







文章目录
1.包管理 (调用)
包介绍
- 一个文件夹可以成为一个包
- 在文件夹(包)中可以创建多个文件夹
- 在 同一个包下的每一个文件中必须指定
包名称且相同 - 同一个包中,包名相同,可直接
调用其他文件中的功能
包分类
- main包,必须写一个
main函数,此函数就是项目的入口(main主函数)。编译生成的就是一个可执行文件。 - 非main包,用来将代码
分类,方便查找
注意:功能必须首字母大写
如果是小写开头,则不能被其他所调用
调用包(在同一个级别)

然后运行,发现只build文件app1没有编译app2
-
手动执行go install
-
修改配置:让其直接可编译一个文件夹里面的内容


结果
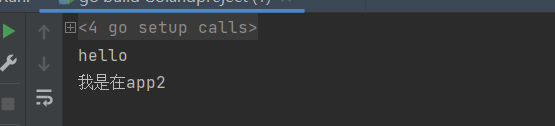
不同级别
导入包----->也就是文件所在位置
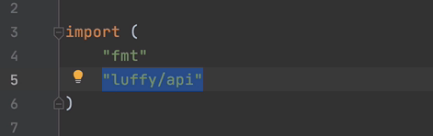
调用功能

例如:
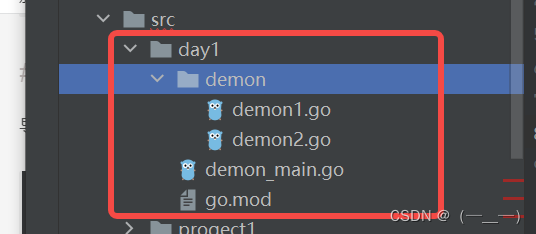
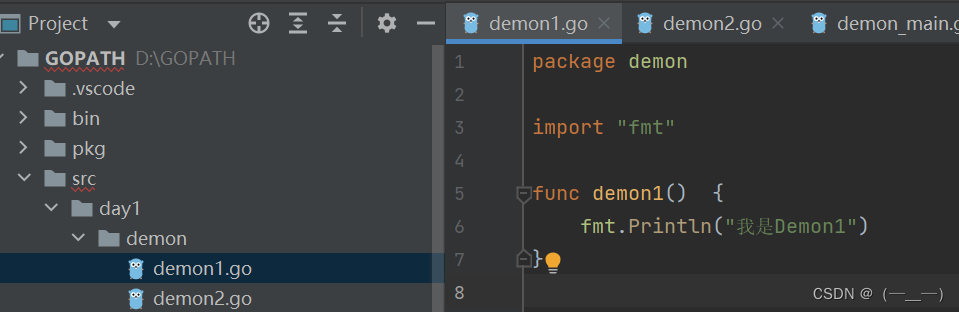

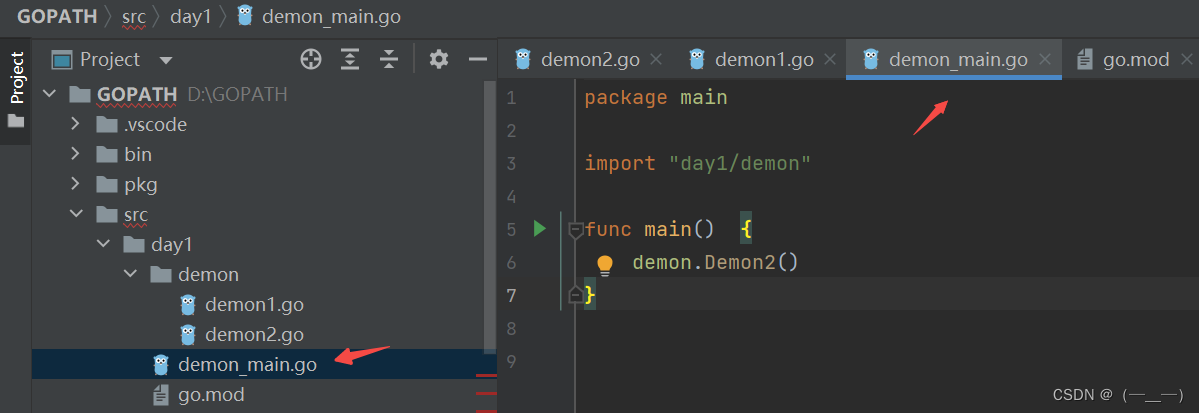
在项目根目录执行go mod init生成go,mod文件
最后运行整个项目就可以
2 . 输出print
内置函数
不确定高版本会支持
- print 不换行
- println
fmt 包 (推荐)
-
fmt.Printf 不换行,可以转义特殊字符
需要格式化输出并带输出格式,可以打印出字符串,和变量Printf : 只可以打印出格式化的字符串,可以输出字符串类型的变量,不可以输出整形变量和整形
var a int=1
fmt.Printf("%d,%s",a,"abc")
- fmt.Println
println会根据你输入格式原样输出,
fmt.Println("hello","world","nice")
结果:中间有空格
hello woeld nice
也就是说,当需要格式化输出信息时一般选择 Printf,其他时候用 Println 就可以了
3. 输入 fmt.Scan
fmt.Scan
fmt.Scanln
fmt.Scanf
- 用指针,也就是会用到内存地址
&为指针,指向的地址- 类型要匹配,所有类型都可以
- switch可以用于判断
interface变量实际存储的变量类型。
var name string
fmt.Scan(&name)

特别说明:fmt.Scan 要求输入两个值,必须输入两个,否则他会一直等待。
var name string
var age int
fmt.Println("请输入用户名:")
// 当使用Scan时,会提示用户输入
// 用户输入完成之后,会得到两个值:count,用户输入了几个值;err,用输入错误则是错误信息
_, err := fmt.Scan(&name, &age)
if err == nil {
fmt.Println(name, age)
} else {
fmt.Println("用户输入数据错误", err)
}
特别说明:fmt.Scanln 等待回车。
var name string
var age int
fmt.Print("请输入用户名:")
// 当使用Scanln时,会提示用户输入
// 用户输入完成之后,会得到两个值:count,用户输入了几个值;err,用输入错误则是错误信息
count, err := fmt.Scanln(&name, &age)
fmt.Println(count, err)
fmt.Println(name, age)
fmt.Scanf支持特殊字符
var name string
var age int
fmt.Print("请输入用户名:")
_, _ = fmt.Scanf("我叫%s 今年%d 岁", &name, &age)
fmt.Println(name, age)
读取整整一行
当使用ftm.Scan等功能时,如果输入一整行且期间存在空格,则无法获取整行。
想要读取一行数据,这个功能可以基于标准输入来进行实现。
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
reader := bufio.NewReader(os.Stdin)
// line,从stdin中读取一行的数据(字节集合 -> 转化成为字符串)
// reader默认一次能4096个字节(4096/3)
// 1. 一次性读完,isPrefix=false
// 2. 先读一部分,isPrefix=true,再去读取isPrefix=false
line, _, _ := reader.ReadLine()
data := string(line)
fmt.Println(data)
}
3. 注释
// 只能注释一行
/*
可以注释多行
*/
4. Go语言命名规则

5. ASCII码


6. 基本元素

25个关键字

字面量

操作符匀运算符

声明
















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









