







本文提出了一种新的用于艺术字形图像合成的一阶段少拍学习模型。提出的AGIS网络只需要少量的训练样本作为输入,然后可以为任何其他字符合成与训练数据具有相同艺术风格的高质量字形图像。并且还构建了一个新的大规模中文字形图像数据集用于评估。该数据集包含各种形状和纹理风格,由35种专业设计的艺术字体(7326个字符)和2460种合成艺术字体(639个字符)渲染而成。在中英文数据集上各有实验。本文的重点是使用字体设计者创建的几个样本自动合成艺术字体中字符的新颖字形图像,如图

所谓一阶段,即生成器可以直接输出带有用户指定内容和样式的风格化字形图像
本文主要贡献如下:
1、提出了一个简单而有效的模型,AGIS网络,利用两个并行的编码器-解码器分支,在一个阶段内将艺术字体风格转换为形状风格和纹理风格。
2、引入了一种新的计算效率高的损失函数,称为局部纹理细化损失,有助于提高合成结果的质量。
3、构建了一个新的汉字字形图像数据集,它由180多万幅图像组成,涵盖了2460种综合艺术字体风格和35种艺术家设计的字体风格。
4、大量实验清楚地验证了提出的方法在少镜头学习上的有效性和可扩展性,并证明了它在艺术字体风格转换方面优于其他现有方法。
注意点:为了稳定收敛,在实现少拍学习之前预训练模型。之后再根据需要,将预先训练好的模型微调成任何特定的艺术风格。本文使用作者创建的中文字形图像数据集和[Azadi等2018]提出的英文字形图像数据集进行预训练。
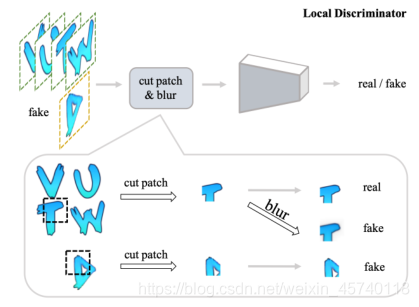
网络结构体系:该模型由一个生成器和三个鉴别器组成:形状鉴别器Dsha、纹理鉴别器Dtex,局部鉴别器Dlocal.生成器的形状和纹理输出图像分别输入形状鉴别器和纹理鉴别器。形状鉴别器的真实样本是纹理鉴别器真实样本的灰度版本。同时,风格输入图像和纹理输出图像被输入到局部鉴别器。局部鉴别器可用于细化局部处理
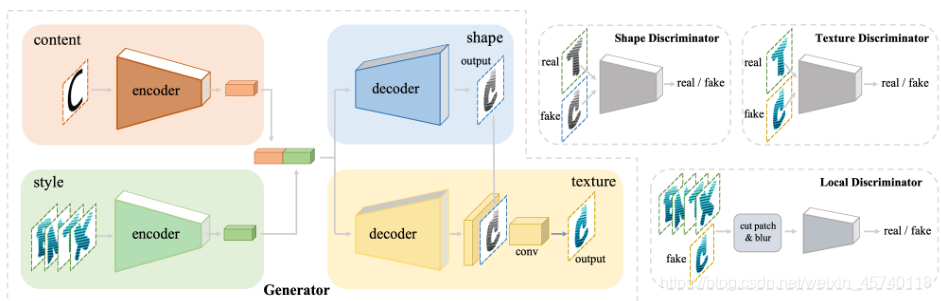
在两个编码器-解码器分支中使用跳跃连接,如下图,这样两个编码器-解码器分支就可以一起工作。对于形状解码器,有几个上卷积层。每一层的输入是前一层和两个编码器中对应层的特征的串联。然后,可以从形状解码器生成灰度形状图像。对于纹理解码器,它是相似的,但是每个层的输入被相应形状解码器层的特征额外连接。在纹理解码器的末端,还有一个卷积层,由先前的特征和灰度图像拼接而成,因此来自形状解码器的所有信息都可以与纹理解码器共享。
并且提出的AGIS-网的生成器中有六个卷积层和六个上卷积(转置卷积)层,每个层都配备了实例归一化和ReLU。作者遵循Pix2Pix中判别器的结构来设计三个判别器,它们输出分数图而不是单个值。所有图像的尺寸都是64×64×3,除了局部鉴别器的是32x32x3。
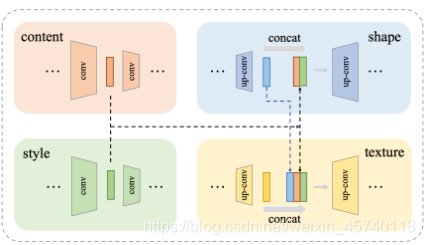
使用跳过链接架构目的:可针对不同规模的特性,高层特征包含更多抽象的风格信息,低层特征包含更多具体的风格信息,能让模型学习到有效和充分的信息
使用两个独立的解码器目的:主要是因为与颜色和纹理相比,字形图像中的形状变化更大。有了这样的网络架构,模型可以更加注重造型风格。
局部鉴别器示意图:
损失函数:主要由四个损失函数组成:对抗性损失、L1损失、上下文损失和局部纹理细化损失
![]()
1、Adversarial loss(对抗性损失):
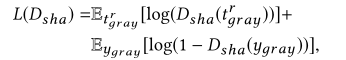

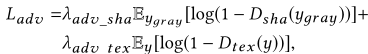
y和y_gray表示机器生成的图像,![]() 是具有纹理效果的真实字形图像,
是具有纹理效果的真实字形图像,![]() 表示灰度版本的
表示灰度版本的![]() ,λadv _ sha和λadv_t表示用于平衡这些项的权重。
,λadv _ sha和λadv_t表示用于平衡这些项的权重。
2、L1loss(L1损失):有两个术语,分别用于灰度图像和纹理图像
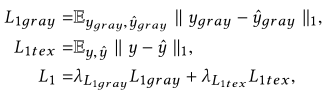
3、Contextual loss(上下文损失):是对L1损失的补充,更注重高层的样式特征,关键思想是将一幅图像视为特征的集合,并基于特征地图集合的相似性来度量两幅图像之间的相似性,而忽略特征的空间对齐。而空间对齐是L1损失可补充的。φL()表示从VGG19的第1层提取的特征,L是使用的层数
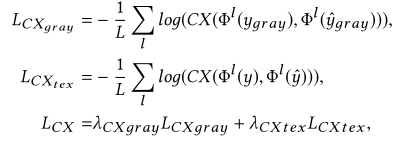
4、Local texture refinement loss(局部纹理细化损失):
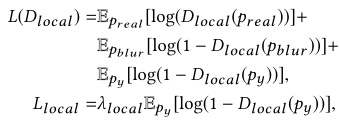
预训练集处理:首先渲染246种正常中文字体样式的639个代表性汉字的字形图像。然后,为了将它们转换成带有纹理的字形图像,在原始二值图像上应用渐变颜色和各种条纹纹理。
数据集包含1,571,940个不同的艺术字形图像。对于少拍学习,选择了35种艺术家设计的带有纹理的字体作为测试集,每种字体由7326个汉字组成。

权重分别: λadv_sha= 1.0, λadv_t ex= 1.0,λL1gray= 50.0, λL1tex= 100.0, λCXgray= 15.0, λCX t ex= 25.0以及λlocal= 1.0
预训练阶段,英文数据集20epochs,中文数据集10epochs,每个batch size=100
微调时,针对英文数据集的每个字体风格, batch size 26 ,3000 training epochs,验证模型给每个50epochs;针对中文数据集的每个字体风格,batch size 100 ,500 training epochs
预训练效果图

与其他网络效果对比:


失败案例:由于颜色不一致,前三列生成的中文字形图像质量较差,这可能是因为模型在训练过程中陷入局部最小值,这可以通过调整超参数来解决。该模型对于另外两种英文字体也表现不佳,因为它们的形状样式非常独特,与预训练数据之间存在巨大的样式差距。

总的来说,该模型能够生成高质量的字符位图图像,同时保持内容信息和样式的一致性。但是,这些位图图像不能直接用于创建由完全可缩放的字符矢量图像组成的字体。
源码及数据集: https://hologerry.github.io/AGIS-Net/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









