每两个数字之间加一个冒号
f=open('1.txt','r')
fi=open('out.txt','w')
while 1:
a=f.readline().strip()
if a:
if len(a)==16: # 鼠标流量的话len改为8
out=''
for i in range(0,len(a),2):
if i+2 != len(a):
out+=a[i]+a[i+1]+":"
else:
out+=a[i]+a[i+1]
fi.write(out)
fi.write('\n')
else:
break
fi.close()
再跑脚本
normalKeys = {"04":"a", "05":"b", "06":"c", "07":"d", "08":"e", "09":"f", "0a":"g", "0b":"h", "0c":"i", "0d":"j", "0e":"k", "0f":"l", "10":"m", "11":"n", "12":"o", "13":"p", "14":"q", "15":"r", "16":"s", "17":"t", "18":"u", "19":"v", "1a":"w", "1b":"x", "1c":"y", "1d":"z","1e":"1", "1f":"2", "20":"3", "21":"4", "22":"5", "23":"6","24":"7","25":"8","26":"9","27":"0","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>","2d":"-","2e":"=","2f":"[","30":"]","31":"\\","32":"<NON>","33":";","34":"'","35":"<GA>","36":",","37":".","38":"/","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"}
shiftKeys = {"04":"A", "05":"B", "06":"C", "07":"D", "08":"E", "09":"F", "0a":"G", "0b":"H", "0c":"I", "0d":"J", "0e":"K", "0f":"L", "10":"M", "11":"N", "12":"O", "13":"P", "14":"Q", "15":"R", "16":"S", "17":"T", "18":"U", "19":"V", "1a":"W", "1b":"X", "1c":"Y", "1d":"Z","1e":"!", "1f":"@", "20":"#", "21":"$", "22":"%", "23":"^","24":"&","25":"*","26":"(","27":")","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>","2d":"_","2e":"+","2f":"{","30":"}","31":"|","32":"<NON>","33":"\"","34":":","35":"<GA>","36":"<","37":">","38":"?","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"}
output = []
keys = open('out.txt')
for line in keys:
try:
if line[0]!='0' or (line[1]!='0' and line[1]!='2') or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0' or line[6:8]=="00":
continue
if line[6:8] in normalKeys.keys():
output += [[normalKeys[line[6:8]]],[shiftKeys[line[6:8]]]][line[1]=='2']
else:
output += ['[unknown]']
except:
pass
keys.close()
flag=0
print("".join(output))
for i in range(len(output)):
try:
a=output.index('<DEL>')
del output[a]
del output[a-1]
except:
pass
for i in range(len(output)):
try:
if output[i]=="<CAP>":
flag+=1
output.pop(i)
if flag==2:
flag=0
if flag!=0:
output[i]=output[i].upper()
except:
pass
print ('output :' + "".join(output))
鼠标流量
依旧是先导出
┌──(volcano㉿kali)-[~]
└─$ tshark -r secret.pcapng -T fields -e usb.capdata | sed ‘/^\s*$/d’ > out.txt
然后跑脚本
nums = []
keys = open('out.txt','r')
posx = 0
posy = 0
for line in keys:
if len(line) != 13:
continue
x = int(line[4:6],16)
y = int(line[6:8],16)
if x > 127 :
x -= 256
if y > 130 :
y -= 265
posx += x
posy += y
btn_flag = int(line[2:4],16)
if btn_flag == 1: # 1 for left , 2 for right , 0 for nothing
print posx ,posy
keys.close()
转字符
二进制转字符
常见的每八位转,有时候是每7位,需要对脚本稍加改动
def fun1():#二进制字符串转换字符串
#需要转换的字符串
f = '0001000001110001000000010001001000010001001000110111001100010000011100010000011101010000010010000100100001001000000100100101'
b = ''
i = 0
j = 8 #有时要改成7
while j <= len(f):
a = '0' + f[i:j]
b += chr(int(a,2))
i = j
j += 8 #有时改成7
print(b)
def fun2():#字符串转换二进制字符串
#需要转换的字符串
f = ' '
b = ''
c = ''
for i in f:
a = str(bin(ord(i)))
b = a[2:].zfill(7)
c += b
print(c)
fun1()
#fun2()
八进制转字符
s="146154141147173144157137171157165137153156157167137160141167156163150157160175"
x=[]
for i in range(len(s)//3): #根据题目修改大小, 字符串长度除以3
x.append(s[3*i:3*i+3])
y=[]
flag=""
for j in range(len(x)):
y.append(int(x[j],base=8))
for k in range(len(x)):
flag+=chr(y[k])
print(flag)
十进制转字符
适用于给的是一长串连在一起的十进制
s="98117103107117123110974810048110103100971079749125"
x=len(s)//2
flag=""
for i in range(x):
if len(s) != 0:
if int(s[:3])< 127:
flag += chr(int(s[:3]))
s = s[3:]
else:
flag += chr(int(s[:2]))
s = s[2:]
print(flag)
hex转字符
import binascii
s=""
s=binascii.unhexlify(s)
print(s.decode('utf-8'))
bmp的lsb隐写
import PIL.Image as Image
img = Image.open('low.bmp')
img_tmp = img.copy()
pix = img_tmp.load()
width,height = img_tmp.size
for w in range(width):
for h in range(height):
if pix[w,h]&1 == 0:
pix[w,h] = 0
else:
pix[w,h] = 255
img_tmp.show()
TTL隐写
import binascii
with open('attachment.txt','r') as fp:
a=fp.readlines()
p=[]
for x in range(len(a)):
p.append(int(a[x]))
s=''
for i in p:
if(i==63):
b='00'
elif(i==127):
b='01'
elif(i==191):
b='10'
else:
b='11'
s +=b
# print(s)
flag = ''
for i in range(0,len(s),8):
flag += chr(int(s[i:i+8],2))
flag = binascii.unhexlify(flag)
wp = open('ans.zip','wb')
wp.write(flag)
wp.close()
仿射密码
# 仿射密码
z = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w',
'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z']
# 通过列表来表示Z整数环中的52个元素
def exgcd(a, b, arr): # 通过拓展欧几里得定理来求a对于整数环中的逆元
if b == 0:
arr[0] = 1
arr[1] = 0
return a
r = exgcd(b, a % b, arr)
tmp = arr[0]
arr[0] = arr[1]
arr[1] = tmp - int(a / b) * arr[1]
return r
def Get_ei(a, b):
arr = [0, 1, ]
r = exgcd(a, b, arr)
if r == 1:
return int((arr[0] % b + b) % b)
else:
return -1
def encrypt(k1, k2, message): # 加密过程
a = str(message)
t = ""
for i in a:
if i in z:
c = z.index(i)
Y = (k1 * c + k2) % 52
t += z[Y]
else:
t += i
return t
# print(ord(i))
# *************begin************#
# **************end*************#
def decrypt(k1, k2, message): # 解密过程
k1_ = Get_ei(k1, 52)
t = ""
a = str(message)
for i in a:
if i in z:
c = z.index(i)
X = (k1_ * (c - k2)) % 52
t += z[X]
else:
t += i
return t
def main():
mode = int(input()) # 1代表加密,0代表解密
message = input() # 待加密或解密的消息
key1 = int(input()) # key的范围0~51之间
key2 = int(input()) # key的范围0~51之间
if mode == 1:
translated = encrypt(key1, key2, message)
else:
translated = decrypt(key1, key2, message)
print(translated)
if __name__ == '__main__':
main()
将图片内容上下翻转
from PIL import Image
im = Image.open("1.jpg")
pim = im.load()
an = Image.open("1.jpg")
ans = an.load()
for i in range(im.size[0]):
for j in range(im.size[1]):
ans[i, j] = pim[im.size[0]-i-1, j]
an.show()
傅里叶变换
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
img = cv.imread('FFT.png', 0) #直接读为灰度图像
f = np.fft.fft2(img) #做频率变换
fshift = np.fft.fftshift(f) #转移像素做幅度谱
s1 = np.log(np.abs(fshift))#取绝对值:将复数变化成实数取对数的⽬的为了将数据变化到0-255
plt.subplot(121)
plt.imshow(img, 'gray')
plt.title('original')
plt.subplot(122)
plt.imshow(s1,'gray')
plt.title('center')
plt.show()
批量读取压缩包
import zipfile
for i in range(1, 87):
# 读取压缩包
z = zipfile.ZipFile(r'C:\Users\Desktop\flag/' + str(i)+'.zip', 'r')
# 读取压缩包内的图片内容
filename = z.namelist()[0]
content = str(z.read(filename))
# 把base64编码部分打印出来
len1 = len(content)
content1 = content[len1-101:len1-1] #根据题目更改
print(content1)
autokey爆破(py2)
from ngram_score import ngram_score
from pycipher import Autokey
import re
from itertools import permutations
qgram = ngram_score('quadgrams.txt')
trigram = ngram_score('trigrams.txt')
ctext = 'achnrvxzzuglarucalznwcygfggrufryvbzqjoxjymxvchhhdmliddcwmhghclpebtzwlojvew'
ctext = re.sub(r'[^A-Z]','',ctext.upper())
# keep a list of the N best things we have seen, discard anything else
class nbest(object):
def __init__(self,N=1000):
self.store = []
self.N = N
def add(self,item):
self.store.append(item)
self.store.sort(reverse=True)
self.store = self.store[:self.N]
def __getitem__(self,k):
return self.store[k]
def __len__(self):
return len(self.store)
#init
N=100
for KLEN in range(3,20):
rec = nbest(N)
for i in permutations('ABCDEFGHIJKLMNOPQRSTUVWXYZ',3):
key = ''.join(i) + 'A'*(KLEN-len(i))
pt = Autokey(key).decipher(ctext)
score = 0
for j in range(0,len(ctext),KLEN):
score += trigram.score(pt[j:j+3])
rec.add((score,''.join(i),pt[:30]))
next_rec = nbest(N)
for i in range(0,KLEN-3):
for k in xrange(N):
for c in 'ABCDEFGHIJKLMNOPQRSTUVWXYZ':
key = rec[k][1] + c
fullkey = key + 'A'*(KLEN-len(key))
pt = Autokey(fullkey).decipher(ctext)
score = 0
for j in range(0,len(ctext),KLEN):
score += qgram.score(pt[j:j+len(key)])
next_rec.add((score,key,pt[:30]))
rec = next_rec
next_rec = nbest(N)
bestkey = rec[0][1]
pt = Autokey(bestkey).decipher(ctext)
bestscore = qgram.score(pt)
for i in range(N):
pt = Autokey(rec[i][1]).decipher(ctext)
score = qgram.score(pt)
if score > bestscore:
bestkey = rec[i][1]
bestscore = score
print bestscore,'autokey, klen',KLEN,':"'+bestkey+'",',Autokey(bestkey).decipher(ctext)
在线网站
修复二维码
https://merricx.github.io/qrazybox
一些聚合网站
常用的base编码、url编码等以及各种加密都有
http://www.hiencode.com/
https://tool.lu/
https://ctf.bugku.com/tools.html
https://www.ctftools.com/down/
https://www.idcd.com/
bugku的旧在线工具可以用来枚举栅栏密码和凯撒密码
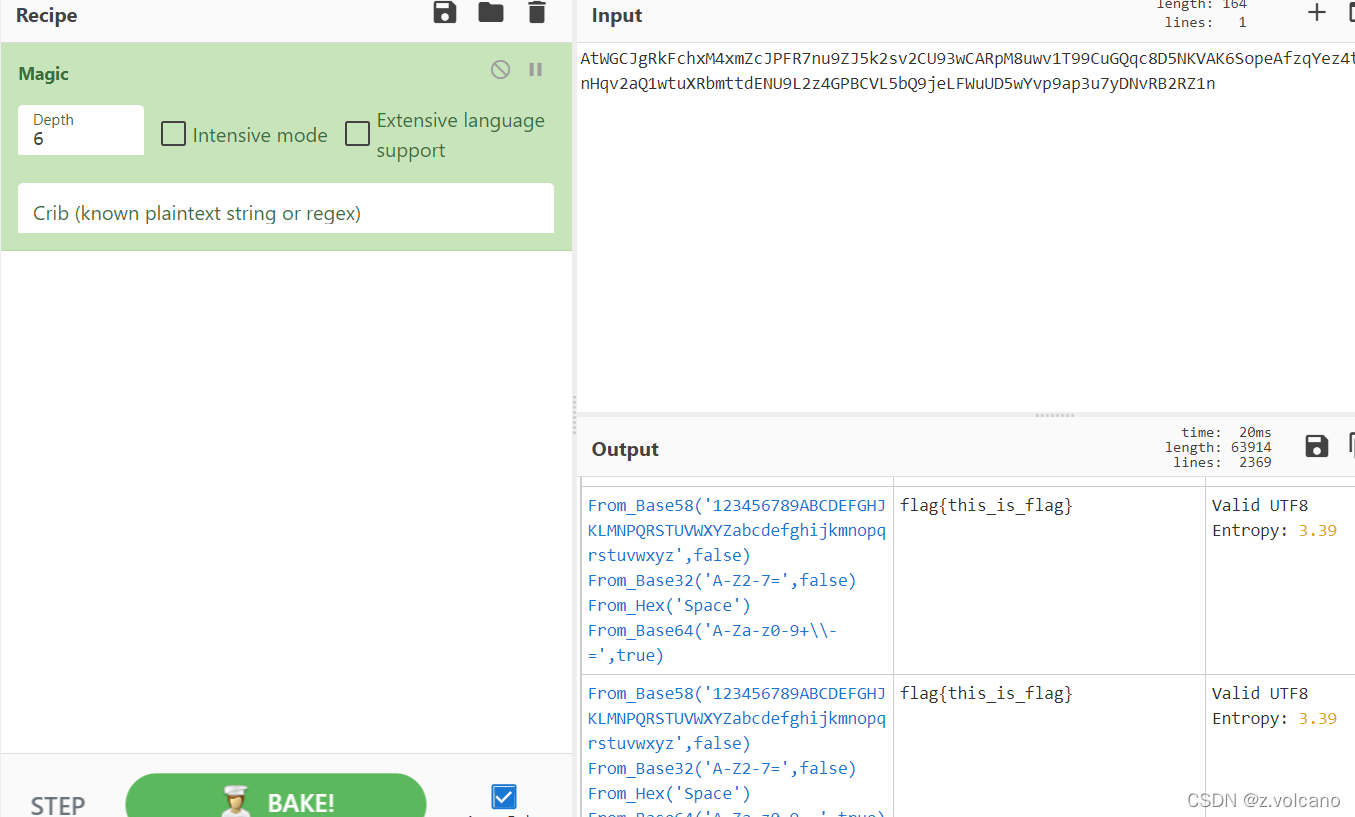
CyberChef的话建议下载到本地,这个工具非常好用,尤其是遇到多层套娃的加密时(Magic)
G语言代码在线运行
md5解密
https://www.cmd5.com/
https://www.somd5.com/
https://pmd5.com/
各种码的识别
条形码、二维码等的识别
https://demo.dynamsoft.com/barcode-reader/
Aztec Code识别
https://products.aspose.app/barcode/recognize/aztec#result
箭头符号、花朵、音符、盲文等编码
点击切换即可

https://www.qqxiuzi.cn/bianma/wenbenjiami.php?s=jiantou
维吉尼亚解密
很多时候可以直接跑出明文
https://www.guballa.de/vigenere-solver
https://www.dcode.fr/vigenere-cipher (要科学上网)
rot5/13/18/47
https://www.qqxiuzi.cn/bianma/ROT5-13-18-47.php
emoji加密
常见的就是base100和emoji-aes
https://aghorler.github.io/emoji-aes/
http://www.atoolbox.net/Tool.php?Id=937
https://ctf.bugku.com/tool/base100
brainfuck/Ook!
https://www.splitbrain.org/services/ook
零宽字符解密
http://330k.github.io/misc_tools/unicode_steganography.html
https://yuanfux.github.io/zero-width-web/
http://www.atoolbox.net/Tool.php?Id=829
exif信息查看
大质数分解(RSA常用)
词频分析
熊曰/兽音/佛曰
http://hi.pcmoe.net/index.html
需要key的佛曰
https://talk-with-buddha.netlify.app/
pyc反编译
解音频里的莫斯密码
https://morsecode.world/international/decoder/audio-decoder-adaptive.html


















 6176
6176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











