







apache Iceberg
Apache Iceberg分享
1. Iceberg概念与原理
1.1 大数据的趋势

当前大数据发展的三大趋势:
- 数据仓库往数据湖方向发展
- 批处理往流式处理发展
- 本地部署往云模式发展
数据湖具备哪些特性呢?
- 同时支持流批处理
- 支持数据更新
- 支持事务(ACID)
- 可扩展的元数据
- 数据质量保障
- 支持多种存储引擎
- 支持多种计算引擎
1.2 Apache Iceberg的原理
一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。
核心思想:在时间轴上跟踪表的所有变化。
1.2.1 Iceberg原理简介
优化数据入库流程:Iceberg 提供 ACID 事务能力,上游数据写入即可见,不影响当前数据处理任务,这大大简化了 ETL;Iceberg 提供了 upsert、merge into 能力,可以极大地缩小数据入库延迟;
支持更多的分析引擎:目前 Iceberg 支持的计算引擎有 Spark、Flink、Presto 以及 Hive。
统一数据存储和灵活的文件组织:提供了基于流式的增量计算模型和基于批处理的全量表计算模型。批处理和流任务可以使用相同的存储模型,数据不再孤立;Iceberg 支持隐藏分区和分区进化,方便业务进行数据分区策略更新。支持 Parquet、Avro 以及 ORC 等存储格式。
增量读取处理能力:Iceberg 支持通过流式方式读取增量数据,支持 Structed Streaming 以及 Flink table Source。
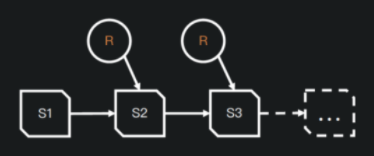
- 快照隔离
- 基于文件列表的所有修改都是原子操作
- 实现基于快照的跟踪方式
- 表的元数据是不可修改的,并且始终向前迭代
- 当前的快照可以回退。
1.2.2 Iceberg简介
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Trino and Spark that use a high-performance format that works just like a SQL table.
——设计初衷是:以类似于SQL的形式高性能的处理大型的开放式表。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









