






数据库的概念
在计算机中, 通过一定的结构,来组织,存储和管理数据的软件系统
数据库管理系统(Database Management System,简称DBMS)是为管理数据库而设计的电脑软件系统,一般具有存储、截取、安全保障、备份等基础功能
数据库的分类
关系型数据库
非关系型数据库
数据库操作
DDL(数据库定义语言)
数据库
创建
CREATE DATABASE IF NOT EXISTS test CHARACTER SET utf8;
删除
DROP DATABASE test;
查看
-- 查看服务中心所有的数据库
SHOW DATABASES;
-- 查看数据库创建细节
SHOW CREATE DATABASE test;
选择
USE test;
数据表
创建
CREATE TABLE course (
tc_id INT(20) NOT NULL PRIMARY KEY,
tc_name VARCHAR(20) NOT NULL,
tt_id INT(20) NOT NULL
)
修改表
-- 修改表名
ALTER TABLE user RENAME TO t_user;
ALTER TABLE user RENAME AS t_user;
-- 设置表编码
ALTER TABLE t_user CHARACTER SET utf8;
-- 添加列ADD
ALTER TABLE t_user ADD high INT (20) NOT NULL;
-- 修改Modify(重新定义)
ALTER TABLE t_user MODIFY high INT (20) NOT NULL;
-- 更换列的位置
ALTER TABLE <表名> MODIFY <列名> VARCHAR (20) AFTER <列名2>-- 重新放置某列之后
ALTER TABLE <表名> MODIFY <列名> VARCHAR (20) FIRST-- 将某列放在表结构的第一列
-- 修改列名
ALTER TABLE <表名> CHANGE <原列名> <新列名> VARCHAR (200)
-- 删除列
ALTER TABLE <表名> DROP COLUMN <列名>;
删除
DROP TABLE <表名>
查看
-- 查看表结构
DESC <表名>;
DESCRIBE <表名>;
SHOW COLUMNSF ROM <表名>;
SHOW [FULL] FIELDS FROM <表名>
-- 查看创建语句
SHOW CREATE TABLE <表名>;
DML(数据操纵语言)
添加记录
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
INSERT INTO TABLE_NAME(F1,F2,F3) SELECT (E1,E2,E3) FROM TABLE WHERE.....
修改记录
UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE Clause]
删除记录
DELETE FROM table_name [WHERE Clause]
DQL(数据查询语言)
简单查询
完整语法
select * from 表名
where 筛选条件
group by 分组字段1, 分组字段2
having 分组筛选条件
order by 排序字段1, 排序字段2
limit 起点, 数量
别名AS
重复数据合并(去除重复的查询结果)
distinct
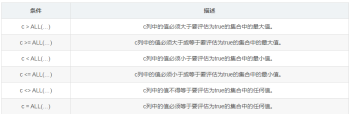
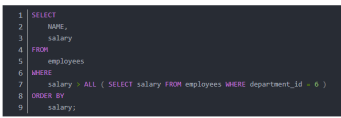
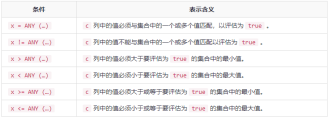
WHERE




子查询
- 在增删改查的SQL中, 包含了另一个查询语句
多表联查


行列转换
CASE WHEN
select uname,uid, -- 正常查询的字段
sum(
case
when course ='英语' then score -- 需要转换的字段
else 0
end) '英语',
sum(
case
when course= '物理' then scoreelse 0
end) '物理',
sum(
case course
when '化学' then score
else 0
end) '化学'
from course
group by uid
if (字段名1=‘字段值’,,)
select uname,uid,
sum(if(`course`='英语',score,0)) '英语',
sum(if(`course`='物理',score,0)) '物理',
sum(if(`course`='化学',score,0)) '化学'
from course
group by uname
DCL(数据控制语言)
数据库工具
视图
MySQL 视图(View)是一种虚拟存在的表,同真实表一样,视图也由列和行构成,但视图***并不实际存在于数据库中***。行和列的数据来自于定义视图的查询中所使用的表,并且还是在使用视图时动态生成的。
数据库中只存放了视图的定义,并没有存放视图中的数据,这些数据都存放在定义视图查询所引用的真实表中。使用视图查询数据时,数据库会从真实表中取出对应的数据。
视图操作
创建视图
CREATE VIEW <视图名> AS <SELECT语句>
创建的视图和基本表的字段是一样的,也可以通过指定视图字段的名称来创建视图
CREATE VIEW v_students_info (
s_id,s_name
) AS SELECT
id,NAME
FROM
tb_students_info;
查看视图定义(类似查看表)
DESCRIBE 视图名;
SHOW CREATE VIEW 视图名;(语句)
修改视图定义
ALTER VIEW <视图名> AS <SELECT语句>
修改视图名称
-- 修改视图的名称可以先将视图删除,然后按照相同的定义语句进行视图的创建,并命名为新的视图名称
删除视图
DROP VIEW IF EXISTS <视图名1> [ , <视图名2> …]
可以像表一样进行CURD操作, 但增删改的操作受限在这里插入代码片
- 单表操作,只要有表的权限即可
- 多表操作,可以将一条语句分成多个语句
对视图的操作会作用到物理表上
用户可以通过视图来插入、更新、删除表中的数据,因为视图是一个虚拟的表,没有数据。通过视图更新时转到基本表上进行更新,如果对视图增加或删除记录,实际上是对基本表增加或删除记录。INSERT INTO v (a_id, v1) VALUES (3, 30);和INSERT INTO v (b_id, ta_id, v2) VALUES (5, 3, 500);
视图优点
-
定制用户数据,聚焦特定的数据
不同的用户可能对不同的数据有不同的要求.
-
简化数据操作
在使用查询时,很多时候要使用聚合函数,同时还要显示其他字段的信息,可能还需要关联到其他表,语句可能会很长,如果这个动作频繁发生的话,可以创建视图来简化操作。
- 提高数据的安全性
视图是虚拟的,物理上是不存在的。可以只授予用户视图的权限,而不具体指定使用表的权限,来保护基础数据的安全。 这里是引用
- 共享所需数据
通过使用视图,每个用户不必都定义和存储自己所需的数据,可以共享数据库中的数据,同样的数据只需要存储一次。
- 更改数据格式
通过使用视图,可以重新格式化检索出的数据
要注意区别视图和数据表的本质,即视图是基于真实表的一张虚拟的表,其数据来源均建立在真实表的基础上。
触发器
是嵌入到 MySQL 中的一段程序,通过对数据表的相关操作来触发、激活从而实现执行。比如当对 student 表进行操作(INSERT,DELETE 或 UPDATE)时就会激活它执行
触发时机
- 进行增删改查时
- 在操作之前Before,操作之后After
-新数据 new,旧数据old
触发器优点
- 触发器的执行是自动的,当对触发器相关表的数据做出相应的修改后立即执行。
- 触发器可以实施比 FOREIGN KEY 约束、CHECK 约束更为复杂的检查和操作。
- 触发器可以实现表数据的级联更改,在一定程度上保证了数据的完整性。
触发器的缺点
- 使用触发器实现的业务逻辑在出现问题时很难进行定位,特别是涉及到多个触发器的情况下,会使后期维护变得困难。
- 大量使用触发器容易导致代码结构被打乱,增加了程序的复杂性
- 如果需要变动的数据量较大时,触发器的执行效率会非常低
创建触发器
CREATE TRIGGER <触发器名> < BEFORE | AFTER ><INSERT | UPDATE | DELETE >ON <表名> FOR EACH Row BEGIN <触发器主体> END
注意:在命令行中要使用delimiter来重新定义结束符一般临时使用**$$**
删除触发器
DROP TRIGGER [ IF EXISTS ] [数据库名] <触发器名>
new和old
CREATE TRIGGER tr1
BEFORE UPDATE ON t22
FOR EACH ROW
BEGIN
SET @old = OLD.s1;
SET @new = NEW.s1;
END;
索引
索引是对数据库表中一列或多列的值进行排序的一种结构。MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
索引类型
普通索引
是最基本的索引,它没有任何限制
- 直接创建索引
CREATE INDEX index_name ON table(column(length索引长度))
- 修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
- 创建表的时候同时创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX index_name (title(length)) )
- 删除索引
DROP INDEX index_name ON table
唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
- 创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))
- 修改表结构的方式添加索引
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
- 创建表的时直接指定
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
UNIQUE indexName (title(length)) );
主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
组合索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
- 直接创建全文索引
CREATE FULLTEXT INDEX index_content ON table_name(content)
- 修改表结构的时候添加全文索引
ALTER TABLE article ADD FULLTEXT index_content(content)
- 创建表的时候添加全索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
FULLTEXT (content) );
索引的缺点
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行insert、update和delete。因为更新表时,不仅要保存数据,还要保存一下索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会增长很快。
- 索引只是提高效率的一个因素,如果有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
索引注意事项
索引不会包含有null值的列
只要列中包含有null值都将不会被包含在索引中,复合索引中只要有一列含有null值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为null。
使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
索引列排序
当引用表的查询包含用以指定索引中键列的不同方向的 ORDER BY 子句时, 指定键值存储在该索引中的顺序很有用. 在这些情况下, 索引就无需在查询计划中使用 SORT 运算符.
like语句操作
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like“%aaa%” 不会使用索引而like“aaa%”可以使用索引。
不要在列上进行运算
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<2017;
不使用not in和<>操作
索引失效
- 有or必全表索引;
- 复合索引未用左列字段;
- like以%开头;
- 需要类型转换;
- where中索引列有运算;
- where中索引列使用了函数;
- 如果mysql觉得全表扫描更快时(数据少);
没必要使用索引的情况
- 唯一性差;
一个字段的取值只有几种时,的字段不要使用索引
比如性别,只有两种可能数据。 - 频繁更新的字段不用(更新索引消耗);
比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。 - where中不用的字段;
如果where后含IS NULL /IS NOT NULL/ like ‘%输入符%’等条件,不建议使用索引 - 索引使用(不等于)<>时,效果一般;
索引的原理
「平衡树」(非二叉),也就是b tree或者 b+ tree
事务
概念: 一组不可分割的数据库操作, 要么全执行, 要么全不执行
例如:银行卡转账
ACID四大特性
原子性(atomicity)
事务内的操作是一个整体,要么执行成功,要么执行失败
一致性(consistency)
事务执行前后,数据库状态保持一致
以银行转账事务事务为例。在事务开始之前,所有账户余额的总额处于一致状态。在事务进行的过程中,一个账户余额减少了,而另一个账户余额尚未修改。因此,所有账户余额的总额处于不一致状态。事务完成以后,账户余额的总额再次恢复到一致状态。
隔离性(isolation)
多个事务并发的时候,事务之间不能相互影响
持久性(durability)
事务一旦执行成功,随数据库的影响是持久的
执行事务的语法和流程
- 开始事务
BEGIN;或者START TRANSACTION;
- 提交事务
COMMIT;
- 回滚(撤销)事务
ROLLBACK;
并发访问数据混乱
脏读
一个事务读取到了另外一个事务修改未提交的记录
例如:数据表中一条记录值为v1, 事务A执行, 将值改为v2, 但并没有提交, 此时事务B读取, 如果读取到的记录值为v2, 则为脏读
幻读
一个事务读取到了另外一个事务添加未提交的记录
例如: 事务A向表中添加了记录r1, 并没有提交, 此时事务B读取数据表,如果能够查到记录r1, 即为幻读
不可重复读
一个事务两次读取的记录数据不一致
例如: 事务A开启, 查找数据表记录r1, 并未提交, 此时事务B修改记录r1, 并提交, 事务A再次查找数据表记录r1, 如果两次得到的r1不一致, 即为不可重复读
事务的隔离级别

- 查看当前会话隔离级别
select @@tx_isolation;
- 查看系统当前隔离级别
select @@global.tx_isolation;
- 设置当前会话隔离级别
set session transaction isolatin level repeatable read;
- 设置系统当前隔离级别
set global transaction isolation level repeatable read;[read uncommitted||read committed||repeatable read(mysql 默认)||serializable]
锁的类型
事务并发处理类似于线程并发的同步处理, 都是通过锁来实现的,MySQL中的锁是在服务器层或者存储引擎层实现的,保证了数据访问的一致性与有效性。

函数和存储过程
MySQL引擎
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧等功能,使用不同的存储引擎,还可以 获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。
查看可用的存储引擎
SHOW ENGINES
查看数据库默认使用的引擎
SHOW VARIABLES LIKE 'storage_engine';
MyISAM存储引擎和INNODB存储引擎的对比:
MyISAM不支持事务 INNODB支持事务
MyISAM不支持外键 INNODB支持外键
MYISAM加锁读取 INNODB不加锁读取
MyISAM支持全文索引 INNODB不支持全文索引
MyISAM查询速度更快 INNODB添加、修改、删除速度更快
InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。
- InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
- InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
- InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上
- InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
- InnoDB被用在众多需要高性能的大型数据库站点上
MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有***较高的插入、查询速度***,但不支持事务
- 大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持
- 当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成
- 每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
- 最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上
- BLOB和TEXT列可以被索引
- NULL被允许在索引的列中,这个值占每个键的0~1个字节
- 所有数字键值以高字节优先被存储以允许一个更高的索引压缩
- 每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快
- 可以把数据文件和索引文件放在不同目录
- 每个字符列可以有不同的字符集
- 有VARCHAR的表可以固定或动态记录长度
- VARCHAR和CHAR列可以多达64KB
MEMORY存储引擎
Memory存储引擎将表的数据存放在内存中。每个MEMORY表实际对应一个磁盘文件,格式是.frm ,该文件中只存储表的结构,而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。MEMORY 类型的表访问非常地快,因为他的数据是存放在内存中的,并且默认使用HASH索引 , 但是服务一旦关闭,表中的数据就会丢失。
- MEMORY表的每个表可以有多达32个索引,每个索引16列,以及500字节的最大键长度
- MEMORY存储引擎执行HASH和BTREE缩影
- 可以在一个MEMORY表中有非唯一键值
- MEMORY表使用一个固定的记录长度格式
- MEMORY不支持BLOB或TEXT列
- MEMORY支持AUTO_INCREMENT列和对可包含NULL值的列的索引
- MEMORY表在所由客户端之间共享(就像其他任何非TEMPORARY表)
- MEMORY表内存被存储在内存中,内存是MEMORY表和服务器在查询处理时的空闲中,创建的内部表共享
- 当不再需要MEMORY表的内容时,要释放被MEMORY表使用的内存,应该执行DELETE FROM或TRUNCATE
TABLE,或者删除整个表(使用DROP TABLE)
ARCHIVE存储引擎
这个引擎只允许插入和查询,不允许修改和删除。相当于拥有只读权限和写入权限,没有修改权限和删除权限。
















 1448
1448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









