







综述论文“Towards Personalized Federated Learning”分享
文章目录
这篇论文《Towards Personalized Federated Learning》探讨了在联邦学习中实现个性化模型的策略。
论文地址:https://arxiv.org/abs/2103.00710
摘要——随着人工智能(AI)研究的进展,AI的应用正在快速普及,与此同时,数据隐私的意识和担忧也在不断增加。最近在数据监管领域的重要发展促使了对隐私保护AI的广泛关注。这也推动了联邦学习(FL)的普及,FL 是一种在保护隐私的前提下对数据孤岛进行机器学习模型训练的主流范式。在本次综述中,我们探讨了个性化联邦学习(PFL)领域,以应对FL在异构数据上的基本挑战,这是所有现实世界数据集的普遍特征。我们分析了PFL的主要动机,并提出了一种独特的PFL技术分类法,依据PFL中的关键挑战和个性化策略对其进行分类。我们突出介绍了这些技术的核心思想、挑战和机遇,并展望了未来研究的潜在方向,包括新的PFL架构设计、现实的PFL基准测试以及可信赖的PFL方法。
关键词——联邦学习,个性化联邦学习,非独立同分布(non-IID)数据,统计异质性,隐私保护,边缘计算
I. 引言
现代社会中边缘设备的普及,例如手机和可穿戴设备,导致了来自分布式来源的私人数据的迅速增长。在这个数字时代,组织正在利用大数据和人工智能(AI)来优化他们的流程和性能。虽然这些数据为AI应用提供了巨大的机会,但大多数数据具有高度敏感性,并且通常以孤立的形式存在。这在医疗行业尤为相关,医疗数据高度敏感,通常在不同的医疗机构之间收集并存储 [1]–[4]。这种情况对AI的采用带来了巨大挑战,因为传统的AI方法无法很好地解决数据隐私问题。随着近期《通用数据保护条例》(GDPR)等数据隐私保护法律的引入 [5],对隐私保护AI的需求日益增长 [6],以满足监管要求。
鉴于这些数据隐私的挑战,近年来联邦学习(FL) [7] [8] 越来越受到关注。FL 是一种学习范式,允许多个数据孤岛在隐私保护的前提下协同训练机器学习模型。流行的FL设置假设存在一组数据所有者(即客户),其规模可以小至个人移动设备,也可以大至整个组织,他们在中央参数服务器(即FL服务器) [7] [8] 的协调下共同训练模型。训练数据存储在本地,在训练过程中不会直接共享。现有的大多数FL训练方法都是基于在文献 [9] 中提出的联邦平均(FedAvg)算法。其目标是训练一个能够在大多数FL客户上表现良好的全局模型。
A. 联邦学习的分类
联邦学习(FL)可以根据参与实体间特征和样本空间的数据分布情况,分为水平联邦学习(HFL)、垂直联邦学习(VFL)和联邦迁移学习(FTL)[7]。HFL指的是参与者共享相同的特征空间但拥有不同的数据样本。这是最常见的FL设置,谷歌通过HFL在移动设备上训练语言模型,使其广为流行 [9]。在VFL中,参与者有重叠的数据样本,但特征空间不同。一个典型的应用场景是来自不同行业部门的多个组织(例如银行和电商公司)合作,这些组织有不同的数据特征,但可能拥有大量共同的用户。FTL适用于参与者在特征空间和样本空间上几乎没有重叠的情况。例如,来自不同行业部门、服务于不同地区市场的组织可以利用FTL协作构建模型。现有的个性化联邦学习(PFL)研究主要集中在HFL设置上,后者占据了大多数FL应用场景 [8]。本论文的重点也是HFL设置。为简洁起见,在本综述的其余部分中,我们将HFL和FL的术语互换使用。
B. 个性化联邦学习的动机
图1展示了集中式机器学习(CML)[10]、联邦学习(FL)和个性化联邦学习(PFL)的核心概念和动机。我们考虑一个基于云的CML设置,在该设置中,数据汇集在云服务器中用于训练机器学习模型。在这种情况下,CML模型可以通过大量数据实现良好的泛化能力。然而,CML由于需要将大量数据传输到云端,面临带宽和延迟的挑战。它也无法保护数据隐私,且个性化能力较差。
FL假设有一组分布式客户端,每个客户端都有自己的私人本地数据集。由于这些客户端的数据稀缺,限制了其训练有效本地模型的能力,它们被激励加入FL过程以获得性能更好的模型。FL允许在数据孤岛上进行协同模型训练,且具备隐私保护能力,这使得它不同于CML设置。此外,FL在通信方面更高效,因为它仅传输模型参数,而非原始数据,传输数据的规模要小得多。考虑到隐私和通信的限制,FL适用于支持广泛的应用场景,例如物联网(IoT),该场景涉及隐私、连接性、带宽和延迟等在不同边缘计算环境中的挑战 [11]。
然而,通用的FL方法面临几个基本挑战:(i)在高度异构数据上收敛性较差,(ii)缺乏个性化解决方案。这些问题在异构本地数据分布的情况下,会降低全局FL模型在单个客户端上的表现,甚至可能使受影响的客户端不愿加入FL过程。相比传统FL,PFL研究旨在解决这两个挑战。
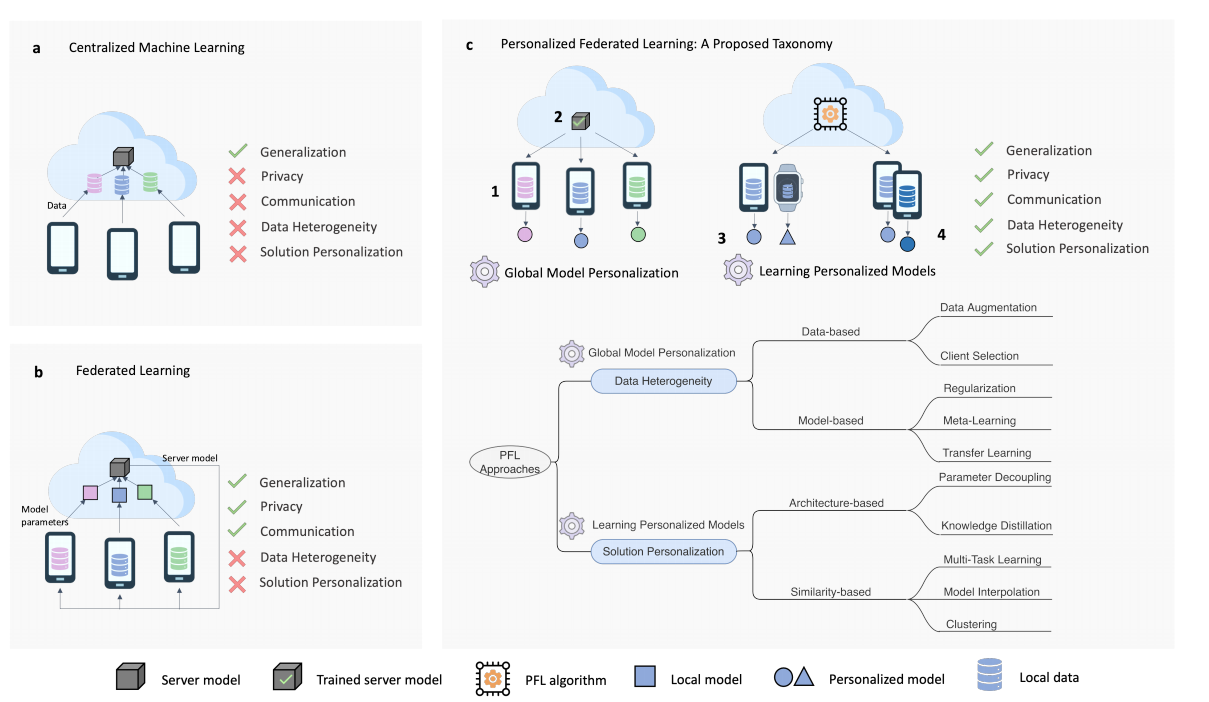
图1:个性化联邦学习的概念、动机及提出的分类法。a. 集中式机器学习(CML):将数据汇集在一起,用于训练中央机器学习模型。 b. 联邦学习(FL):在中央参数服务器的协调下训练全局模型,数据保存在不同的数据孤岛中。 c. 个性化联邦学习(PFL):通过全局模型个性化和个性化模型学习,解决FL的局限性。1–4 是PFL方法的四大类: 1.基于数据的, 2.基于模型的, 3.基于架构的, 4.基于相似性的。
1.异构数据上的收敛性差: 在非独立同分布(non-IID)数据上进行学习时,FedAvg 的准确率显著降低。这种性能下降归因于客户端漂移现象 [12],这是由在非IID的本地数据分布上进行多轮本地训练和同步所导致的。图2展示了客户端漂移在IID和non-IID数据上的影响。在FedAvg中,服务器的更新趋向于客户端最优解的平均值。当数据为IID时,平均模型接近全局最优解 w ∗ w^* w∗,因为它与本地最优解 w 1 ∗ w_1^* w1∗和 w 2 ∗ w_2^* w2∗的距离相等。然而,当数据为non-IID时,全局最优解 w ∗ w^* w∗并不与本地最优解等距。在此示例中, w ∗ w^* w∗更接近于 w 2 ∗ w_2^* w2∗。因此,平均模型 w t + 1 w^{t+1} wt+1将会远离全局最优解 w ∗ w^* w∗,而全局模型无法收敛到其真正的全局最优解。由于FedAvg算法在non-IID数据上存在收敛问题,因此需要仔细调整超参数(例如学习率衰减)来提高学习的稳定性 [13]。
2.缺乏解决方案的个性化: 在传统FL设置中,训练一个单一的全局共享模型来适应“平均客户端”。因此,全局模型无法很好地泛化到与全局分布非常不同的本地分布上。单一模型通常不足以应对实际应用中经常遇到的non-IID本地数据集。以应用FL开发手机键盘语言模型为例,不同人口统计学群体的用户由于代际、语言和文化差异,可能会有不同的使用模式。某些词语或表情符号可能主要被特定群体的用户使用。在这种场景下,为每个用户提供更个性化的预测模式才能使词语建议更加有意义。
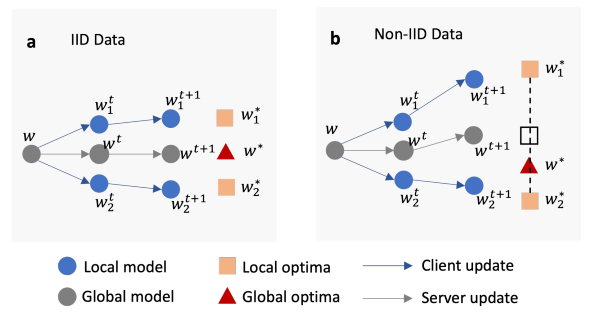
图2:FedAvg中客户端漂移的示例,显示两个客户端的两个本地步骤。a) IID数据设置。b) non-IID数据设置。
C. 贡献
已有若干综述探讨了联邦学习(FL)的一般概念、方法及其应用 [7], [14]。其他研究从隐私 [15] 和鲁棒性 [16] 的角度对FL进行了回顾。我们的综述专注于个性化联邦学习(PFL),该领域研究在FL环境下处理统计异质性问题的个性化模型学习。当前缺乏关于PFL的全面综述,系统性地为新研究人员提供关于这一重要话题的视角。本文填补了现有FL文献中的这一空白。我们的主要贡献总结如下:
- 我们提供了FL及其分类的简要概述,并详细分析了当前FL设置下PFL的主要动机。
- 我们识别了应对FL关键挑战的个性化策略,并从基于数据、基于模型、基于架构和基于相似性的角度提供了独特的视角,用于引导对PFL文献的回顾。基于此视角,我们提出了一个层次化分类法,以展示现有的PFL研究工作,重点介绍它们所面临的挑战、主要思想以及可能引入局限性的假设。
- 我们讨论了当前文献中常用的公共数据集和评估指标,用于PFL基准测试,并提出了改进PFL实验评估技术的建议。
- 我们展望了未来研究的潜在方向,包括新的架构设计、现实的基准测试以及构建可信个性化联邦学习系统的方式。
II. 个性化联邦学习的策略
在本节中,我们概述了个性化联邦学习(PFL)策略,这些策略是我们系统且全面回顾现有PFL方法的基础。我们根据提出的分类法(图1c)对文献进行整理,按照涉及的关键挑战和个性化策略对PFL方法进行分类。
策略I:全局模型个性化
第一个策略解决了在异质数据上训练全局共享FL模型时的性能问题。当在非独立同分布(non-IID)数据上进行学习时,基于FedAvg的方法由于客户端漂移(client drift)而导致准确率显著下降。在全局模型个性化中,PFL设置与通用FL训练过程紧密相关,训练一个全局FL模型。然后,通过本地适应步骤对每个FL客户端的全局模型进行个性化,这一步骤涉及在每个本地数据集上进行额外的训练。此类“FL训练 + 本地适应”的双步骤方法通常被FL社区视为一种个性化策略 [8], [17]。由于个性化性能直接取决于全局模型在数据异质性下的泛化性能,许多PFL方法旨在提高全局模型在数据异质性条件下的性能,以便为之后的本地数据个性化提供更好的基础。个性化技术可分为基于数据和基于模型的方法。基于数据的方法旨在通过减少客户端数据集之间的统计异质性来缓解客户端漂移问题,而基于模型的方法则旨在为未来的个性化学习一个强大的全局模型,或者提高本地模型的适应性能。
策略II:学习个性化模型
第二个策略解决了解决方案个性化的挑战。与训练单一全局模型的全局模型个性化策略不同,此类方法训练个性化的FL模型。目标是通过修改FL模型聚合过程来构建个性化模型,这通过在FL设置中应用不同的学习范式来实现。个性化技术分为基于架构和基于相似性的方法。基于架构的方法旨在为每个客户端提供定制的个性化模型架构,而基于相似性的方法旨在利用客户端之间的关系来提高个性化模型的性能,即为相关客户端构建相似的个性化模型。
在个性化FL模型训练中,优化目标与传统的FL设置不同,因为每个客户端学习一个个性化的模型。我们提供了FL和本地学习设置下的优化目标公式,以突出PFL方法的定位。标准FL目标为:
min
w
∈
R
d
F
(
w
)
:
=
1
C
∑
c
=
1
C
f
c
(
w
)
,
\min_{w \in \mathbb{R}^d} F(w) := \frac{1}{C} \sum_{c=1}^{C} f_c(w),
w∈RdminF(w):=C1c=1∑Cfc(w),
其中,
C
C
C是参与客户端的数量,
w
∈
R
d
w \in \mathbb{R}^d
w∈Rd编码全局模型的参数,且
f
c
(
w
)
:
=
E
(
x
,
y
)
∼
D
c
[
f
c
(
w
;
x
,
y
)
]
f_c(w) := \mathbb{E}_{(x,y)\sim D_c}[f_c(w; x, y)]
fc(w):=E(x,y)∼Dc[fc(w;x,y)]
表示客户端
c
c
c的数据分布
D
c
D_c
Dc上的期望损失。现行的FL公式最小化局部函数的聚合,并使用全局模型为所有客户端生成统一的输出,而不进行个性化。在数据异质性(即客户端之间的数据分布不相同)的情况下,简单地最小化平均局部损失而不进行个性化将导致较差的性能。
在另一个极端,我们考虑本地学习设置,其中每个客户端 c c c本地训练自己的模型 $\theta_c $,而不与其他客户端进行通信。目标为:
min
θ
1
,
.
.
.
,
θ
c
∈
R
d
F
(
θ
)
:
=
1
C
∑
c
=
1
C
f
c
(
θ
c
)
,
\min_{\theta_1, ..., \theta_c \in \mathbb{R}^d} F(\theta) := \frac{1}{C} \sum_{c=1}^{C} f_c(\theta_c),
θ1,...,θc∈RdminF(θ):=C1c=1∑Cfc(θc),
其中,$\theta_c \in \mathbb{R}^d $编码客户端
c
c
c的本地模型参数。在这种设置下,所得到的模型可能无法实现良好的泛化性能,因为本地模型所接触的训练样本数量有限。通过加强客户端之间的协作以利用知识库进行模型训练,可以获得更强的泛化保证。
对比标准FL和本地学习设置的公式,标准FL促进了客户端之间的协作和知识共享,但不涉及个性化输出,因为它依赖于共享的全局模型进行客户端推理。而本地学习则为每个客户端提供完全个性化的模型,但未能利用跨客户端协作可能带来的性能提升。
鉴于需要在泛化和个性化性能之间取得平衡,PFL方法位于标准FL设置和本地学习设置之间。
III. 策略I:全局模型个性化
在本节中,我们回顾了基于全局模型个性化策略的PFL方法。图3展示了这些方法的主要设置和配置。根据我们提出的分类法,它们分为基于数据的方法和基于模型的方法。
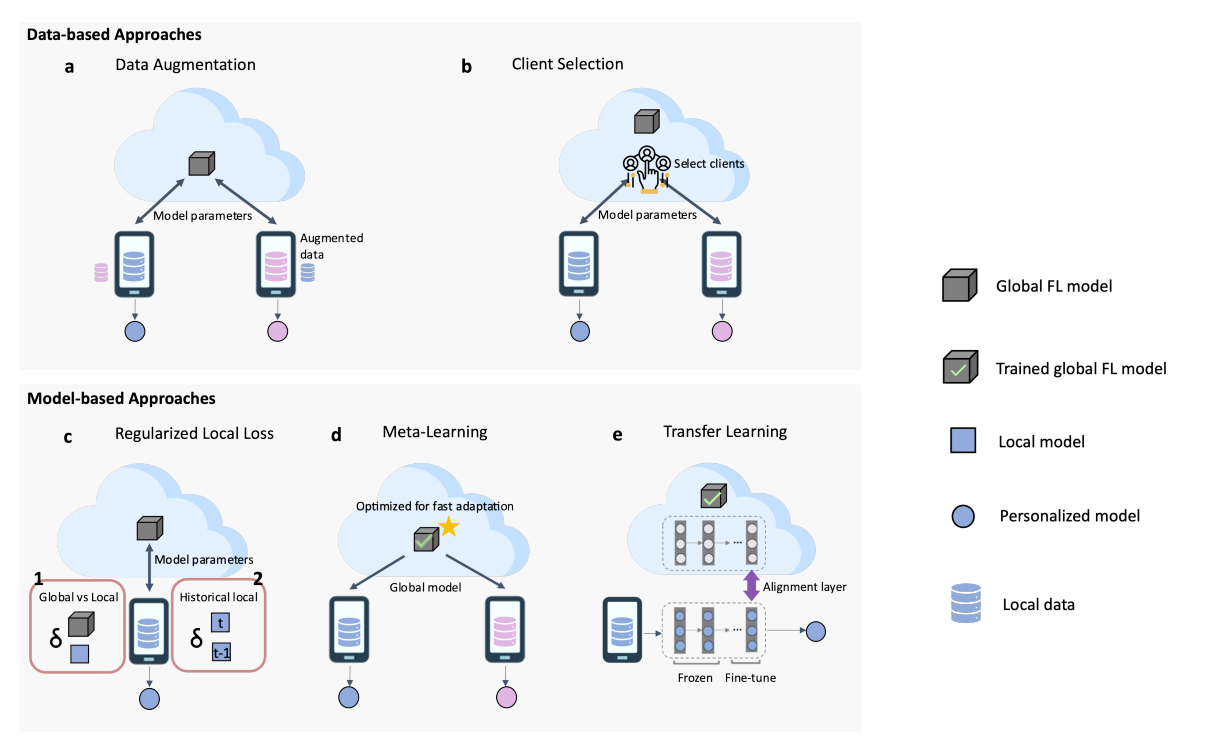
图3描述了属于策略I(全局模型个性化)方法的设置与配置。
a–b. 基于数据的方法:
- (a) 数据增强(data augmentation):通过增强本地数据来减少异质性问题,如生成新的样本或扩展现有数据集。
- (b) 客户端选择(client selection):通过选择特定客户端进行训练,优化全局模型的训练过程,从而减少数据分布不均导致的性能下降。
c–e. 基于模型的方法:
-
(c ) 正则化本地损失(regularized local loss):正则化可在以下两个维度进行:
- 在全局模型与本地模型之间进行正则化,以确保本地模型不会偏离全局模型。
- 在历史本地模型快照之间进行正则化,以避免模型在本地数据上过拟合。
-
(d) 元学习(meta-learning):通过元学习提高全局模型的适应性,使其更容易适应本地数据的个性化需求。
-
(e) 迁移学习(transfer learning):通过从预训练的全局模型中迁移知识,使每个客户端能够快速适应其特定的数据分布。
这些设置和配置展示了如何在全局模型的基础上,通过不同的策略和方法,实现个性化的联邦学习。
A. 数据驱动方法
受到联邦学习(FL)在异构数据上训练时产生的客户端漂移问题的启发,数据驱动的方法旨在减少客户端数据分布的统计异构性。这有助于提高全局FL模型的泛化性能。
数据增强
由于独立同分布(IID)属性是统计学习理论中的基本假设,因此数据增强方法被广泛研究,以增强数据的统计同质性。过采样技术(如SMOTE [18] 和 ADASYN [19])以及欠采样技术(如Tomek links [20])已被提出,以减少数据不平衡。然而,这些技术不能直接应用于FL设置中,因为在联邦中客户端的数据是分布式且私密的。
在FL中进行数据增强(图3a)非常具有挑战性,因为这通常需要某种形式的数据共享,或者依赖于能够代表整体数据分布的代理数据集。文献[21] 提出了一种数据共享策略,将少量按类别平衡的全局数据分发给每个客户端。他们的实验表明,加入少量数据可以显著提高准确率(约30%)。在文献[22] 中,作者提出了FAug,一种联邦增强方法,它涉及在FL服务器上训练一个生成对抗网络(GAN)模型。一些少数类的数据样本被上传到服务器上,以训练GAN模型。然后,将训练好的GAN模型分发给每个客户端,用于生成额外的数据,来增强其本地数据,形成一个IID数据集。在文献[23] 中,作者提出了Astraea,一种自平衡的FL框架,通过使用基于Z分数的数据增强和本地数据的下采样来处理类不平衡问题。FL服务器需要获取客户端本地数据分布的统计信息(如类别大小、均值和标准差)。在文献[24] 中,作者提出了FedHome算法,它通过FL训练一个生成卷积自动编码器(GCAE)模型。在FL过程结束时,每个客户端在一个本地增强的类平衡数据集上进一步进行个性化调整。这个数据集是通过在基于本地数据的编码器网络低维特征上执行SMOTE算法生成的。
客户端选择
另一种方法侧重于设计FL客户端选择机制,以便在每轮训练中从更均匀的数据分布中进行采样,目的是改善模型的泛化性能(图3b)。在文献[25] 中,作者提出了FAVOR,它通过在每轮训练中选择一个参与客户端的子集来减轻非IID数据引入的偏差。一个基于深度Q学习的客户端选择机制被设计出来,目标是最大化准确率,同时最小化通信轮数。在类似的研究中,文献[26] 提出了一个基于多臂老虎机(Multi-Armed Bandit)模型的客户端选择算法,以选择类不平衡最小的客户端子集。通过将上传到FL服务器的本地梯度更新与服务器上平衡代理数据集推断的梯度进行比较,估算本地类分布。
最近,有一系列新兴的研究工作专注于开发客户端选择策略,以应对在边缘计算应用中普遍存在的数据和资源异构性挑战。对于跨设备的FL,硬件能力(如计算和通信能力)通常存在显著差异。数据的异构性也体现在不同客户端之间数据的数量和分布上。这种多样性加剧了诸如通信成本、掉队客户端(stragglers)和模型准确性等问题。在文献[27] 中,作者提出了一个基于分层的FL系统(TiFL),它根据训练性能将客户端分为不同的层次。该算法通过优化准确性和训练时间,适应性地从同一层次中选择参与的客户端,以缓解由数据和资源异构性引起的性能问题。在文献[28] 中,作者提出了FedSAE,一个自适应FL系统,每轮自适应地选择本地训练损失较大的客户端,以加速全局模型的收敛。还提出了一种预测每个客户端可承受工作负载的机制,以实现每个客户端本地训练轮数的动态调整,从而提高设备的可靠性。
B. 基于模型的方法
虽然基于数据的方法通过减轻客户端漂移问题来改善全局联邦学习(FL)模型的收敛性,但它们通常需要修改本地数据分布。这可能导致与客户端行为的固有多样性相关的宝贵信息丢失,而这些信息可以用于个性化全局模型以适应每个客户端。在本节中,我们讨论了基于模型的全局模型个性化FL方法。其目标是为每个客户端学习一个强大的全局FL模型,以便未来个性化,或提高本地模型的适应性能。
正则化的本地损失
模型正则化是防止过拟合并在训练机器学习模型时提高收敛性的常用策略。在FL中,正则化技术可以用于限制本地更新的影响,从而提高收敛稳定性并提升全局模型的泛化性能,进而产生更好的个性化模型。每个客户端 c c c除了最小化本地函数 f c ( θ ) f_c(\theta) fc(θ),还要最小化如下目标:
min
θ
∈
R
d
h
c
(
θ
;
w
)
:
=
f
c
(
θ
)
+
l
reg
(
θ
;
w
)
\min_{\theta \in \mathbb{R}^d} h_c(\theta; w) := f_c(\theta) + l_{\text{reg}}(\theta; w)
θ∈Rdminhc(θ;w):=fc(θ)+lreg(θ;w)
其中
l
reg
(
θ
;
w
)
l_{\text{reg}}(\theta; w)
lreg(θ;w)是正则化损失,通常表示为全局模型
w
w
w和客户端本地模型
θ
c
\theta_c
θc的函数。正则化可以通过以下几种方式实现(如图3c所示):
-
全局模型与本地模型之间的正则化:为了解决由于统计数据异构性导致的客户端漂移问题,许多工作在全局和本地模型之间实施了正则化。FedProx [29] 引入了一个邻近项来考虑全局FL模型与本地模型之间的差异,以调整本地更新的影响。FedCL [30] 在正则化本地损失函数中使用了连续学习领域的弹性权重合并(Elastic Weight Consolidation, EWC)[31] 来进一步考虑参数的重要性。参数的重要性在FL服务器上通过代理数据集进行估算,随后传输到客户端,以防止在适应本地数据时改变全局模型的重要参数。SCAFFOLD [12] 最近通过使用方差缩减来缓解客户端漂移的影响,防止本地和全局模型之间的权重偏差。
-
历史本地模型快照之间的正则化:最近提出了一种基于对比学习的FL——MOON [32]。MOON的目标是减少本地模型与全局模型之间的表示差距,同时增加给定本地模型与其之前本地模型之间的表示距离,以加速收敛。此方法允许每个客户端学习一个接近全局模型的表示,以最小化本地模型的差异,并通过鼓励本地模型改进其之前版本来加速学习。
元学习
元学习(“学习如何学习”)旨在通过接触多种任务(即数据集)来改善学习算法,使模型能够快速高效地学习新任务。基于优化的元学习算法,如模型无关元学习(Model-Agnostic Meta-Learning, MAML)[34] 和 Reptile [35],以其良好的泛化能力和对新异构任务的快速适应性而著称。它们也是模型无关的,可以应用于任何基于梯度下降的方法,支持监督学习和强化学习的应用。
在文献[36] 中,作者将元学习与FL进行了类比。元学习算法分为两个阶段:元训练和元测试。作者将MAML中的元训练步骤映射到FL全局模型训练过程,将元测试步骤映射到FL个性化过程,即在本地适应期间对本地数据执行几步梯度下降。他们还表明,FedAvg与Reptile算法是等价的,当所有客户端拥有相同数量的本地数据时,两者的目标是相同的。
Per-FedAvg [37] 是基于MAML形式化的FedAvg变体,其目标是学习一个良好的初始全局模型,以便在新任务上进行个性化:
min
w
∈
R
d
F
(
w
)
:
=
1
C
∑
c
=
1
C
f
c
(
w
−
α
∇
f
c
(
w
)
)
\min_{w \in \mathbb{R}^d} F(w) := \frac{1}{C} \sum_{c=1}^C f_c(w - \alpha \nabla f_c(w))
w∈RdminF(w):=C1c=1∑Cfc(w−α∇fc(w))
其中
α
>
0
\alpha > 0
α>0是步长。该目标与FedAvg的优化目标不同,它转变为学习一个适用于异构任务的初始全局模型,从而在本地数据上经过几步梯度下降后表现良好。
迁移学习
迁移学习(TL)常用于非联邦学习环境中的模型个性化,旨在将知识从源域转移到目标域。迁移学习是通过利用预训练模型中的知识来避免从头构建模型的一种高效方法。FedMD [42] 是基于迁移学习和知识蒸馏的FL框架,允许客户端使用其私有数据设计独立模型。在FL训练和知识蒸馏阶段之前,首先使用公共数据集对模型进行预训练。
领域自适应技术通常用于实现个性化FL,这些技术旨在减少全局FL模型(源域)与本地模型(目标域)之间的域差异,以提高个性化效果。
总结
在本节中,我们讨论了用于全局模型个性化的数据驱动方法和模型驱动方法。现在,我们将个性化技术的优缺点进行总结和比较(如表 I 所示)。
数据驱动方法旨在减少客户端数据分布的统计异质性,以解决客户端漂移问题。数据增强方法在常规FL训练过程中易于实施,但其适用性受到一定限制,因为现有设计中并未充分解决数据共享带来的隐私泄露问题。训练过程中通常会共享客户端数据分布的样本或统计信息。这可能带来隐私风险。
客户端选择方法通过优化每轮FL通信中参与的客户端子集来提升模型的泛化性能。然而,这些方法需要计算密集型算法(如深度Q学习和多臂老虎机算法),因此相比于FedAvg计算开销更高。此外,许多数据驱动方法假设可以获得一个代表全局数据分布的代理数据集,而构建这样的代理数据集需要了解全局数据分布,这在FL场景中由于隐私保护的要求非常具有挑战性。
模型驱动方法通常遵循常规的FL训练过程,训练单一的全局模型。正则化方法(如FedProx和MOON)易于实现,仅需对FedAvg算法进行轻微修改。元学习通过优化全局模型以实现快速个性化,但由于计算二阶梯度的开销较大,通常需要使用梯度近似。迁移学习通过减少全局模型和本地模型之间的域差异来改善个性化效果。
上述方法均假设在异构数据场景下训练单一全局模型,因此当客户端数据分布差异显著时,不太适合解决个性化问题。此外,模型驱动方法通常假设所有客户端和FL服务器使用共同的模型架构。这一假设要求客户端具备足够的计算和通信资源,而边缘计算的FL客户端往往资源受限,使得这些方法在这种情况下不太适用。
表 I:全局模型个性化中的个性化技术总结。
| 方法 | 优点 | 缺点 |
|---|---|---|
| 数据增强 | • 易于实现,可以基于常规的FL训练流程构建 | • 可能存在隐私泄露的风险 • 可能需要一个具有代表性的代理数据集 |
| 客户端选择 | • 仅需修改常规FL训练流程中的客户端选择策略 | • 客户端子集优化可能增加计算开销 • 可能需要一个具有代表性的代理数据集 |
| 正则化 | • 易于实现,对FedAvg算法的修改较少 | • 只适用于单一全局模型设置 |
| 元学习 | • 优化全局模型以实现快速个性化 | • 只适用于单一全局模型设置 • 计算二阶梯度的开销较大 |
| 迁移学习 | • 通过减少全局模型与本地模型之间的域差异来提高个性化效果 | • 只适用于单一全局模型设置 |
IV. 策略二:学习个性化模型
在本节中,我们回顾了遵循学习个性化模型策略的个性化联邦学习(PFL)方法。这些方法的主要设置和配置如图4所示。根据我们提出的分类法,它们分为基于架构的方法和基于相似性的方法,具体如下。
A. 基于架构的方法
基于架构的PFL方法通过为每个客户端定制的模型设计来实现个性化。参数解耦方法为每个客户端实现个性化层,而知识蒸馏方法则支持每个客户端的个性化模型架构。
参数解耦 Parameter Decoupling
参数解耦旨在通过将本地私有模型参数与全局联邦学习(FL)模型参数解耦来实现PFL。私有参数在客户端本地训练,并且不与FL服务器共享。这使得能够为增强个性化而学习任务特定的表示。私有和联邦模型参数之间的划分是架构设计决策。通常在深度前馈神经网络中,参数解耦有两种常见配置(如图4a所示)。第一种配置是由[46]提出的“基础层+个性化层”设计。在这种设置中,个性化的深度层由客户端保留进行本地训练,以学习个性化的任务特定表示,而基础层则与FL服务器共享,以学习低层次的通用特征。
第二种设计考虑为每个客户端设计个性化特征表示。在[47]中,一个使用双向LSTM架构的文档分类模型通过FL进行训练,将用户嵌入作为私有模型参数,而字符嵌入(即LSTM和MLP层)作为FL模型参数。在[48]中,提出了局部全局联邦平均(LG-FedAvg)方法,将本地表示学习与全局联邦训练相结合。学习低维本地表示有助于提高联邦全局模型训练的通信和计算效率。同时,这种方法也提供了灵活性,因为可以根据源数据的类型(如图像、文本)设计特定的编码器。作者还展示了如何通过将对抗学习融入FL模型训练,学习对受保护属性(如种族、性别)不变的公平和无偏表示。
由于参数解耦与分割学习(SL)[49]、[50]有一些相似性,我们在此简要讨论它们的区别。在SL中,深度网络在服务器和客户端之间按层划分。与参数解耦不同,SL中的服务器模型不会传输到客户端进行模型训练。相反,在前向传播过程中,客户端模型的划分层权重会被共享,而在反向传播过程中,划分层的梯度则与客户端共享。因此,SL在隐私方面相比FL有优势,因为服务器和客户端无法完全访问全局和本地模型[51]。然而,由于需要顺序客户端训练,SL的训练效率较低。在非独立同分布(non-IID)数据上的表现也较差,且通信开销较大[52]。
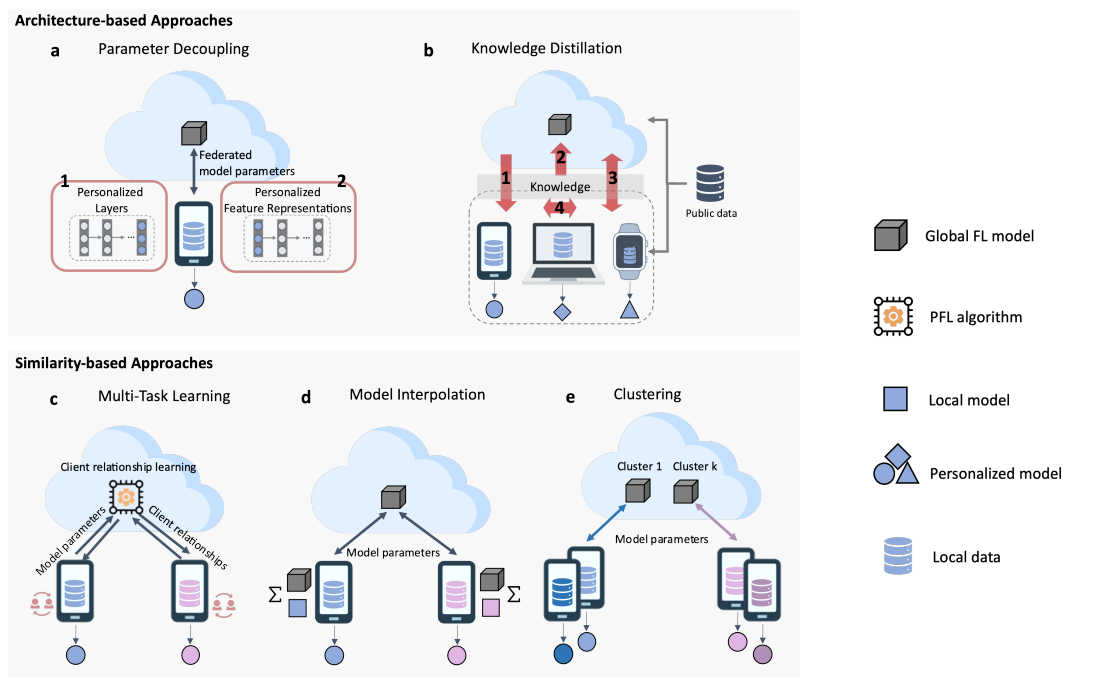
图4:策略二——学习个性化模型的方法设置与配置。 a–b 基于架构的方法: (a) 参数解耦:参数私有化设计包括 1) 个性化层,2) 个性化特征表示。 (b) 知识蒸馏:知识可以蒸馏至 1) 客户端,2) 服务器,3) 客户端和服务器,4) 客户端之间。 c–e 基于相似性的方法: © 多任务学习,(d) 模型插值,(e) 聚类。
知识蒸馏 Knowledge Distillation
在基于服务器的横向联邦学习(HFL)中,FL服务器和FL客户端采用相同的模型架构。其假设前提是客户端具备足够的通信带宽和计算能力。然而,在实际应用中,许多作为FL客户端的边缘设备通常资源有限,或者由于不同的训练目标,客户端可能选择不同的模型架构。知识蒸馏在FL中的主要动机是提高灵活性,以支持客户端的个性化模型架构,同时通过减少资源需求来应对通信和计算能力的挑战。
知识蒸馏(KD)最初由[54]提出,作为将多个教师模型的知识转移到轻量级学生模型的一种范式。在现有的FL蒸馏方法中,知识通常以类分数或logit输出的形式表示。总体上,基于蒸馏的FL架构有四种主要类型:(i) 将知识蒸馏给每个FL客户端以学习更强的个性化模型,(ii) 将知识蒸馏给FL服务器以学习更强的服务器模型,(iii) 双向蒸馏到FL客户端和服务器,(iv) 客户端之间的蒸馏(见图4b)。
在[42]中,作者提出了FedMD,这是一个基于蒸馏的FL框架,允许客户端通过知识蒸馏使用自己的私有数据设计多样的模型。学习通过在公共数据集上的平均类分数计算共识进行。每一轮通信时,客户端首先基于更新的共识在公共数据集上训练模型,随后在私有数据集上微调模型。这使得每个客户端能够获得个性化模型,同时利用来自其他客户端的知识。在[55]中,作者提出了FedGen,一个无数据蒸馏框架,通过蒸馏将知识传递给FL客户端。生成模型在FL服务器上训练,并广播给客户端。然后,每个客户端利用所学习的知识生成增强的特征表示,作为归纳偏差来调控本地学习。
在[56]中,作者提出了FedDF算法,它假设边缘客户端由于计算能力的差异需要不同的模型架构。FL服务器构建了p个不同的原型模型,每个模型代表具有相同架构的客户端(例如ResNet,MobileNet)。每轮通信时,首先在来自相同原型组的客户端中执行FedAvg,以初始化学生模型。接着,跨架构学习通过集成蒸馏进行,即客户端(教师)模型参数在未标记的公共数据集上进行评估,生成的logit输出用于训练FL服务器中的每个学生模型。
知识也可以在同一FL训练过程中,在FL客户端和服务器之间以双向的方式进行蒸馏。在[57]中,作者提出了组知识转移(FedGKT),以提高资源受限边缘设备的模型个性化表现。它使用交替最小化方法,通过双向蒸馏训练小型边缘模型和大型服务器模型。大型服务器模型以本地模型提取的特征作为输入,并使用KL散度损失最小化真实标签和本地模型预测的软标签之间的差异。通过这种方式,服务器模型吸收了从本地模型传递的知识。同样,每个本地模型使用其私有数据集和服务器传递的预测软标签计算KL散度损失,从而促进知识从服务器模型到本地模型的转移。通过这种双向蒸馏框架,计算负担从边缘客户端转移到更强大的FL服务器。然而,存在潜在的隐私风险,因为每个客户端的真实标签会被上传到FL服务器。
基于KD的PFL也可以在分布式环境中进行,其中知识在网络中相邻的客户端之间传递。在[58]中,作者提出了一个与架构无关的分布式算法——D-Distillation,用于设备端学习。假设一个IoT边缘FL环境,每个边缘设备只与几个相邻设备连接,只有连接的设备之间可以进行通信。该学习算法是半监督的,局部训练在私有数据上进行,联邦训练在未标记的公共数据集上进行。在每轮通信中,每个客户端向其邻居广播其软决策,同时接收邻居的软决策广播。然后,每个客户端基于邻居的软决策通过共识算法更新自己的软决策。更新后的软决策随后用于通过正则化本地损失来更新客户端的模型权重。这一过程通过网络中相邻FL客户端之间的知识转移促进了模型学习。
B. 基于相似性的个性化方法
基于相似性的个性化方法旨在通过建模客户端之间的关系实现个性化。每个客户端都会学习一个个性化的模型,且相关的客户端会学习到相似的模型。在个性化联邦学习(PFL)中,研究了多种不同类型的客户端关系。多任务学习(MTL)和模型插值(Model Interpolation)关注客户端之间的成对关系,而聚类方法则研究客户端群体的整体关系。
多任务学习(MTL)
多任务学习(MTL)的目标是训练一个可以同时执行多个相关任务的模型。这种方法通过在多个学习任务之间共享领域特定知识来提高模型的泛化能力。将每个联邦学习(FL)客户端视为MTL中的一个任务,可以学习并捕捉客户端之间因其异构本地数据所表现出的关系(见图4c)。MOCHA算法 [59] 将分布式多任务学习扩展到了FL场景中。MOCHA使用了原始对偶公式来优化学习到的模型。该算法解决了FL中常见的通信和系统挑战,而这些问题在传统MTL中并未得到充分考虑。与常规的FL设计不同,MOCHA为每个FL客户端学习一个个性化的模型。虽然MOCHA提高了个性化能力,但它并不适合跨设备的FL应用,因为它要求所有客户端在每轮FL模型训练中都参与。此外,MOCHA仅适用于凸模型,因此不适合深度学习的实现。这一限制促使 [60] 提出了VIRTUAL联邦多任务学习算法,该算法采用贝叶斯方法进行变分推断。尽管它可以处理非凸模型,但对于大规模FL网络而言,其计算成本较高。
在 [61] 中,作者提出了FedAMP,一种基于注意力机制的算法,该算法通过对具有相似数据分布的FL客户端施加更强的成对协作来实现个性化。与标准的FL框架不同,FedAMP在服务器上为每个客户端维护一个个性化的云模型
u
c
u_c
uc。个性化云模型定义为:
u
c
=
ξ
c
,
1
θ
1
+
ξ
c
,
2
θ
2
+
⋯
+
ξ
c
,
m
θ
m
u_c = \xi_{c,1} \theta_1 + \xi_{c,2} \theta_2 + \cdots + \xi_{c,m} \theta_m
uc=ξc,1θ1+ξc,2θ2+⋯+ξc,mθm其中,
∑
m
∈
C
ξ
c
,
m
=
1
\sum_{m \in C} \xi_{c,m} = 1
∑m∈Cξc,m=1。在每轮通信中,个性化的云模型
u
c
u_c
uc 被传输到客户端
c
c
c,用于在其本地数据上进行训练。本地权重的计算方式为:
θ
c
∗
=
arg
min
θ
∈
R
d
f
c
(
θ
)
+
μ
2
α
∥
θ
−
u
c
∥
2
\theta_c^* = \arg \min_{\theta \in \mathbb{R}^d} f_c(\theta) + \frac{\mu}{2\alpha} \|\theta - u_c\|^2
θc∗=argθ∈Rdminfc(θ)+2αμ∥θ−uc∥2
其中,
α
\alpha
α 是梯度下降的步长。
FedCurv [62] 使用弹性权重守恒(EWC)来防止跨任务学习时的灾难性遗忘。通过Fisher信息矩阵估算参数的重要性,并执行惩罚步骤以保留重要参数。在每轮通信结束时,每个客户端会将其更新后的本地参数和Fisher信息矩阵的对角线发送给服务器。这些参数将在下一轮训练中共享给所有客户端,用于本地训练。
模型插值 Model Interpolation
在 [63] 中,作者提出了一种新公式,该公式通过全局和本地模型的混合学习个性化模型,从而在泛化和个性化之间取得平衡。每个FL客户端学习一个个性化的本地模型。通过引入惩罚参数 λ \lambda λ,限制本地模型与平均模型的过度差异。当 λ = 0 \lambda = 0 λ=0 时,发生纯本地模型学习,即每个客户端仅在本地训练模型,不与其他客户端通信。这等价于公式 (3) 中的完全个性化FL设置,在这种情况下,每个客户端本地训练自己的模型。当 λ \lambda λ 增大时,混合模型学习发生,本地模型变得越来越相似。当 λ \lambda λ 接近无穷大时,这种设置接近于全局模型学习,此时所有本地模型被迫相同。通过这种方式,可以控制个性化的程度。此外,作者还提出了一种名为“无循环局部梯度下降”(L2GD)的通信高效的SGD变体。该变体通过一个确定是否执行局部梯度下降步骤或模型聚合步骤的概率框架,大幅减少了通信轮次。
在相关工作中,文献 [64] 提出了APFL算法,目的是以通信高效的方式找到全局和本地模型的最佳组合。他们为每个客户端引入了一个在FL训练过程中自适应学习的混合参数,用于控制全局和本地模型的权重。这使得每个客户端都可以学习到最佳的个性化程度。如果本地数据和全局数据分布不一致,局部模型的权重预计会更大,反之亦然。在 [17] 中也提出了类似的公式,该公式通过全局和本地模型的联合优化来确定最佳的插值权重。
最近,文献 [65] 提出了HeteroFL框架,它通过基于单个全局模型的不同复杂性级别来训练本地模型。通过根据客户端的计算和通信能力自适应地分配不同复杂性的本地模型,该框架在边缘计算场景中实现了个性化FL,解决了系统异构性问题。
聚类 Clustering
对于存在固有分区的客户端或数据分布显著不同的应用场景,采用客户端-服务器的FL架构训练共享的全局模型并不是最佳选择。更适合的做法是针对每个同质客户端组训练一个FL模型的多模型方法(见图4e)。近年来,多个研究集中于FL个性化的聚类方法。聚类基础的FL的基本假设是客户端的本地数据分布存在自然分组。
在 [66] 中,层次聚类被作为FL的后处理步骤引入。基于客户端梯度更新的余弦相似度的最优二分算法用于将FL客户端划分为不同的聚类。由于需要多轮通信才能分离所有不一致的客户端,这种递归的二分聚类框架会产生高昂的计算和通信成本,限制了其在大规模场景中的实际可行性。另一种针对FL的层次聚类框架在 [67] 中被提出。该框架使用聚合层次聚类的公式,将聚类减少为单一步骤,以降低计算和通信负担。该过程首先为 t t t 轮通信训练一个全局FL模型。然后在所有客户端的私有数据集上微调该全局模型,以确定全局模型参数 w w w 与本地模型参数 θ c \theta_c θc 之间的差异 Δ w \Delta w Δw。所有客户端的 Δ w \Delta w Δw 值作为输入,传递给聚合层次聚类算法以生成多个客户端聚类。然后对每个客户端聚类独立执行FL训练,以生成多个联邦模型。这种方法适用于更广泛的非独立同分布(non-IID)场景,并允许在每轮FL模型训练中对一部分客户端进行训练。然而,在聚合聚类中计算所有客户端之间的成对距离在客户端数量较多时可能会消耗大量计算资源。
其他聚类方法要求在FL训练开始时设定固定数量的聚类。在 [68] 中,作者提出了迭代联邦聚类算法(IFCA)。服务器构建 K K K 个全局模型,而不是单个全局模型,并将这些模型广播给所有客户端以进行本地损失计算。每个客户端被分配到一个 K K K 个聚类中,其中全局模型在客户端数据上达到最低损失值。然后,服务器在聚类分区内执行基于聚类的FL模型聚合。与FedAvg相比,IFCA的通信开销高出 K K K 倍,因为服务器需要在每轮通信中向所有客户端广播 K K K 个聚类模型。
在 [69] 中,作者提出了基于社区的FL(CBFL),用于预测患者住院时间和死亡率。他们训练了一个去噪自编码器,并基于其私有数据的编码特征进行预定数量聚类的K-means聚类。然后,为每个聚类训练一个FL模型。在 [70] 中,作者提出了FedGroup,这是一个FL聚类框架,实施静态客户端聚类策略和新来客户端的冷启动机制。FedGroup使用K-means++算法 [71] 基于分解余弦相似度(EDC)的欧几里得距离,对本地客户端更新进行聚类。
在 [72] 中,作者提出了一种多中心公式,该公式学习多个全局模型。它引入了一种基于距离的多中心损失函数:
L
=
1
K
∑
k
=
1
K
∑
c
=
1
C
r
c
(
k
)
Dist
(
θ
c
,
w
(
k
)
)
L = \frac{1}{K} \sum_{k=1}^{K} \sum_{c=1}^{C} r_c^{(k)} \text{Dist}(\theta_c, w^{(k)})
L=K1k=1∑Kc=1∑Crc(k)Dist(θc,w(k))
其中
r
c
(
k
)
r_c^{(k)}
rc(k) 表示客户端
c
c
c 被分配到聚类
k
k
k,而
w
(
k
)
w^{(k)}
w(k) 是聚类
k
k
k 的模型参数。使用期望最大化方法来解决基于距离的目标聚类问题,并推导客户端与每个聚类中心的最佳匹配。在E步中,通过固定
w
c
w_c
wc 更新聚类分配
r
c
(
k
)
r_c^{(k)}
rc(k)。如果
k
=
arg
min
j
Dist
(
θ
c
,
w
(
j
)
)
k = \arg \min_j \text{Dist}(\theta_c, w^{(j)})
k=argminjDist(θc,w(j)),则设置
r
c
(
k
)
=
1
r_c^{(k)} = 1
rc(k)=1。否则,设置为0。在M步中,聚类中心
w
(
k
)
w^{(k)}
w(k) 更新为:
w
(
k
)
=
1
∑
C
r
c
(
k
)
∑
c
=
1
C
r
c
(
k
)
w
c
w^{(k)} = \frac{1}{\sum_{C} r_c^{(k)}} \sum_{c=1}^{C} r_c^{(k)} w_c
w(k)=∑Crc(k)1c=1∑Crc(k)wc
最后,
w
(
k
)
w^{(k)}
w(k) 被发送到聚类
k
k
k 中的所有客户端,以便在其私有训练数据上对本地模型参数
θ
c
\theta_c
θc 进行微调。上述步骤重复进行,直到收敛。
总结
在本节中,我们讨论了基于架构的方法和基于相似性的方法,以学习个性化模型。以下是对这些个性化技术的优缺点的总结和比较(见表II)。
基于架构的方法旨在通过为每个客户端量身定制的模型设计来实现个性化。由于参数解耦方法具有简单的公式,实现每个客户端的个性化层 [46],[47],因此其支持高程度模型设计个性化的能力有限。相比之下,基于知识蒸馏(KD)的PFL方法为客户端提供了更大的灵活性,以适应个性化模型架构。这些方法在通信和计算受限的边缘FL设置中也具有优势 [56],[57]。然而,KD过程中通常需要代表性的代理数据集 [42],[56]。对于这两种方法,模型构建中存在一些挑战。在参数解耦中,私有和联邦参数的分类是一个架构设计决策,控制着泛化和个性化性能之间的平衡 [46]。确定最佳隐私策略是一个研究挑战。在KD中,知识转移的有效性不仅依赖于模型参数,还依赖于模型架构。如果大型教师模型与小型学生模型之间存在巨大的能力差距,学生模型可能难以学习良好 [73],[74],因此必须为服务器和客户端模型确定最佳设计。
基于相似性的方法旨在通过建模客户端关系来实现个性化。多任务学习(MTL)方法如FedAMP [61] 擅长捕捉客户端之间的成对关系,以学习相关客户端的相似模型。因此,它可能对数据质量较差敏感,从而导致客户端根据数据质量的不同而分隔。模型插值方法则通过混合全局模型和本地模型来学习个性化模型,其公式简单。然而,由于该方法使用单个全局模型作为个性化的基础,因此在高度非独立同分布(non-IID)的场景中,性能可能会下降 [64],[65]。当客户端之间存在固有分区时,聚类方法具有优势。然而,它们会产生高昂的计算和通信成本,从而限制了其在大规模设置中的实际可行性 [66],[67]。此外,还需要额外的架构组件来管理和部署聚类机制 [67]。
表格 II: 个性化模型学习中的个性化技术总结
| 方法 | 优点 | 缺点 |
|---|---|---|
| 参数解耦 | • 简单的公式 • 每个客户端的架构设计有分层灵活性 | • 难以确定最佳私有化策略 |
| 知识蒸馏 | • 为每个客户端提供高度的架构设计个性化 • 通信效率高 • 支持资源异构性 | • 难以确定最佳架构设计 • 可能需要代表性的代理数据集 |
| 多任务学习 | • 利用客户端之间的两两关系,学习相似的模型 | • 对客户端数据质量较差敏感 |
| 模型插值 | • 使用全局和本地模型混合的简单公式 | • 使用单一全局模型作为个性化基础,在高度非IID场景下可能性能下降 |
| 聚类 | • 适用于客户端之间有内在分区的应用场景 | • 计算和通信成本高 • 需要额外的系统基础设施进行集群管理和部署 |
V. PFL 基准测试与评估指标
PFL(个性化联邦学习)研究领域的长期进展中,性能基准测试是一个重要因素。在这一部分中,我们回顾并讨论了现有PFL文献中使用的基准测试和评估指标。
表格 III: PFL 研究中考虑的非IID数据类型
| 方法 | 数量偏差 | 特征分布偏差 | 标签分布偏差 | 标签偏好偏差 |
|---|---|---|---|---|
| 数据增强 [23][24][21]–[23] | [23]–[24] | - | - | - |
| 客户选择 [28][27]–[28][25]–[28] | [28][27]–[28] | [25]–[28] | - | - |
| 正则化 [29] [29][12][29]–[32] | [29] | [12][29]–[32] | - | - |
| 元学习 [39] [36][40][37][39] | [36] [40] | [37][39] | - | - |
| 迁移学习 - [42]–[44] | - | [42]–[44] | - | - |
| 参数解耦 [46]–[47] | - | [46]–[47] | [46][48] | - |
| 知识蒸馏 [42][55] [58] | - | [42][55] | [42][55]–[57] | - |
| 多任务学习 [59]–[61] | - | [59]–[61] | [61]–[62] | - |
| 模型插值 [17][63] [63]–[65] | - | [17][63]–[65] | [63]–[65] | - |
| 聚类 [72][66]–[70][72] | [72][66]–[70] [72] | [67][70][66]–[67] | [67]–[70] | - |
FL 基准数据集
近年来,开发了多个联邦学习(FL)基准框架,如 FLBench [75]、Edge AIBench [76]、OARF [77] 和 FedGraphNN [78]。LEAF [79] 是最早、最受欢迎的 FL 基准框架之一,它涵盖图像分类、语言建模和情感分析等机器学习任务,支持 IID 和非 IID 场景。尽管 LEAF 扩展了现有的公共数据集,它并未完全反映 FL 场景中的数据异构性。现实世界的 FL 数据集如用于目标检测的街道图像数据集[82],以及用于图像分类的物种数据集[83],往往受限于数据规模。
PFL实验评估设计
尽管已有针对联邦学习(FL)的基准数据集发布,但这些数据集在个性化联邦学习(PFL)研究中并未被广泛采用。大多数PFL研究通过对公开的机器学习基准数据集(如MNIST [84]、EMNIST [80]、CIFAR-100 [85])进行分区,或创建合成数据集 [17], [64], [68] 来模拟非独立同分布(non-IID)的数据设置。以下是PFL文献中模拟的不同类型non-IID设置的综述,根据个性化方法总结在表III中。
-
数量偏差(Quantity Skew): FL客户端持有不同大小的本地数据集,一些客户端的数据量可能比其他客户端大得多。由于FL客户端之间使用模式的多样性,数据规模异质性在现实环境中十分普遍。为了模拟数据规模异质性,可以直接使用不平衡的数据集,而无需进一步采样 [23], [72]。另一种方法是根据幂律分布将数据分配给FL客户端 [28], [29], [39]。
-
特征分布偏差(Feature Distribution Skew): 各客户端的特征分布 ( P_c(x) ) 不同,但条件分布 ( P(y|x) ) 在客户端之间保持一致。例如,在健康监测应用中,用户活动数据的分布由于用户习惯和生活方式的差异而显著不同 [24], [43]。要模拟特征分布偏差,通常使用按用户分区的数据集,每个用户与一个不同的客户端相关联 [24], [59]。该偏差也可以通过旋转数据集等方式进行数据增强来模拟 [68]。
-
标签分布偏差(Label Distribution Skew): 客户端的标签分布 ( P_c(y) ) 不同,而条件分布 ( P(x|y) ) 在客户端之间一致。例如,在软件移动键盘中,不同用户由于文化和语言差异,可能会有不同的词汇或表情符号偏好,从而导致标签分布偏差。为了模拟标签分布偏差,数据集按标签进行分区,每个客户端从固定数量的标签类别 ( k ) 中抽取样本。较小的 ( k ) 值意味着数据异质性更强 [9], [27], [48], [64]。不同级别的标签分布不平衡可以通过使用Dirichlet分布 ( \text{Dir}(α) ) 来模拟,其中 ( α ) 控制数据异质性的程度。( α = 100 ) 相当于IID设置,而较小的 ( α ) 值意味着每个客户端更可能只持有来自一个类别的数据,从而导致高数据异质性 [55], [56], [86]。
-
标签偏好偏差(Label Preference Skew): 客户端的条件分布 ( P_c(x|y) ) 不同,而标签分布 ( P(y) ) 在客户端之间保持一致。由于个人偏好,不同客户端的标签可能有所差异。为了模拟标签偏好偏差,通常会交换一部分标签以增加真实标签的变异性 [66], [67]。
从表III可以看出,大多数现有研究中,PFL算法的评估仅限于单一类型的non-IID设置。特征分布和标签分布偏差是PFL研究中最常用来模拟non-IID设置的两种类型。标签偏好偏差的设置目前仅被基于聚类的PFL方法采用,而其他PFL方法尚未在此类non-IID FL设置下进行研究。因此,FL研究社区需要共同努力,采用一致的基准,以标准化PFL研究中的实验评估设计。
PFL 评估指标
我们将个性化联邦学习(PFL)研究中采用的评估指标分类为:1) 模型性能相关,2) 系统性能相关,3) 可信AI相关(见表IV)。
1. 模型性能相关
-
准确性(Accuracy): 大多数PFL研究使用个性化模型的平均测试准确性来衡量模型性能。虽然在训练单一全局共享模型时使用聚合准确性指标是合理的,但该指标无法反映个性化模型的个体表现。因此,PFL研究引入了基于分布的评估框架,如直方图分析 [61], [87]、方差指标 [37], [55], [88],以及单个客户端层面的指标 [24], [43]。由于各客户端因统计数据异质性具有不同的基线准确性,衡量个性化前后的模型准确性变化是一种评估个性化效果的有效方法 [30], [87], [89]。
-
收敛性(Convergence): 模型收敛性通过训练损失 [28], [32], [64], [66], [67]、通信轮数 [12], [32]、本地训练轮数 [23], [32], [39] 以及收敛边界的形式化 [12], [29], [37] 来衡量。
2. 系统性能相关
-
通信效率(Communication Efficiency): 通过通信轮数 [12], [32]、参数数量 [23], [57], [65] 以及消息大小 [58], [90] 来评估。
-
计算效率(Computational Efficiency): 通过浮点运算次数(FLOPs)[57], [65] 和训练时间 [27], [57] 来评估。
-
系统异质性(System Heterogeneity): 通过模拟硬件能力和网络条件的变化来评估系统异质性。这可以通过调整本地训练轮数 [59], [61]、CPU资源 [27] 和本地模型复杂性 [56], [65] 实现。
-
系统可扩展性(System Scalability): 通过在大量客户端上的表现 [32]、总耗时 [23], [29] 和总内存消耗 [29], [65] 来评估。
-
容错性(Fault Tolerance): 通过评估不同比例掉线客户端 [59], [61] 和拖慢者 [29], [55] 下的性能来衡量。
3. 可信AI相关
可信AI评估指标尚未广泛应用于PFL方法的评估中,尽管已有一些新兴研究考虑了这些指标 [89]。例如,在 [48] 中使用了本地模型公平性和对抗攻击下的鲁棒性来评估所提方法的表现。
评估趋势与挑战
当前PFL研究中的个性化性能评估主要集中在模型性能方面的准确性提升上。然而,实现PFL的成本也应纳入考虑。在追求准确模型的过程中,通常会在系统可扩展性、通信和计算开销方面做出权衡。同时,可信AI属性的实现也未得到充分重视。因此,设计一个有效的PFL框架,能够同时优化这些重要的成本收益目标,对于实际的联邦学习应用至关重要。考虑到PFL面临的独特挑战和应用场景,迫切需要加强开发专门针对PFL的评估指标。
VI. 有前景的未来研究方向
随着实际联邦学习(FL)应用的推进,对具有更好个性化表现的模型的需求逐渐增加。基于对现有个性化联邦学习(PFL)文献的回顾,我们展望了PFL领域未来研究的几个关键方向,包括新架构设计、现实基准测试以及可信PFL方法。
A. PFL架构设计的机会
-
客户端数据异质性分析:
FL客户端之间的数据异质性是决定PFL类型的关键考虑因素。例如,对于存在显著数据分布差异的应用,多模型方法如聚类可能更适用。为促进对非独立同分布(non-IID)数据的实验,PFL的近期研究提出了度量统计异质性的新指标,如总变化(Total Variation)、1-Wasserstein距离 [37] 和地球移动距离(EMD)[21]。然而,这些指标依赖于对原始数据的访问。在隐私保护环境下,如何进行FL客户端数据异质性分析仍是一个开放问题。 -
聚合过程:
在复杂的PFL场景中,基于平均的模型聚合方法可能并不适合处理数据异质性。目前大多数FL架构采用模型平均作为聚合方法,但其在PFL中的有效性尚未从理论上深入研究 [91]。最近的研究 [92] 提出了针对卷积神经网络(CNN)和长短期记忆网络(LSTM)的逐层匹配平均聚合方法。探索专门为PFL设计的聚合方法仍是一个潜在方向。 -
PFL架构搜索:
在统计异质性存在的情况下,联邦神经架构对超参数选择高度敏感,若未进行精心调优,可能会导致学习性能下降 [13]。选择适合非IID数据分布的FL模型架构至关重要。神经架构搜索(NAS)[93] 是一项有前景的技术,能够帮助PFL减少手动设计的工作,基于给定场景优化模型架构,特别适用于参数解耦和知识蒸馏的PFL方法。 -
空间适应性:
空间适应性指的是PFL系统处理客户端数据集变化的能力,这些变化可能源于新客户端的加入或客户端的掉线与拖延。在复杂的基于边缘计算的FL环境中,由于硬件能力(如计算、内存、电源和网络连接)的显著差异,这些问题尤为普遍 [94]。-
(i) 现有的PFL方法通常假设在FL训练周期开始时有固定的客户端池,并且新客户端无法中途加入 [22], [67]。其他方法涉及需要本地计算时间的预训练步骤 [42]。尽管元学习方法 [37] 鼓励新客户端的快速学习,但很少有工作解决PFL中的冷启动问题。当前的深度FL技术还容易在新客户端加入时遭遇灾难性遗忘问题,原因在于神经网络的稳定性-可塑性困境 [95]。这可能导致现有客户端的性能下降。一个有前景的方向是将持续学习 [96] 引入FL,以缓解灾难性遗忘问题。
-
(ii) 在大规模联邦系统中,由于网络、通信和计算限制,掉线和拖延现象普遍存在,因而需要设计具备鲁棒性的FL系统。应对拖延问题的通信高效算法是一个正在进行的研究方向,其中梯度压缩 [97] 和异步模型更新 [98] 是解决FL通信瓶颈的常用策略。这些问题在PFL中需要进一步研究,以正式化开销与性能之间的权衡。
-
-
时间适应性:
时间适应性指的是PFL系统从非静态数据中学习的能力。在动态的现实系统中,数据分布可能会随着时间的推移发生变化,这种现象被称为概念漂移。应对概念漂移通常涉及三个步骤: (i) 漂移检测(是否发生漂移),(ii) 漂移理解(何时、如何以及漂移发生的地点),(iii) 漂移适应(对漂移的响应)[99]。Casado等人 [100] 是少数研究FL中概念漂移问题的工作之一,他们通过变更检测技术(CDT)扩展了FedAvg来检测漂移。如何利用现有的漂移检测与适应算法以改善PFL系统在动态数据中的学习能力,仍是一个开放的研究方向。
B. PFL基准测试的机会
-
现实数据集:
现实的数据集对一个领域的发展至关重要。为了促进PFL研究,需要更多包含音频、视频和传感器信号等多模态数据的数据集,并涉及来自真实应用的更广泛的机器学习任务。 -
现实的非IID设置:
大多数现有研究中,PFL算法的评估仅限于单一类型的非独立同分布(non-IID)设置。实验通常使用现有的预分区公共数据集(如LEAF)或通过分区公共数据集以适应目标non-IID设置。为了更公平的比较,研究界需要更深入地理解现实联邦学习中的不同non-IID设置,以模拟更真实的non-IID场景。例如: (i) 时间偏移(数据分布随时间变化),(ii) 存在恶意攻击者。这个方向需要研究人员与行业实践者的广泛合作,有助于建立健康的PFL研究生态系统。 -
全面的评估指标:
建立系统的评估方法和指标对PFL研究至关重要。在评估FL系统的性能时,需要考虑模型性能、系统性能和可信AI属性。为潜在使用者提供对某种PFL方法的全面成本效益分析的方法论是非常必要的,以便深入了解其在现实世界中的影响。
C. 可信PFL的机会
-
开放协作:
除了算法挑战之外,未来PFL研究还可以探索如何促进自利数据所有者之间的协作。例如,具有个性化FL模型的数据所有者可能需要与其他合适的数据所有者分享其模型,以适应动态现实应用中学习任务的变化 [101]。激励机制设计是实现这一愿景的一个有前景的研究方向。博弈论、定价和拍卖机制 [102] 可以应用于构建适当的激励方案,支持开放协作的PFL系统的兴起。 -
公平性:
随着机器学习技术越来越广泛地被企业采用来支持决策制定,确保公平性的方法变得越来越重要,以避免不良的伦理和社会影响 [103], [104]。现有方法未能充分解决PFL中特有的公平性挑战,这些挑战包括由参与FL客户端的多样性引入的新偏差来源,如本地数据大小不等、活动模式、位置和连接质量等 [8]。PFL中的公平性研究仍处于起步阶段,其定义尚未清晰。当前的FL公平性研究主要集中在流行的服务器端FL范式上 [105]–[107],但针对其他FL范式的公平性研究也在兴起 [108]。随着FL的逐渐成熟,改进PFL公平性的进展将变得越来越重要,以便FL能够大规模应用。 -
可解释性:
可解释性人工智能(XAI)[109] 是一个活跃的研究领域,最近受到政府机构和公众对可解释模型需求的推动 [110]。在高风险应用中,如医疗,模型的可解释性尤为重要,因为需要对做出的决策进行合理解释 [111]。FL文献中尚未系统地探讨可解释性问题。由于分布式数据集的规模和异质性,实现PFL中的可解释性面临复杂的挑战。追求FL模型的可解释性可能还会带来潜在的隐私风险,因为某些基于梯度的解释方法可能会导致隐私泄露,如 [112] 所示。目前很少有研究同时解决可解释性与隐私目标的工作。开发一个能够在可解释性和隐私之间平衡的FL框架是未来研究的一个重要方向。一个可能的途径是将可解释性融入全局FL模型,而不涉及FL模型的个性化部分。 -
鲁棒性:
尽管FL相比传统的集中式模型训练方法提供了更好的隐私保护,近期研究揭示了FL的漏洞,这可能会破坏数据隐私 [16]。因此,研究FL攻击方法并开发防御策略以应对这些攻击对于确保FL系统的鲁棒性至关重要。随着更复杂的PFL协议和架构的发展,相关攻击和防御形式的研究需要进一步深入,以推动鲁棒PFL方法的出现。
VII. 结论
在本次调研中,我们概述了联邦学习(FL),并探讨了个性化联邦学习(PFL)的关键动机。我们提出了一个独特的PFL技术分类法,根据PFL中的主要挑战和个性化策略进行分类,并重点介绍了这些PFL方法中的关键思想、挑战与机会。最后,我们讨论了PFL文献中常用的公共数据集和评估指标,并指出了一些未解决的问题和未来的研究方向。我们相信,本调研基于我们提出的PFL分类法的讨论,将为有志进入PFL领域的研究人员和从业者提供有用的路线图,并为其长期发展做出贡献。
致谢
本研究部分得到了新加坡国家研究基金会(NRF)旗下的AI Singapore计划(AISG奖号:AISG2-RP-2020-019)、阿里巴巴集团通过阿里巴巴创新研究(AIR)计划和阿里巴巴-南洋理工大学新加坡联合研究院(JRI)(阿里巴巴-南洋理工大学-AIR2019B1)、南洋理工大学、新加坡RIE 2020先进制造与工程(AME)计划基金(编号:A20G8b0102)、南洋助理教授计划(NAP)、南洋理工大学-山东大学人工智能联合研究中心(C-FAIR)(NSC-2019-011)、中国国家自然科学基金委员会(NSFC)项目(编号:91846205)、中国国家重点研发计划(编号:2021YFF0900800)、山东省自然科学基金(编号:ZR2019LZH008)、山东省重点研发计划(重大科技创新项目)(编号:2021CXGC010108)、中国国家重点研发计划资助(编号:2018AAA0101100)以及香港研究资助局(RGC)TRS T41-603/20-R项目的支持。本文中表达的任何观点、研究结果和结论或建议均为作者个人观点,不代表资助机构的意见。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









