









prepare_lang和lang文件的各种文件详解
1 prepare_lang源码详解



(在lang_tmp中生成的lexiconp.txt加入了B I E的符号,我认为是一个词对应的音素的开始中间和结束)









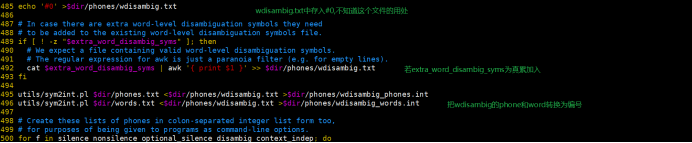


2.lang中的文件
L_disambig.fst:
L.fst
oov.int:是存储集外词索引的
oov.txt:是存储集外词的
phones:是一个文件夹
phones.txt:格式是音素标号 索引
topo:里面存储的是HMM的拓扑结构
words.txt:格式是词的标号 索引
phones文件夹


silence增加了BEIS,.int为存储的索引,.csl和.int内容一样格式不同是通过:号分割的。

align_lexicon.txt也是发音字典,只不过是将第一列再重复了一列,是用来处理词网络文件和一些识别结果的
- context_indep文件的内容是所有上下文无关的列表。在这个文件中出现的元素都被定义为无关音素。
- disambig是所以消歧符号的列表(#)
- extra_questions文件的内容与发音词典同名的内容类似,增加了位置标记,用于音素上下文聚类
- optional_silence文件的内容是词间选择性填充的静音音素的列表
- sets文件定义了音素组,roots文件定义哪些音素共享上下文决策树的一个根节点。这两个文件夹是在上下文聚类用到的
3 总结
通过prepare_lang生成的lang文件夹有很多重要的东西,最重要的就是L.fst和topo文件。L.fst生成里面图的权重可忽略(好像是没有),因为是根据发音词典生成的是固定的。其输入是音素输出是词。topo在后面的模型构建是十分有用的,说明了静音和非静音音素构建的状态数目,其HMM转移概率对于后面的HCLG来说太小,目前像chain已经把其概率固定住,对于最后的解码来说图中的概率基本上是根据G.fst也就是语言模型给出的。















 6486
6486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









