






 本文详细介绍了Unicode字符集的组成,包括ASCII、拉丁美洲和阿拉伯国家的符号编码,以及Unicode编码的扩展如UTF-8、UTF-16和UTF-32的区别。此外,还提供了FreeBASIC示例程序展示字符转换过程,并提及了汉字编码标准的发展与Unicode在全球范围的应用。
本文详细介绍了Unicode字符集的组成,包括ASCII、拉丁美洲和阿拉伯国家的符号编码,以及Unicode编码的扩展如UTF-8、UTF-16和UTF-32的区别。此外,还提供了FreeBASIC示例程序展示字符转换过程,并提及了汉字编码标准的发展与Unicode在全球范围的应用。
一、图示unicode之组成
unicode是symbol的集合,准确的说不是语言的集合。回观人类历史,甲骨文、玛雅文,都是一些符号,符号的组合蕴含着特定信息,现在unicode也是符号,符号的组合同样蕴含着复杂的人类信息。unicode包含了世界各大洲的信息符号,美西的符号相对较少,东亚CJK仓颉占据的空间最大,而且分成了多个段。
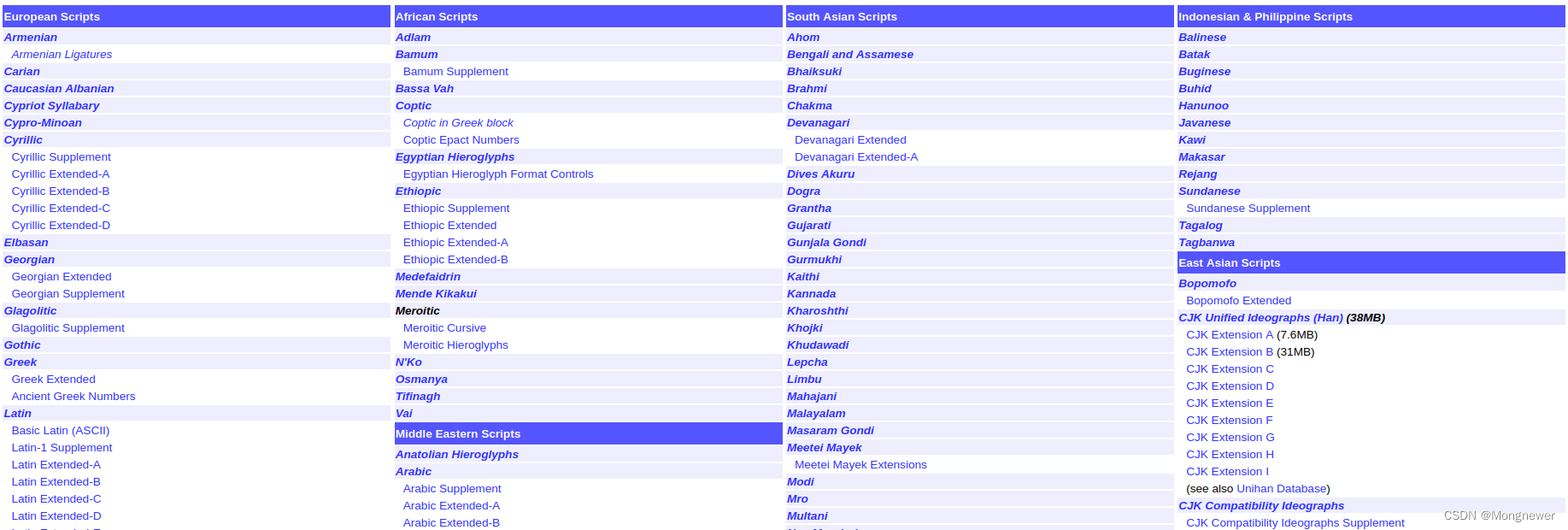
Unicode符号表按类存放,从0开始统一编号,最后是 0x10FFFF,即114111 + 1 个符号(因为它是从 0 开始的编码的)。 这个统一编码,即是所谓的unicode码。排在最前面的是ASCII码表,与原用的ASCII码表编号完全一致,一个byte就代表了。
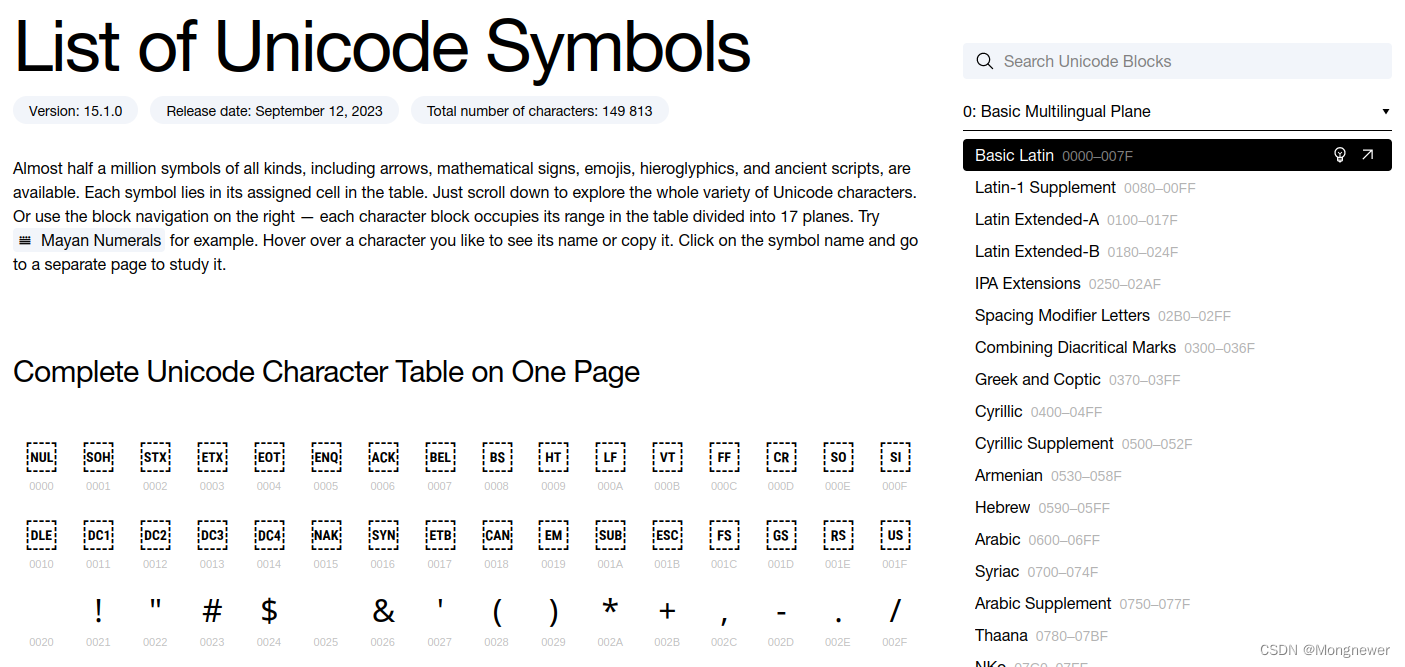
接下来是拉丁、美国和阿拉伯国家的信息符号编码

仓颉分成多段存放
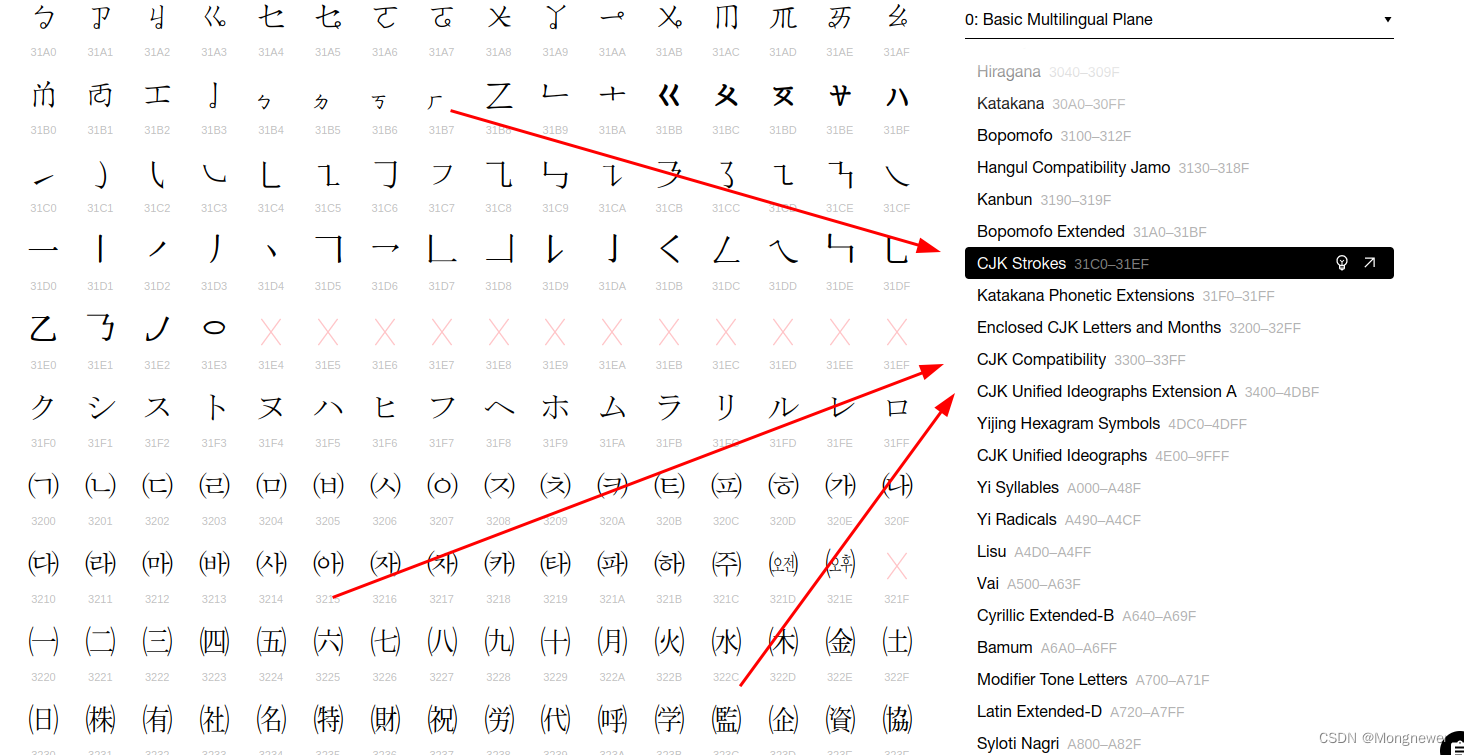
码表中还存放有全人类共识的emoj表情符号,公共场所用的提示符号等。
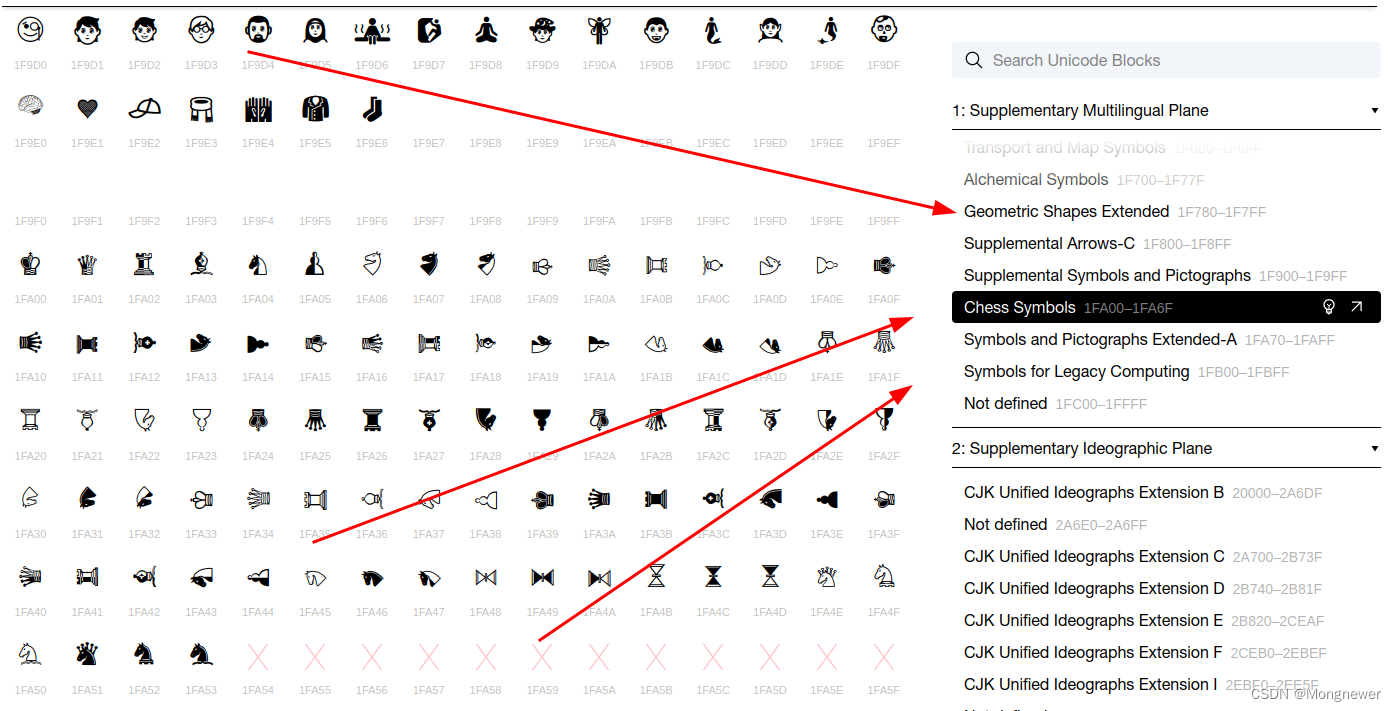
平时用的汉字大致在这个位置(应该是与GB18020是相对应的)

后部分还有许多特殊符号和预留位置
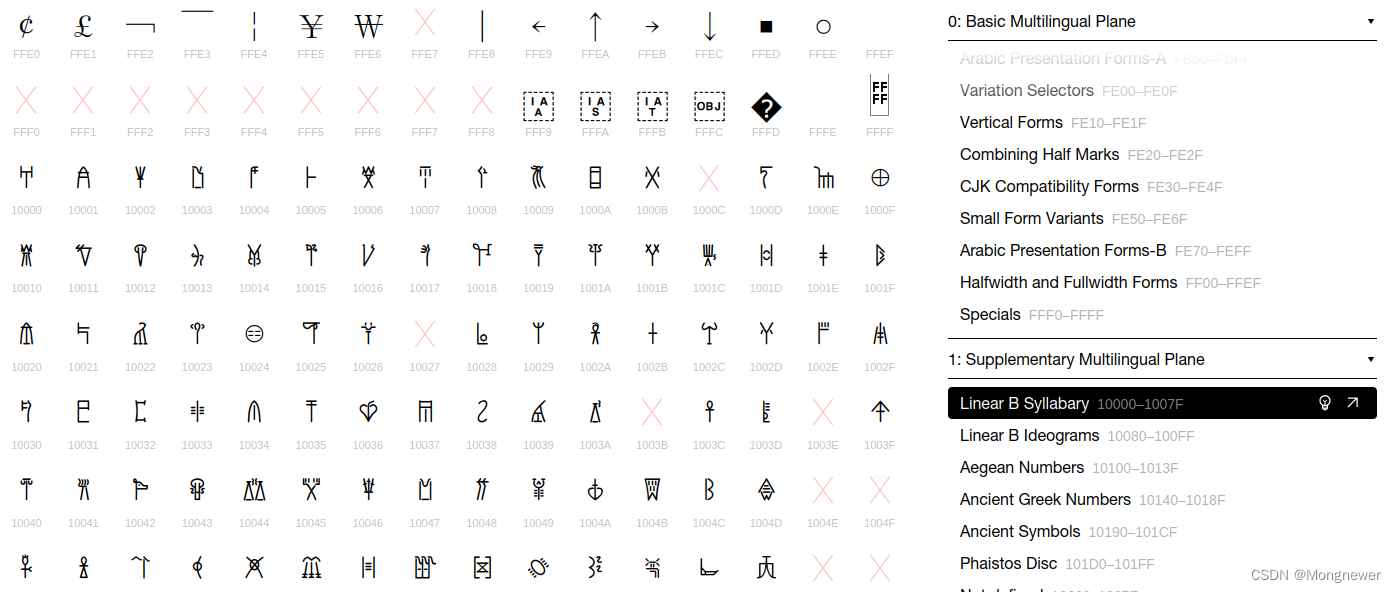
平时交换信息用不到11万多的符号,有两个byte或曰一个word,即 FFFF , 亦即 65536 个符号就可满足大部分场合的信息交换了。这部分符号被称之为 Basic-Multilingual-Plane,简写为 BMP,但在计算机语言表达上 MS-WINDOWS系与LINUX系并不相同,Linux系不论是BMP还是之外的其它部分符号,均使用4字节编码,即使是ascii也占用四个字节,无需转换。过去计算机用ascii码表的符号叫字符,现在也是字符但内含扩大了,起名叫宽字符,宽字符也是byte组成的,那就叫它multibyte 多字符,因此它们像是光的波与粒子一样(波粒两重性)并不矛盾。
二、UTF 与 Unicode
有许多文章解释 utf-8, utf-16, utf-32 ,它们是 unicode 编码传输时的转换编码,是从1个byte到连续4个byte的可变信息码。ascii码用一个byte就表示了,unicode码表后面的符号要用到4个byte才能表示。utf-8是1到4个byte连续变化,utf-16是2个byte再加2个byte的变化,utf-32不变化,因为utf-32可以表达全部unicode码表的符号。之所以utf-8最常用,因为它既能表示出unicode符号信号,又能节约传输带宽,不像utf-32即便一个 0x20 空格也要补0点位成32位、浪费许多带宽资源。
1、FreeBASIC utf-8与unicode转换示例程序1:
Print "Multiple UNICODE characters: "; WChr(&H7F8E, &H4E3D, &H4E2D, &H56FD)
括号里面的十六进制又字节码是unicode码,它显示出来的内容是“美丽中国”。
2、FreeBASIC utf-8与unicode转换示例程序2:
它输出的是连续的byte字节 E7BE8EE4B8BDE4B8ADE59BBD00,是unicode转换出来的utf-8代码。程序中 UTF_ENCOD_UTF8表示转换为 utf-8 信息码, UTF_ENCOD_UTF16表示转换出 utf-16码, UTF_ENCOD_UTF32 表示转换同 utf-32 信息码。
scope '' UTF <-> Wchar
dim as wstring ptr srcstr = @wstr("美丽中国")
dim as byte ptr utfstr
dim as integer chars
Dim i as integer
utfstr = WCharToUTF( UTF_ENCOD_UTF8, srcstr, len( *srcstr ) + 1, NULL, @chars )
Print chars
for i=0 to chars
Print hex(*(utfstr+i));
next i
Print
dim as wstring ptr newstr
newstr = UTFToWChar( UTF_ENCOD_UTF8, utfstr, NULL, @chars )
Print chars
Print *newstr, "w - string"
print chars, *newstr
assert( *newstr = *srcstr )
deallocate( newstr )
deallocate( utfstr )
end scope3、FreeBASIC utf-8与unicode转换示例程序3:
如果传输使用的是 utf-8,则char 需要转换成 utf-8,避字符错乱。
scope '' UTF <-> zstring
dim as zstring ptr srcstr = @"abc"
dim as byte ptr utfstr
dim as integer bytes
utfstr = CharToUTF( UTF_ENCOD_UTF8, srcstr, len( *srcstr ) + 1, NULL, @bytes )
dim as zstring ptr newstr
newstr = UTFToChar( UTF_ENCOD_UTF8, utfstr, NULL, @bytes )
print bytes, *newstr
assert( *newstr = *srcstr )
deallocate( newstr )
deallocate( utfstr )
end scope个人学习总结:
从GB2312到GB18030,汉字在信息交换标准化方面做了很大努力,是unicode的重要组成部分,但unicode站位不同,是Linux系普遍采纳的地球村符号编码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









