






Multi Model Serving
https://kserve.github.io/website/0.10/modelserving/mms/multi-model-serving/
可伸缩性问题
模型部署的可伸缩性问题
随着机器学习方法在组织中越来越广泛地采用,有一种趋势是部署大量模型。例如,新闻分类服务可以为每个新闻类别训练定制模型。组织希望训练大量模型的另一个重要原因是保护数据隐私,因为隔离每个用户的数据并单独训练模型更安全。虽然通过为每个用例构建模型可以获得更好的推断准确性和数据隐私,但在Kubernetes集群上部署数千到数十万个模型更具挑战性。此外,服务于基于神经网络的模型的用例越来越多。为了实现合理的延迟,这些模型在GPU上得到更好的服务。然而,由于GPU是昂贵的资源,因此为许多基于GPU的模型提供服务是昂贵的。
KServe的原始设计为每个推理服务部署一个模型。但是,当处理大量模型时,它的“一个模型,一个服务器”范式给Kubernetes集群带来了挑战。为了扩大模型的数量,我们必须扩大推理服务的数量,这可以迅速挑战集群的极限。
多模式服务旨在解决KServe将遇到的三种限制:
- 计算资源限制
- pod最大数量限制
- IP地址最大数量限制。
计算资源限制
每个推理服务都有一个资源开销,因为每个pod中都注入了sidecars。这通常会为每个推理服务副本添加大约0.5个CPU和0.5G内存资源。例如,如果我们部署10个模型,每个模型有2个副本,那么资源开销为1020.5=10 CPU和1020.5=10 GB内存。每个模型的资源开销是1CPU和1GB内存。使用当前方法部署许多模型将很快耗尽集群的计算资源。使用多模型服务,这些模型可以加载在一个推理服务中,然后每个模型的平均开销为0.1CPU和0.1GB内存。对于基于GPU的模型,所需的GPU数量随着模型数量的增长而线性增长,这是不划算的。如果可以在一个启用GPU的模型服务器(如TritonServer)中加载多个模型,那么我们在集群中需要的GPU就会少得多。
pod最大数量限制
Kubelet具有每个节点的最大pod数量,默认限制设置为110。根据Kubernetes的最佳实践,一个节点不应该运行超过100个pod。有了这个限制,一个具有默认pod限制的典型50节点集群最多可以运行1000个模型,假设每个推理服务平均有4个pod(两个转换器副本和两个预测副本)。
IP地址最大数量限制
Kubernetes集群每个集群也有一个IP地址限制。推理服务中的每个pod都需要一个独立的IP。例如,一个拥有4096个IP地址的集群最多可以部署1024个模型,假设每个推理服务平均有4个pod(两个转换器副本和两个预测器副本)。
使用ModelMesh进行多模型服务的好处
使用ModelMesh服务的多模型解决了上述三个限制。它降低了每个模型的平均资源开销,因此模型部署变得更具成本效益。集群中可以部署的模型数量将不再受到pod最大数量限制和IP地址最大数量限制的限制。
在此处了解有关ModelMesh的更多信息。
ModelMesh服务
使用ModelMesh的多模型服务是最近添加的一项alpha功能,旨在提高KServe的可扩展性。请假设接口可能会发生更改。
概述
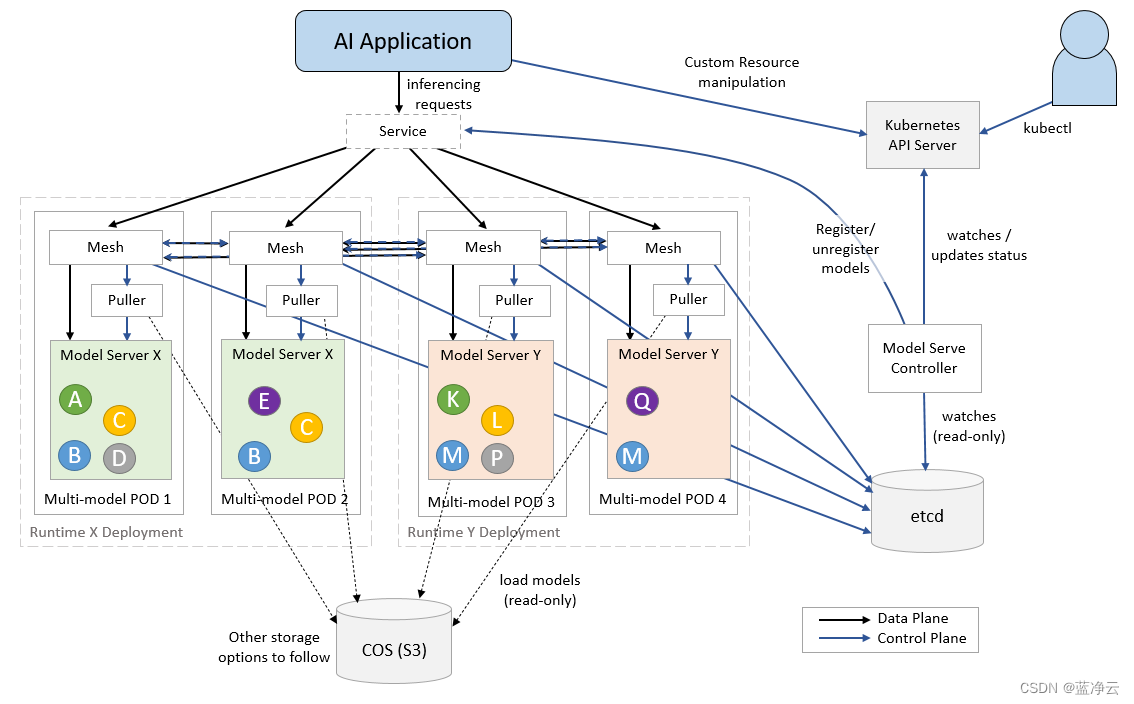
ModelMesh Serving是一个基于Kubernetes的平台,用于ML/DL模型的实时服务,针对高容量/高密度用例进行了优化。通过在部署的Pod集群中智能管理内存中的模型数据,根据这些模型随时间的使用情况,最大限度地利用可用系统资源。
利用现有的第三方模型服务器,可以开箱即用地支持许多标准ML/DL模型格式,以下还有更多:TensorFlow、PyTorch ScriptModule、ONNX、scikit-learn、XGBoost、LightGBM、OpenVINO IR。还可以扩展自定义运行时以支持任意模型格式。
该体系结构包括一个控制器Pod,它协调一个或多个加载/服务模型的Kubernetes“模型运行时”部署,以及一个接受推理请求的服务。跨越运行时pod的路由层确保在正确的时间将模型加载到正确的位置,并处理这些请求的转发。
模型数据本身是从一个或多个必须在Secret中配置的外部存储实例中提取的。我们目前只支持基于S3的对象存储(自管理存储也是自定义运行时的一个选项),但不久将支持更多选项。
ModelMesh Serving使用了两种核心Kubernetes自定义资源类型:
- ServingRuntime-可以提供一个或多个特定模型格式的Pods模板。有三个“内置”运行时涵盖了开箱即用的模型类型,可以通过创建额外的运行时来定义自定义运行时间。
- Predictor-这表示使用特定模型提供预测的逻辑端点。Predictor spec指定模型类型、它所在的存储以及该存储中模型的路径。相应的endpoint是“stable”,当spec更新时,它将在不同的模型版本或类型之间无缝转换。
只有当有一个或多个定义的预测器需要它们时,才会启动与特定ServingRuntime相对应的Pods。
我们在KServe v2数据平面API上进行了标准化推理,所有内置模型类型都支持这一点。此版本的ModelMesh Serving仅支持此API的gRPC版本,REST支持将很快到来。自定义运行时可以免费使用gRPC服务API进行推理,包括KSv2 API。
可以通过创建名称为model-serving-config的ConfigMap来设置系统范围的配置参数。
组件
核心组件
- ModelMesh Serving - 模型服务控制器
- ModelMesh - 用于编排模型存储和路由的ModelMesh容器
运行时间适配器
- modelmesh-runtime-adapter - 在每个模型服务pod中运行的容器,充当modelmesh和第三方模型服务器容器之间的中介。它还包含了负责从存储中检索模型的“puller”逻辑
模型服务运行时间
- triton-inference-server - NVIDIA的triton推理服务器
- seldon-mlserver - 基于Python的推理服务器
- openVINO-model-server - openVINO模型服务器
KServe集成
请注意,KServe与ModelMesh的集成仍处于alpha阶段,在ModelMesh上部署时,仍有一些功能(如解释器)无法工作。
在任何情况下,ModelMesh Serving都支持使用KServe的推理服务接口部署模型。ModelMesh Serving还支持转换器用例,其中转换器和预测器由KServe和ModelMesh控制器分别部署。ModelMesh转换器的示例可以在这里找到。
虽然ModelMesh Serving可以处理其原始的Predictor CRD和KServe InferenceService CRD,但仍有工作要做,以最终使KServe和ModelMesh在InferenceService CRD的使用上趋同。
安装
有关安装说明,请查看此处。
了解更多
要了解有关ModelMesh的更多信息,请查看文档。














 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









