






新样本循环写入csv中
def write_sample(self):
# 创建一个包含所有字段的列表,它将作为CSV的一行
fields = ['基地', '拉线', '正/负极车间', '罐体编号', '样本ID', '工步序号', '检测结果']
row_data = [self.base_id, self.line_id, self.workshop_id, self.device, self.filename[:-4], self.step_number, self.abnormal_id]
# 检查文件是否存在
if not os.path.exists(os.path.join(self.sample_count_path, str(self.step_number)+ '_sample_count.csv')):
# 如果文件不存在,则创建它并写入表头
with open(os.path.join(self.sample_count_path, str(self.step_number)+ '_sample_count.csv'), 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(fields) # 写入表头
writer.writerow(row_data) # 写入第一行数据
else:
# 如果文件存在,则追加新行
with open(os.path.join(self.sample_count_path, str(self.step_number)+ '_sample_count.csv'), 'a', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(row_data) # 追加新行
虽然上述代码实现了样本的循环写入,但同样遇到了一个问题,就是中文乱码如下:
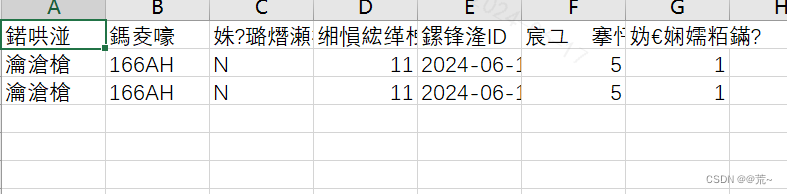
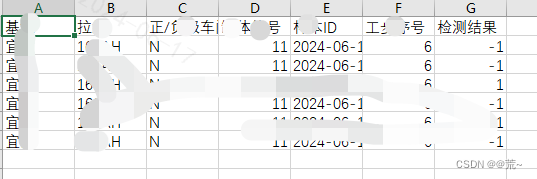
为了解决上述问题,需要修改代码,将写入文件的编码格式由utf-8改为utf-8-sig
修改后的结果如下:
产生的原因
问题产生的原因是由于在写入 CSV 文件时,使用了 utf-8 编码,但 Excel 默认使用 BOM(字节顺序标记)来标识文件编码。在某些情况下(如内容包含了中文内容),将可能导致 Excel 中显示的文件内容出现乱码。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









