






一、实验名称
python环境下browsermobproxy+selenium实现豆瓣模拟登录。
二、基本原理
(一)概述
使用selenium模拟打开页面、输入账户密码、点击、滑动等操作,browsermobproxy设置代理抓取包含滑动验证码图像的请求。实验中难点在于滑动验证码的破解。
(二)browsermobproxy
BrowserMob Proxy允许操作HTTP请求和响应,捕获HTTP内容,并将性能数据导出为HAR文件。按下列教程安装好后即可运行。(https://blog.csdn.net/qq_44315987/article/details/116501955)
如下所示例子中result存储了webdriver访问时的请求。
from selenium import webdriver
from browsermobproxy import Server
server = Server(r'D:\python_env\exper4\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat')
server.start()
proxy = server.create_proxy()
print('proxy', proxy.proxy)
chrome_options = Options()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
proxy.new_har("douban", options={'captureHeaders': True, 'captureContent': True})
browser.get('https://accounts.douban.com/passport/login_popup?login_source=anony')
result = proxy.har
使用json格式化工具可以查看每一条请求的url。

从目标url中可以抓取验证图片。这样处理是因为直接通过元素查找不能找到所需图片。

(三)查找缺口位置
获取到无缺口的原图、带缺口的图片后,我们需要定位缺口的位置。由于图片中存在一些干扰因素(如下方两张灰度图的上面一张图的上边缘依稀可以看到一些白色的噪点,也就是说两张图不同的部分不止缺口所在位置),直接通过单个像素比较不能准确找到缺口的位置。


下面时我借助卷积神经网络的思想实现的一种图片比较方法。
将两个灰度图像对应的矩阵进行相减,同时采取极端的阈值(设为1)将所得图像进行二值化,得到如下图像(白色部分灰度值为255,黑色部分灰度值为0)。

然后用一个大小与拼图块相同,元素全为1的卷积核对图像进行类似卷积的操作(即分块求和)。
# seghalf 为 拼图块的边长的一半
# height,width分别为原图的宽和长
core_array = np.zeros((height,width))
step_size = 5 # 步长,减小计算量
for i in range(seghalf,height-seghalf, step_size):
for j in range(seghalf,width-seghalf, step_size):
temp_array = minus_pic[i-seghalf:i+seghalf,j-seghalf:j+seghalf]
core_array[i][j] = np.sum(temp_array)
所得结果core_array中最大元素所在位置即为拼图的中心。
(四)滑动操作
使用坐标工具对相关位置进行定位,调用Selenium相关鼠标事件即可完成操作。
滑动不能过于僵硬,需要模拟人手动滑动过程。
# 模拟人为拖动
def get_track(distance):
"""
根据偏移量获取移动轨迹
:param distance: 偏移量
:return: 移动轨迹
"""
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正2
a = 2
else:
# 加速度为负3
a = -1
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
(五)防检测
这是后面发现的问题,selenium默认情况下会出现表单无法提交的情况。
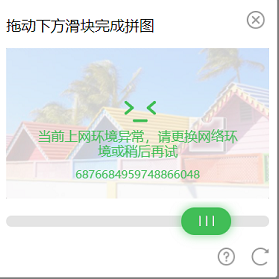
因此也需要设置一些参数将自己隐藏起来,如打开谷歌开发者模式,去取webdriver标识。
# 开发者模式
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
# 去除webdriver标识
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
打开开发者模式后,标签栏附近的自动测试提示也消失了。

三、具体步骤
1. 导入相关库
import re
import cv2
import time
import requests
import numpy as np
from selenium import webdriver
from browsermobproxy import Server
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
2.配置代理
# 配置代理
server = Server(r'D:\python_env\exper4\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat') # bat路径
server.start()
proxy = server.create_proxy()
print('proxy', proxy.proxy)
chrome_options = Options()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
proxy.new_har("douban", options={'captureHeaders': True, 'captureContent': True})
# 防检测
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
3.打开浏览器访问登录页面
browser = webdriver.Chrome(chrome_options=chrome_options)
# 去掉webdriver标识防检测
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# 打开目标窗口
browser.get('https://accounts.douban.com/passport/login_popup?login_source=anony')
browser.maximize_window()
time.sleep(1)
browser.find_elements(by=By.XPATH,value='//li[@class="account-tab-account"]')[0].click()
time.sleep(1)
username = '' # 账号
password = '' # 密码
browser.find_elements(by=By.XPATH,value='//input[@class="account-form-input"]')[0].send_keys(username) # 输入用户名
browser.find_elements(by=By.XPATH,value='//input[@class="account-form-input password"]')[0].send_keys(password) # 输入密码
browser.find_elements(by=By.XPATH,value='//div[@class="account-form-field-submit "]')[0].click() # 点击登录
time.sleep(sleep_time)
result = proxy.har
# with open('output.txt','w',encoding='utf8') as f:
# f.write(str(result))
# break
pic_url = None
# 抓取图像url
for entry in result['log']['entries']:
_url = entry['request']['url']
# 根据URL找到数据接口
if "hycdn?" in _url:
pic_url = _url
print(pic_url)
break
# 抓取时尚未发出请求,则重新访问抓取
if pic_url is None:
print('no_data')
sleep_time += 1
browser.close()
continue
# 停止代理
server.stop()
成功输入账号密码,打开验证码界面:
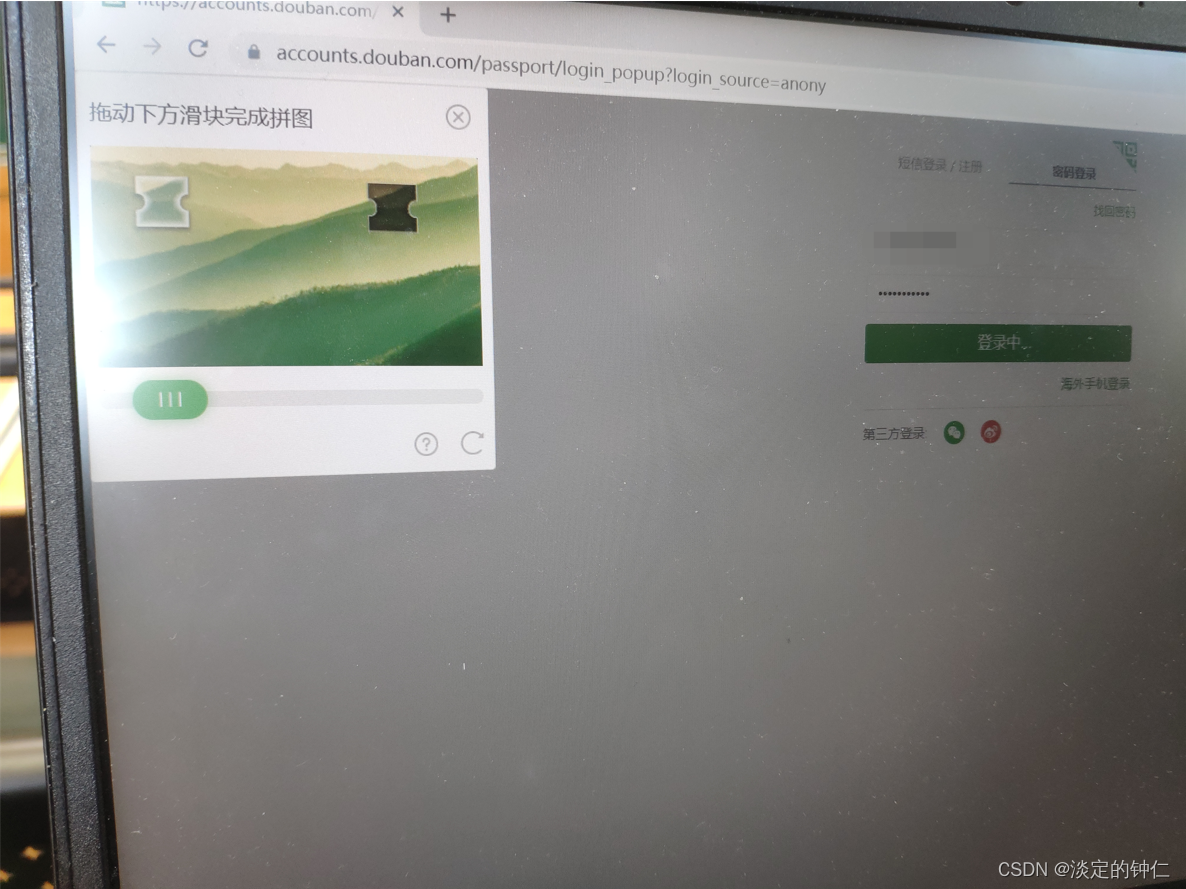
同时获得pic_url如下:
https://t.captcha.qq.com/hycdn?index=1&image=937625773573401088?aid=2044348370&sess=s0BPJKOhJ6Ui0xiAFkP8g9qIYCeMDfa0j2uQUgwwb0AT-dzDfRcdgckFzZL0EeTHhTKk8cCf0pHiyGsz2es72seJrNody8vV65ESofx0b2w8Y4WVkARtWmUjanuJjIoyMK2tYrqfU1A9mYcf7Ekv64ycewssZ_RW-nYJfiWuG6wkqqZ50ZcfrLuDaxsXDVkff1BUkUOV2HBjTRyGbVO08Gy7azDs8_sBJI7_KVuDQWoL8zuJVl6sDw_WkXL-5h3XnNirWtKA0Yf5tRT0MfAOW0fMXmbuCGNJ5ljszCluWuHJXxUME_O9R59g
4.将验证图片保存到本地
使用正则表达式对url关键位置字符进行替换得到三张图的url。使用requests库访问后将返回值保存到本地。
# 分别获取三张图片
origin_pic = re.sub('img_index=\d&','img_index=0&',pic_url)
unfull_pic = re.sub('img_index=\d&','img_index=1&',pic_url)
seg_pic = re.sub('img_index=\d&','img_index=2&',pic_url)
# 保存原图
response = requests.get(origin_pic)
with open('origin.jpg','wb') as f:
f.write(response.content)
# 保存带缺口的图片
response = requests.get(unfull_pic)
with open('unfull.jpg','wb') as f:
f.write(response.content)
# 保存缺口图片
response = requests.get(seg_pic)
with open('seg.jpg','wb') as f:
f.write(response.content)
5.查找缺口位置
# 打开灰度图像origin = cv2.imread('origin.jpg',cv2.IMREAD_GRAYSCALE)unfull = cv2.imread('unfull.jpg',cv2.IMREAD_GRAYSCALE)seg = cv2.imread('seg.jpg',cv2.IMREAD_GRAYSCALE)height,width = origin.shape # 图像大小segheight = 114/171*136 # 拼图块中央部分大小seghalf = int(segheight/2) # 拼图块大小的一半rate = 282/width # 网页中图片与下载图片的比例# 求minus_pic = np.array(origin)-np.array(unfull)# 二值化m, n = minus_pic.shapefor i in range(m): for j in range(n): if minus_pic[i][j] > 0: minus_pic[i][j] = 255cv2.imwrite('minus.jpg',minus_pic)core_array = np.zeros((height,width))# 依次计算每个窗口灰度值的和step_size = 5for i in range(seghalf,height-seghalf, step_size): for j in range(seghalf,width-seghalf, step_size): temp_array = minus_pic[i-seghalf:i+seghalf,j-seghalf:j+seghalf] core_array[i][j] = np.sum(temp_array)# 获得最大值索引m, n = core_array.shapeindex = int(core_array.argmax())y_move = int(index / n)x_move = index % nprint(n,m)print(x_move,y_move)
结果如下所示(上方为图片尺寸,下方为缺口位置):

与二图相减并二值化处理的图像进行对比,发现几乎一致。

6.根据坐标对滑块进行拖动
# 网页中图片与下载图片的比例rate = 282/width # 滑块目标位置x_target = x_move*rate + 12/375*298y_target = y_base# 移动到滑动条起始位置webdriver.ActionChains(browser).move_by_offset(x_base,y_base).click().perform()distance = x_target-x_base# 模仿人类行为缓慢滑动tracks = get_track(distance)tracks.append(-(sum(tracks)-distance)) # 补正操作for track in tracks: webdriver.ActionChains(browser).move_by_offset(track,0).perform()webdriver.ActionChains(browser).click().perform()
截图快捷键捕捉不到成功的瞬间,就用手机相机拍摄图片了。
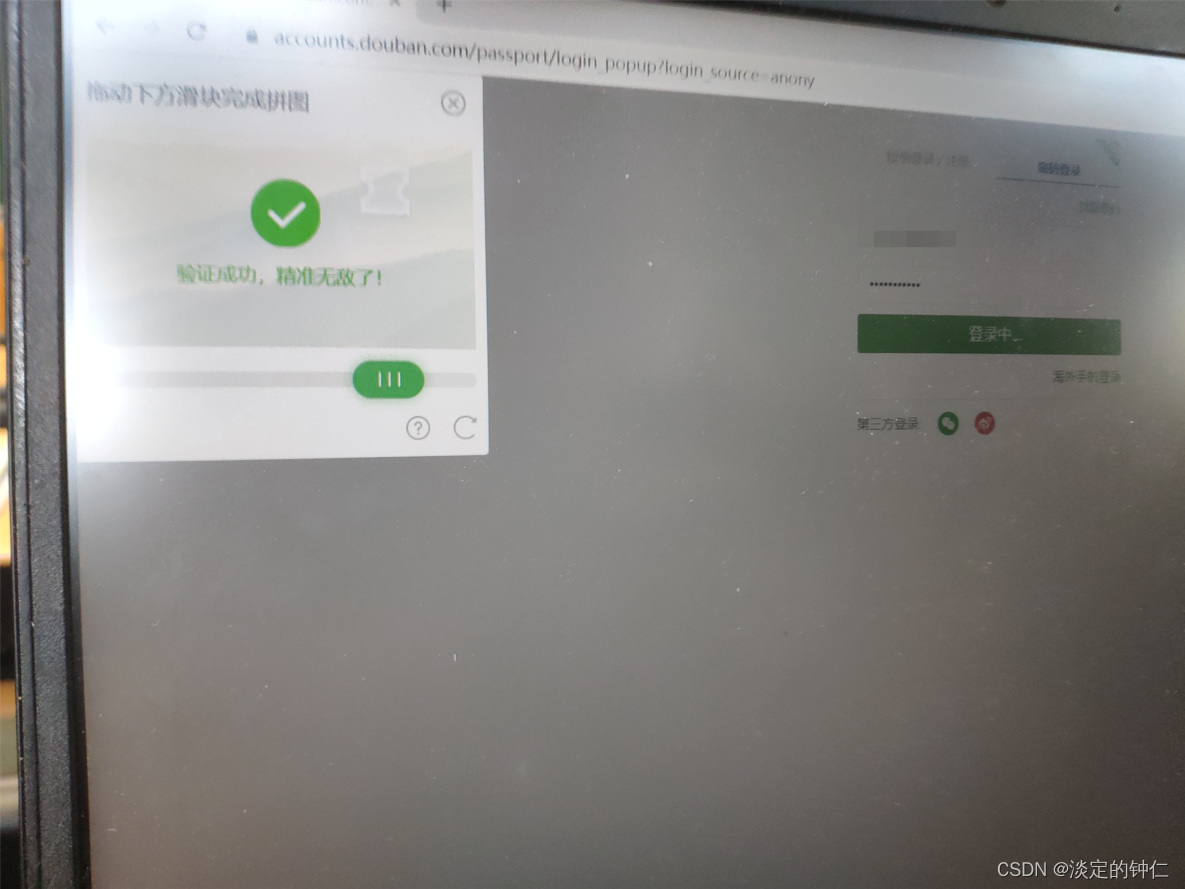
可以看到验证通过,精准无敌了!
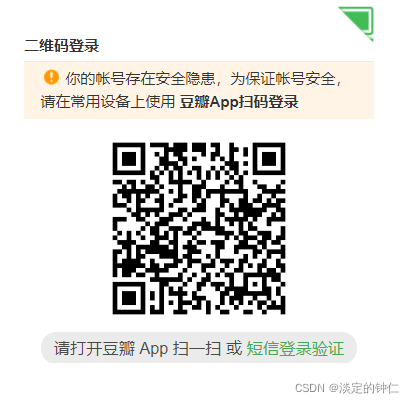
此外尝试登陆次数过多时官网也会对帐号进行检测,需下载App扫码登陆,最近好像一直不行(可能这就是它的营销策略吧)。
四、完整代码
加入简单的异常处理后总结完整代码如下
import reimport cv2import timeimport requestsimport numpy as npfrom selenium import webdriverfrom browsermobproxy import Serverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.chrome.options import Options# 帐号密码username = ''password = ''# 模拟人为拖动def get_track(distance): """ 根据偏移量获取移动轨迹 :param distance: 偏移量 :return: 移动轨迹 """ # 移动轨迹 track = [] # 当前位移 current = 0 # 减速阈值 mid = distance * 4 / 5 # 计算间隔 t = 0.2 # 初速度 v = 0 while current < distance: if current < mid: # 加速度为正2 a = 2 else: # 加速度为负3 a = -1 # 初速度v0 v0 = v # 当前速度v = v0 + at v = v0 + a * t # 移动距离x = v0t + 1/2 * a * t^2 move = v0 * t + 1 / 2 * a * t * t # 当前位移 current += move # 加入轨迹 track.append(round(move)) return trackif __name__ == '__main__': # 配置代理 server = Server(r'D:\python_env\exper4\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat') server.start() proxy = server.create_proxy() print('proxy', proxy.proxy) chrome_options = Options() chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy)) # 防检测 chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) chrome_options.add_argument("--disable-blink-features=AutomationControlled") proxy.new_har("douban", options={'captureHeaders': True, 'captureContent': True}) pic_url = None sleep_time = 6 while not pic_url: # 打开目标窗口 browser = webdriver.Chrome(chrome_options=chrome_options) # 去掉webdriver标识防检测 browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) """ }) # browser = webdriver.Chrome() browser.get('https://accounts.douban.com/passport/login_popup?login_source=anony') # browser.get('https://accounts.douban.com/passport/login?redir=https://accounts.douban.com/') browser.maximize_window() time.sleep(1) browser.find_elements(by=By.XPATH,value='//li[@class="account-tab-account"]')[0].click() time.sleep(1) browser.find_elements(by=By.XPATH,value='//input[@class="account-form-input"]')[0].send_keys(username) # 输入用户名 time.sleep(2) browser.find_elements(by=By.XPATH,value='//input[@class="account-form-input password"]')[0].send_keys(password) # 输入密码 time.sleep(2) browser.find_elements(by=By.XPATH,value='//div[@class="account-form-field-submit "]')[0].click() # 点击登录 time.sleep(sleep_time) result = proxy.har # with open('output.txt','w',encoding='utf8') as f: # f.write(str(result)) # break pic_url = None # 抓取图像url for entry in result['log']['entries']: _url = entry['request']['url'] # 根据URL找到数据接口 if "hycdn?" in _url: pic_url = _url print(pic_url) break # 抓取时尚未发出请求,则重新访问抓取 if pic_url is None: print('no_data') sleep_time += 1 browser.close() continue # 停止代理 server.stop() # 分别获取三张图片 origin_pic = re.sub('img_index=\d&','img_index=0&',pic_url) unfull_pic = re.sub('img_index=\d&','img_index=1&',pic_url) seg_pic = re.sub('img_index=\d&','img_index=2&',pic_url) # 保存原图 response = requests.get(origin_pic) with open('origin.jpg','wb') as f: f.write(response.content) # 保存带缺口的图片 response = requests.get(unfull_pic) with open('unfull.jpg','wb') as f: f.write(response.content) # 保存缺口 response = requests.get(seg_pic) with open('seg.jpg','wb') as f: f.write(response.content) # 打开灰度图像 origin = cv2.imread('origin.jpg',cv2.IMREAD_GRAYSCALE) unfull = cv2.imread('unfull.jpg',cv2.IMREAD_GRAYSCALE) seg = cv2.imread('seg.jpg',cv2.IMREAD_GRAYSCALE) height,width = origin.shape # 图像大小 segheight = 114/171*136 # 拼图块中央部分大小 seghalf = int(segheight/2) # 拼图块大小的一半 rate = 282/width # 网页中图片与下载图片的比例 # 求 minus_pic = np.array(origin)-np.array(unfull) # 二值化 m, n = minus_pic.shape for i in range(m): for j in range(n): if minus_pic[i][j] > 0: minus_pic[i][j] = 255 cv2.imwrite('minus.jpg',minus_pic) core_array = np.zeros((height,width)) # 依次计算每个窗口灰度值的和 step_size = 5 for i in range(seghalf,height-seghalf, step_size): for j in range(seghalf,width-seghalf, step_size): temp_array = minus_pic[i-seghalf:i+seghalf,j-seghalf:j+seghalf] core_array[i][j] = np.sum(temp_array) # 获得最大值索引 m, n = core_array.shape index = int(core_array.argmax()) y_move = int(index / n) x_move = index % n print(n,m) print(x_move,y_move) # 滑动条起始位置 x_base = 76/375*298 y_base = 287/375*298 print(x_base,y_base) # 滑块目标位置 x_target = x_move*rate + 12/375*298 y_target = y_base print(x_target,y_target) # 移动到滑动条起始位置 webdriver.ActionChains(browser).move_by_offset(x_base,y_base).click().perform() distance = x_target-x_base # webdriver.ActionChains(browser).move_by_offset(distance, 0).click().perform() tracks = get_track(distance) tracks.append(-(sum(tracks)-distance)) for track in tracks: webdriver.ActionChains(browser).move_by_offset(track,0).perform() webdriver.ActionChains(browser).click().perform() time.sleep(10)
五、实验感受
1.实验中验证图片不能直接通过查找元素得到,需要拦截请求做出相应操作,browsermobproxy可以很好地解决这个问题。
2.图片比较过程中单纯比较像素点的方法不是很有效,参考卷积神经网络思想使用卷积核对图像进行分块求和可以以相对较高的效率地查找到两张图片的不同区域位置。
3.在网页通过坐标进行鼠标事件操作是个令人头疼的问题,出于显示设置及坐标工具显示问题,在选取过程中一般需要通过css显示尺寸和所量得的尺寸进行一个等比缩放。
4.即使使用selenium也有被检测的可能。
5.打码服务贵有贵的理由。















 5457
5457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









