







1、背景介绍:
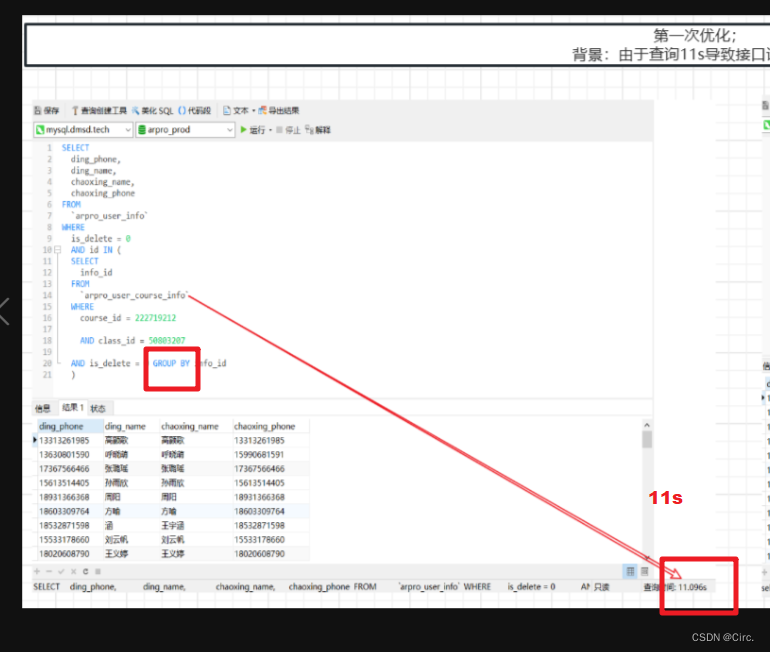
前端调用后端接口的时候发现接口的响应时间特别长,然后对后端接口进行分析。最后发现是sql语句的执行时间太长。看了一下sql语句的相关信息:course_id字段和class_id字段添加了索引,左连接两个表的id类型不一致,使用分组的方式进行去重。下面对sql语句进行分析。
2、思路&过程
1.sql语句各部分的执行顺序。
2.明确distinct和group by的差异。
3.查看sql语句是否已经添加了索引,索引是否失效。
sql执行顺序
1.from
2.on
3.join
4.where
5.group by
6.having + 聚合函数
7.select
8.distinct
9.order by
10.limit

以上sql语句的执行顺序为3->4->5->2->6->1
明确distinct和group by的差异
1.有索引的情况下,group by和distinct 都能用索引,效率相同
2.无索引的时候,distinct 效率高于 group by,distinct 是根据信息不同进行直接进行去重,group by 的原理是对结果先进行 分组排序 ,然后返回每组中的第一条数据。
3.如果是单纯的去重操作的话,无论是否有索引,distinct 的效率都更加高,但是如果 查询的列和去重的列不对应的话,distinct就无法使用了。相较于group by 不够灵活。
4.group by 的语义更加的明确,并且group by 可以根据分组的情况加上聚合函数,做一些其他的处理,功能更加丰富。但是有时候效率将低于distinct。
5.distinct用法
select distinct 列1 , 列2 from table
group by用法
select 列1,列2 from table group by 列1 ,列2
数据不一致影响索引
SELECT
aui.ding_phone,
aui.ding_name,
aui.chaoxing_name,
aui.chaoxing_phone
FROM
( SELECT info_id FROM arpro_user_course_info WHERE course_id = 223667994 AND class_id = 55801765 AND is_delete = 0 GROUP BY info_id ) auci
LEFT JOIN arpro_user_info aui ON auci.info_id = aui.id
可以看见这里的条件是courseid,classid,还有两个表的id
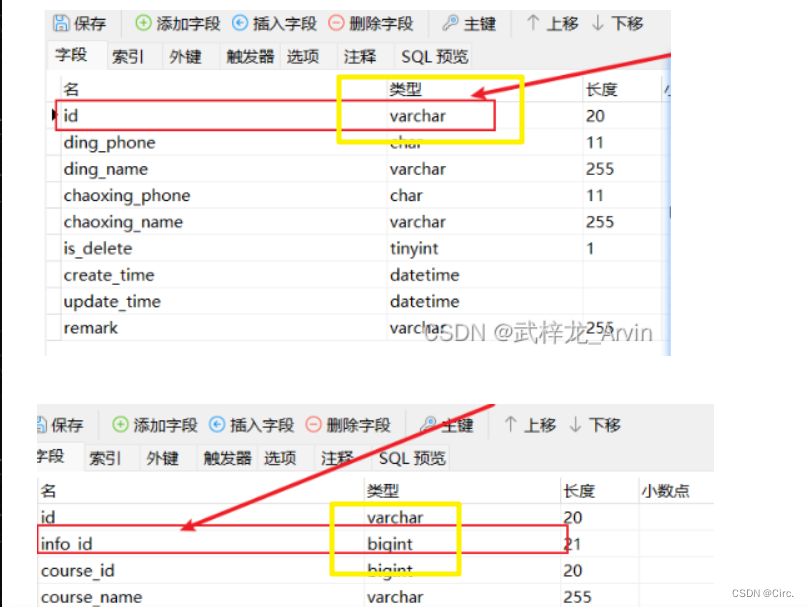
这里可以看到两张表的id类型不一致
创建索引如下

非两个表的id的那张临时表生效了
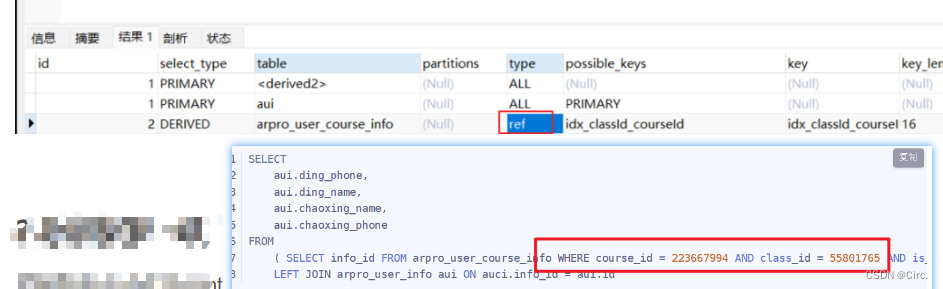
改正后

改正后生效了。
3、总结:
明确sql语句的执行顺序有助于我们对于sql语句进行优化。提高我们对数据库和sql语句的理解。来编写效率更高的语句。
DISTINCT和GROUP BY都是用于在数据库查询中对结果集进行处理的关键字,但它们的用途和效果有所不同。
DISTINCT:
DISTINCT用于去除查询结果中重复的行,使得查询结果中的每一行都是唯一的。它可以应用于单个列或多个列,但在查询时仅返回每个不同组合的值。当你只关心结果集中的不同值而不需要对其进行聚合或分组时,DISTINCT是非常有用的。
例如,假设我们有一张名为"employees"的表,其中包含了员工的信息,我们想要获取所有不同的员工姓氏,可以使用以下查询:
sql
Copy code
SELECT DISTINCT last_name FROM employees;
GROUP BY:
GROUP BY用于对查询结果进行分组,并在每个组中进行聚合操作(例如,求和、平均值、计数等)。当你希望根据某些列的值对结果进行分组,并对每个分组应用聚合函数时,就可以使用GROUP BY。
例如,我们想要按部门对员工进行分组,并计算每个部门的平均工资和员工数目,可以使用以下查询:
sql
Copy code
SELECT department, AVG(salary) AS average_salary, COUNT(*) AS employee_count
FROM employees
GROUP BY department;
在这个查询中,我们使用了GROUP BY department来将结果按照部门进行分组,并分别计算了每个部门的平均工资和员工数目。
总结:
DISTINCT用于去除结果集中重复的行,使得每一行都是唯一的。
GROUP BY用于将结果集按照指定的列进行分组,并对每个分组进行聚合计算。
需要根据具体的查询需求来选择使用哪个关键字。如果你只想获取不同的值而不需要聚合操作,就使用DISTINCT;如果你需要对结果进行聚合计算并按照某些列进行分组,就使用GROUP BY。
















 4495
4495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











