







文章目录
TiDB-SQL操作
https://pingcap.com/docs-cn/stable/reference/mysql-compatibility/
成功部署 TiDB 集群之后,便可以在 TiDB 中执行 SQL 语句了。因为 TiDB 兼容 MySQL,可以使用 MySQL 客户端连接 TiDB,并且大多数情况下可以直接执行 MySQL 语句。
mysql -h 127.0.0.1 -P 4000 -u root
show databases;
创建、查看和删除数据库
1、要创建一个名为 samp_db 的数据库,可使用以下语句。
CREATE DATABASE IF NOT EXISTS samp_db;2、使用 SHOW DATABASES 语句查看数据库。
SHOW DATABASES;3、使用 DROP DATABASE 语句删除数据库。
DROP DATABASE samp_db;4、再次查看数据库。
SHOW DATABASES;
创建、查看和删除表
1、先创建一个库。
CREATE DATABASE IF NOT EXISTS samp_db; USE samp_db;2、使用 SHOW TABLES 语句查看数据库中的所有表。
SHOW TABLES FROM samp_db;3、使用 CREATE TABLE 语句创建表。
如果表已存在,添加 IF NOT EXISTS 可防止发生错误。CREATE TABLE IF NOT EXISTS person ( number INT(11), name VARCHAR(255), birthday DATE );4、使用 SHOW CREATE 语句查看建表语句。
SHOW CREATE table person;5、使用 SHOW FULL COLUMNS 语句查看表的列。
SHOW FULL COLUMNS FROM person;6、使用 DROP TABLE 语句删除表。
DROP TABLE person;或者
DROP TABLE IF EXISTS person;
创建、查看和删除索引
1、先创建一张表。
CREATE TABLE IF NOT EXISTS person ( number INT(11), name VARCHAR(255), birthday DATE );2、对于值不唯一的列,可使用 CREATE INDEX 或 ALTER TABLE 语句。
CREATE INDEX person_num ON person (number);或者
ALTER TABLE person ADD INDEX person_num (number);3、使用 SHOW INDEX 语句查看表内所有索引。
SHOW INDEX from person;4、使用 ALTER TABLE 或 DROP INDEX 语句来删除索引。与 CREATE INDEX 语句类似,DROP INDEX 也可以嵌入 ALTER TABLE 语句。
DROP INDEX person_num ON person; ALTER TABLE person DROP INDEX person_num;5、对于值唯一的列,可以创建唯一索引。
CREATE UNIQUE INDEX person_num ON person (number);或者
ALTER TABLE person ADD UNIQUE person_num (number);
增删改查数据
1、使用 INSERT 语句向表内插入数据。
INSERT INTO person VALUES("1","tom","20170912");2、使用 SELECT 语句检索表内数据。
SELECT * FROM person;3、使用 UPDATE 语句修改表内数据。
UPDATE person SET birthday='20200202' WHERE name='tom'; SELECT * FROM person;4、使用 DELETE 语句删除表内数。
DELETE FROM person WHERE number=1; SELECT * FROM person;
创建、授权和删除用户
1、使用 CREATE USER 语句创建一个用户 tiuser,密码为 123456。
CREATE USER 'tiuser'@'localhost' IDENTIFIED BY '123456';2、授权用户 tiuser 可检索数据库 samp_db 内的表。
GRANT SELECT ON samp_db.* TO 'tiuser'@'localhost';3、查询用户 tiuser 的权限。
SHOW GRANTS for tiuser@localhost;4、删除用户 tiuser。
DROP USER 'tiuser'@'localhost';5、查看所有权限。
SHOW GRANTS;
TiDB-读取历史数据
接下来介绍 TiDB 如何读取历史版本数据,包括具体的操作流程以及历史数据的保存策略。
功能说明
TiDB 实现了通过标准 SQL 接口读取历史数据功能,无需特殊的 client 或者 driver。当数据被更新、删除后,依然可以通过 SQL 接口将更新/删除前的数据读取出来。
另外即使在更新数据之后,表结构发生了变化,TiDB 依旧能用旧的表结构将数据读取出来。
操作流程
为支持读取历史版本数据, 引入了一个新的 system variable: tidb_snapshot ,这个变量是 Session 范围有效,可以通过标准的 Set 语句修改其值。其值为文本,能够存储 TSO 和日期时间。TSO 即是全局授时的时间戳,是从 PD 端获取的; 日期时间的格式可以为: “2020-10-08 16:45:26.999”,一般来说可以只写到秒,比如”2020-10-08 16:45:26”。 当这个变量被设置时,TiDB 会用这个时间戳建立 Snapshot(没有开销,只是创建数据结构),随后所有的 Select 操作都会在这个 Snapshot 上读取数据。
注意:TiDB 的事务是通过 PD 进行全局授时,所以存储的数据版本也是以 PD 所授时间戳作为版本号。在生成 Snapshot 时,是以 tidb_snapshot 变量的值作为版本号,如果 TiDB Server 所在机器和 PD Server 所在机器的本地时间相差较大,需要以 PD 的时间为准。
当读取历史版本操作结束后,可以结束当前 Session 或者是通过 Set 语句将 tidb_snapshot 变量的值设为 “",即可读取最新版本的数据。
历史数据保留策略
TiDB 使用 MVCC 管理版本,当更新/删除数据时,不会做真正的数据删除,只会添加一个新版本数据,所以可以保留历史数据。历史数据不会全部保留,超过一定时间的历史数据会被彻底删除,以减小空间占用以及避免历史版本过多引入的性能开销。
TiDB 使用周期性运行的 GC(Garbage Collection,垃圾回收)来进行清理,关于 GC 的详细介绍参见 TiDB 垃圾回收 (GC)。
这里需要重点关注的是 tikv_gc_life_time 和 tikv_gc_safe_point 这条。tikv_gc_life_time 用于配置历史版本保留时间,可以手动修改;tikv_gc_safe_point 记录了当前的 safePoint,用户可以安全地使用大于 safePoint 的时间戳创建 snapshot 读取历史版本。safePoint 在每次 GC 开始运行时自动更新。
示例
1、初始化阶段,创建一个表,并插入几行数据。
create table t (c int); insert into t values (1), (2), (3);2、查看表中的数据。
select * from t; +------+ | c | +------+ | 1 | | 2 | | 3 | +------+3、查看当前时间。
select now(); +---------------------+ | now() | +---------------------+ | 2021-01-11 14:05:26 | +---------------------+4、更新某一行数据。
update t set c=22 where c=2;5、确认数据已经被更新。
select * from t; +------+ | c | +------+ | 1 | | 22 | | 3 | +------+6、设置一个特殊的环境变量,这个是一个 session scope 的变量,其意义为读取这个时间之前的最新的一个版本。
set @@tidb_snapshot="2021-01-11 14:05:26";注意:这里的时间设置的是 update 语句之前的那个时间。
在 tidb_snapshot 前须使用 @@ 而非 @,因为 @@ 表示系统变量,@ 表示用户变量。
7、这里读取到的内容即为 update 之前的内容,也就是历史版本。select * from t; +------+ | c | +------+ | 1 | | 2 | | 3 | +------+8、清空这个变量后,即可读取最新版本数据。
set @@tidb_snapshot=""; select * from t; +------+ | c | +------+ | 1 | | 22 | | 3 | +------+注意:在 tidb_snapshot 前须使用 @@ 而非 @,因为 @@ 表示系统变量,@ 表示用户变量。
整合Spark-TiSpark
准备数据
向 TiDB 集群中插入一些样本数据:
docker-compose exec tispark-master bash
cd /opt/spark/data/tispark-sample-data
mysql -h tidb -P 4000 -u root < dss.ddl
启动Spark shell
当样本数据加载到 TiDB 集群之后,访问 Spark shell。
docker-compose exec tispark-master /opt/spark/bin/spark-shell
执行Spark代码
scala>
import org.apache.spark.sql.TiContext
…
scala>val ti = new TiContext(spark)
…
scala>ti.tidbMapDatabase("TPCH_001")
…
scala>spark.sql("select count(*) from lineitem").show
±-------+
|count(1)|
±-------+
| 60175|
±-------+
下面执行另一个复杂一点的 Spark SQL:
scala>spark.sql( """select | l_returnflag, | l_linestatus, | sum(l_quantity) as sum_qty, | sum(l_extendedprice) as sum_base_price, | sum(l_extendedprice * (1 - l_discount)) as sum_disc_price, | sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge, | avg(l_quantity) as avg_qty, | avg(l_extendedprice) as avg_price, | avg(l_discount) as avg_disc, | count(*) as count_order |from | lineitem |where | l_shipdate <= date '1998-12-01' - interval '90' day |group by | l_returnflag, | l_linestatus |order by | l_returnflag, | l_linestatus """.stripMargin).show结果为:
你也可以通过 Python 或 R 来访问 Spark:docker-compose exec tispark-master /opt/spark/bin/pyspark && docker-compose exec tispark-master /opt/spark/bin/sparkR

数据迁移-TiDB Lightning
MySQL --> TiDB
TiDB Lightning介绍
TiDB Lightning 是一个将全量数据高速导入到 TiDB 集群的工具,目前支持 Mydumper 或 CSV 输出格式的数据源。你可以在以下两种场景下使用 Lightning:
- 迅速导入大量新数据。
- 备份恢复所有数据。
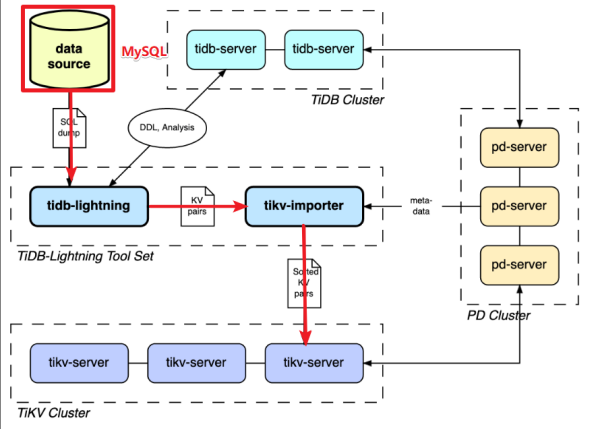
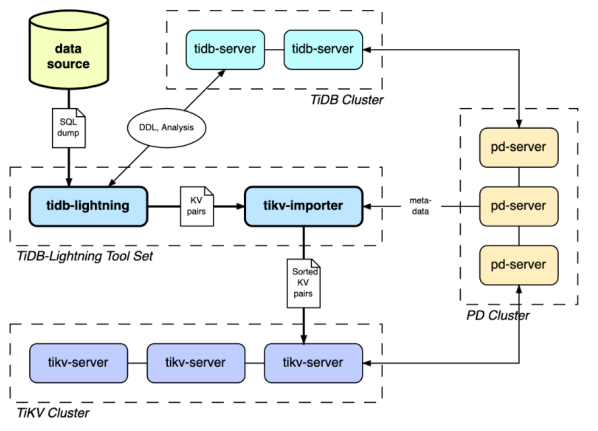
TiDB Lightning 主要包含两个部分:
- tidb-lightning(“前端”):主要完成适配工作,通过读取数据源,在下游 TiDB 集群建表、将数据转换成键/值对 (KV 对) 发送到 tikv-importer、检查数据完整性等。
- tikv-importer(“后端”):主要完成将数据导入 TiKV 集群的工作,把 tidb-lightning 写入的 KV 对缓存、排序、切分并导入到 TiKV 集群。
准备迁移工具
wget https://download.pingcap.org/tidb-enterprise-tools-latest-linux-amd64.tar.gz
wget https://download.pingcap.org/tidb-toolkit-latest-linux-amd64.tar.gz
准备MySQL数据
CREATE DATABASE mytest;
USE mytest;
CREATE TABLE mytest.t1 (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c CHAR (32),
PORT INT
);
insert into t1 values (),(),(),(),(),(),(),();
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
insert into t1 (id) select null from t1;
update t1 set c=md5(id), port=@@port;
CREATE TABLE mytest.t2 (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c CHAR (32),
PORT INT
);
insert into t2 values (),(),(),(),(),(),(),();
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
insert into t2 (id) select null from t2;
update t2 set c=md5(id), port=@@port;
导出数据
mkdir -p /data/my_database/
cd tidb-enterprise-tools-latest-linux-amd64/bin/
./mydumper -h 127.0.0.1 -P 3306 -u root -p Root@1234 -t 16 -F 256 -B mytest -T t1,t2 --skip-tz-utc -o /data/my_database/
cd /data/my_database
其中:
- -B mytest :从 mytest 数据库导出。
- -T t1,t2:只导出 t1 和 t2 这两个表。
- -t 16:使用 16 个线程导出数据。
- -F 256:将每张表切分成多个文件,每个文件大小约为 256 MB。
- –skip-tz-utc:添加这个参数则会忽略掉 TiDB 与导数据的机器之间时区设置不一致的情况,禁止自动转换。
这样全量备份数据就导出到了/data/my_database目录中。
启动tikv-importer
cd tidb-toolkit-v4.0.9-linux-amd64/bin/
vim tikv-importer.toml
# TiKV Importer 配置文件模版
# 日志文件。
log-file = "tikv-importer.log"
# 日志等级:trace、debug、info、warn、error、off。
log-level = "info"
[server]
# tikv-importer 监听的地址,tidb-lightning 需要连到这个地址进行数据写入。
addr = "192.168.19.130:8287"
[import]
# 存储引擎文档 (engine file) 的文件夹路径。
import-dir = "/mnt/ssd/data.import/"
nohup ./tikv-importer -C tikv-importer.toml > nohup.out &
启动tidb-lightning
vim run.sh
#!/bin/bash
nohup ./tidb-lightning \
--importer 192.168.19.130:8287 \
-d /data/my_database/ \
--pd-urls 0.0.0.0:2379 \
--tidb-host 192.168.19.130 \
--tidb-user root \
--log-file tidb-lightning.log \
> nohup.out &
chmod 755 run.sh
./run.sh
注意
有性能要求,使用单机版测试即可
systemctl stop docker
cd tidb-v4.0.9-linux-amd64/
./bin/pd-server --data-dir=pd --log-file=pd.log &
./bin/tikv-server --pd="127.0.0.1:2379" --data-dir=tikv --log-file=tikv.log &
./bin/tidb-server --store=tikv --path="127.0.0.1:2379" --log-file=tidb.log &















 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









