






mysql深入浅出(一)
最近看了Mysql有关得资料,接下来就边写边回忆下吧。
首先讲讲mysql底层是如何存储数据得
这就不免说到四个数据结构:二叉树、红黑树(平衡二叉树)、B树、B+树、以及Hash。
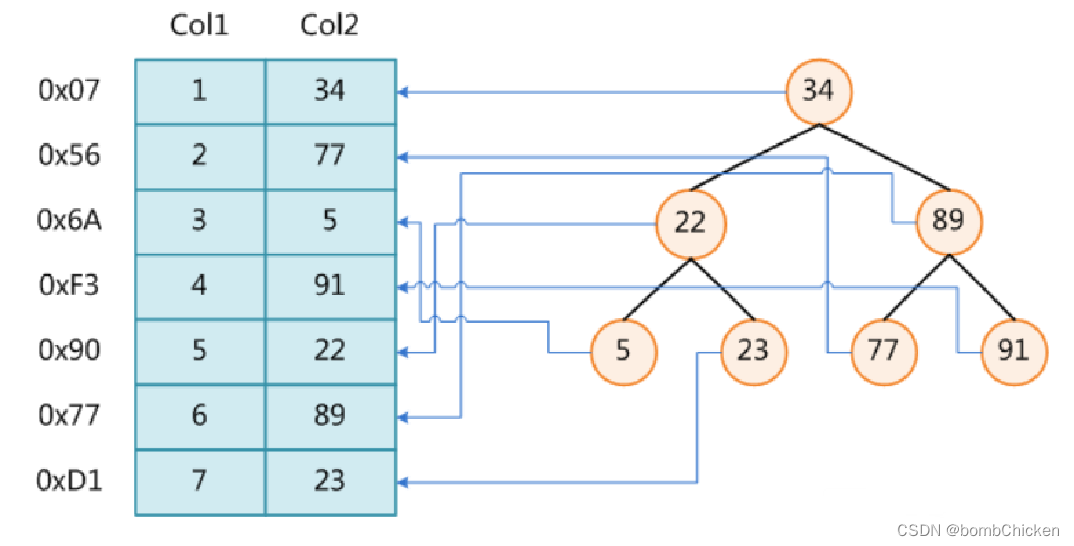
二叉树这边就不解释了。讲讲红黑树吧也称平衡二叉树,下面直接放图
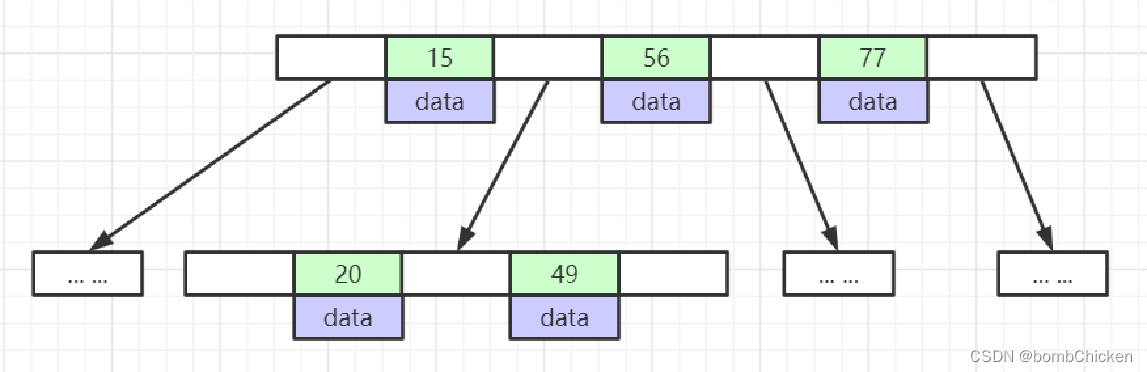
下面再来讲讲B树,有下面几个注意点
1、叶节点具有相同的深度,叶节点的指针为空。
2、所有索引元素不重复。
3、节点中的数据索引从左到右递增排列。
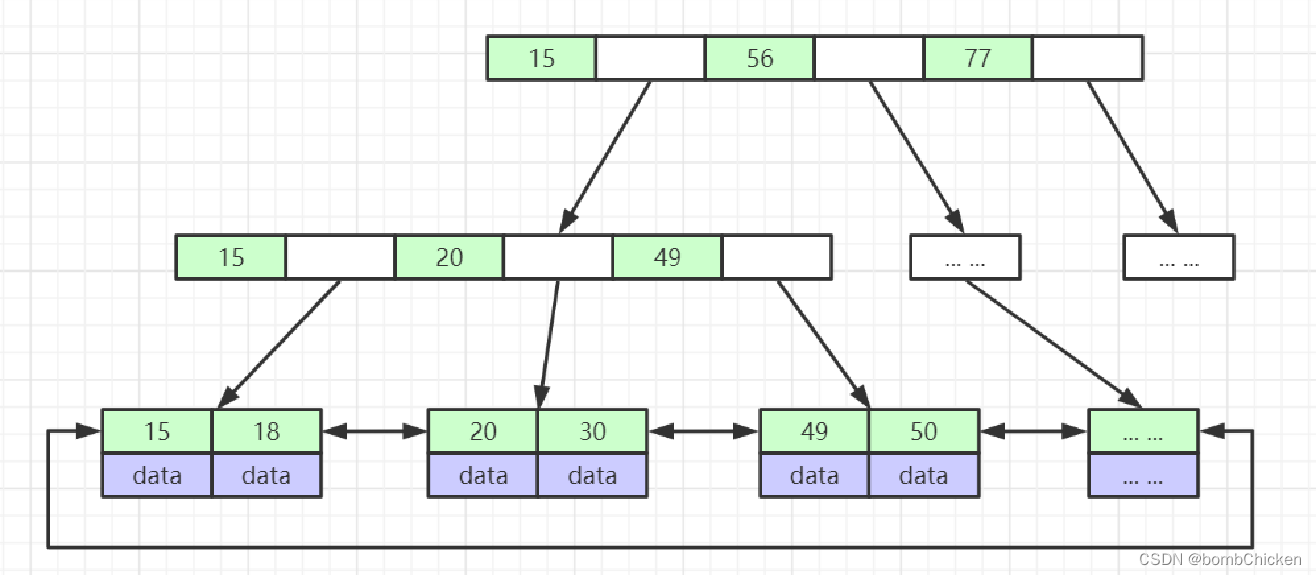
再讲讲B+树:
B+Tree(B-Tree变种)
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能 (mysql优化成了双向指针)
那Mysql为啥会选B+树,下面我们来展开说说。
1、首先B+树叶子节点有双向指针,查询效率高,而B树没有
2、mysql指定但内存约为16kb左右,使用b+树可以减少层级,只需要三层就可以大概存放1170117016约2000w得数据也就是说只要三次I/O操作就可以查到所需数据。而查询中I/O操作是比较费时间得。
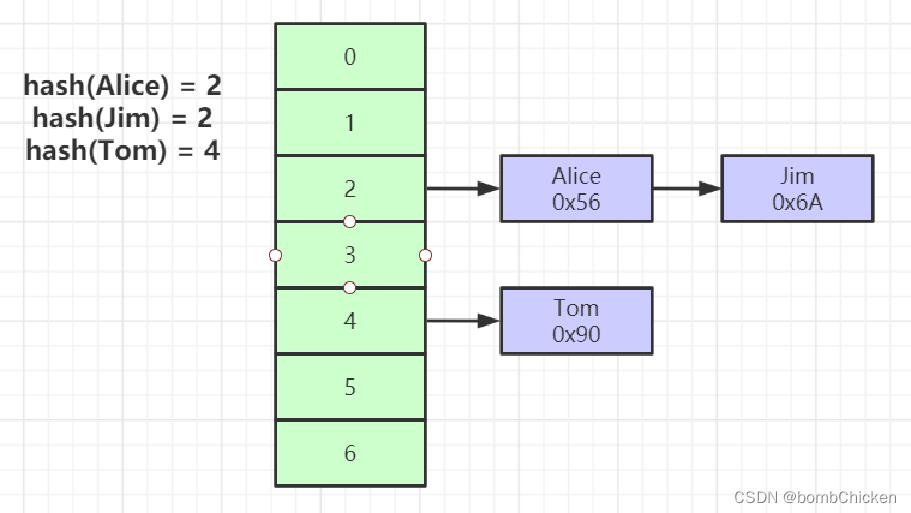
Hash结构我想大家也不陌生
1、对索引的key进行一次hash计算就可以定位出数据存储的位置
2、很多时候Hash索引要比B+ 树索引更高效
3、仅能满足 “=”,“IN”,不支持范围查询
4、hash冲突问题
了解了这几种数据结构后那我们来聊聊Mysql底层到底是怎么存储得吧。先来说说得Mysql得默认存储引擎MyISAM吧。
走下面这张图很明显可以看出来索引文件和数据文件是分离的(非聚集索引)
如果要查询得话mysql会先在树结构里面找到该索引,叶子节点会存索引和存放数据得磁盘地址,然后会根据坐标再去数据文件里面找到对应数据。这样查询就会比较慢。
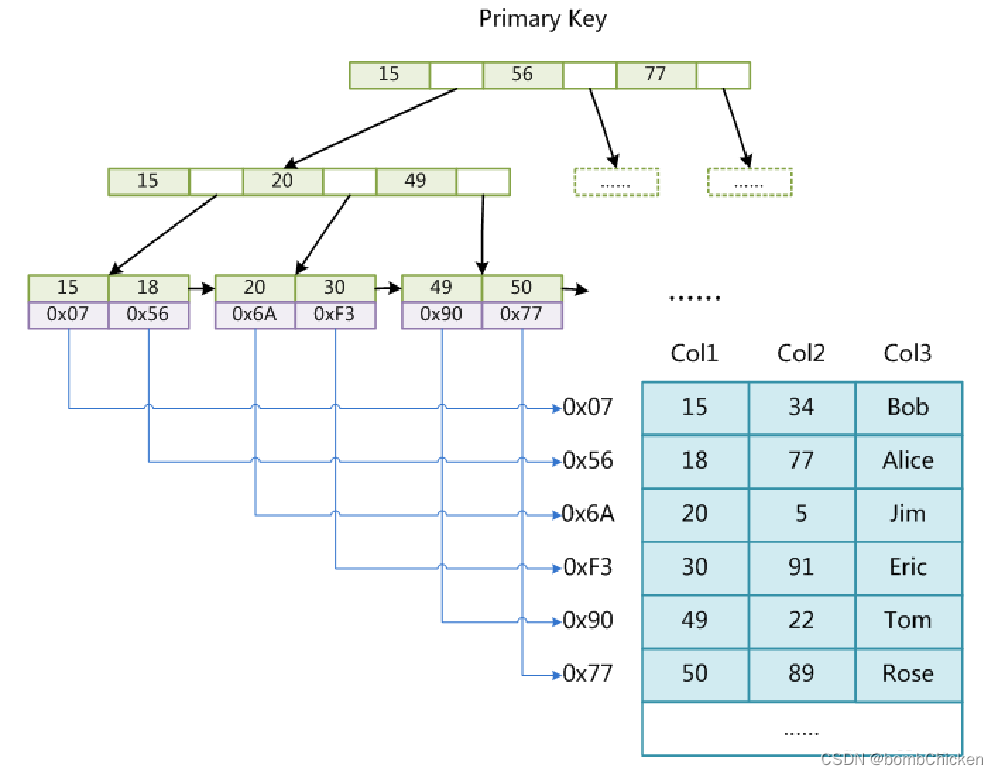
下面再来聊聊InnoDB引擎索引实现(聚集索引)有俩个经典问题
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
1、如果不建主键得话InnoDB会自己去寻找表中没有重复数据得列作为索引,如果没有这样得列则InnoDB会自己生成一个数据不重复隐藏列来作为索引,这样会消耗资源。
2、那为什么又要使用整形自增主键呢?首先整形占内存小节约空间,其次索引是按顺序存放的整形数据比较大小效率更高。而自增得话是因为索引插入树得时候会按照顺序排列,插入得时候如果无序插入会造成叶子节点分裂,并且树结构可能会重新平衡效率会变低,而一直自增插入得话只会在后面开辟新节点。效率更高
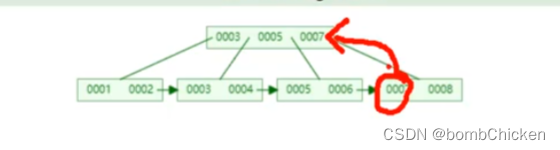
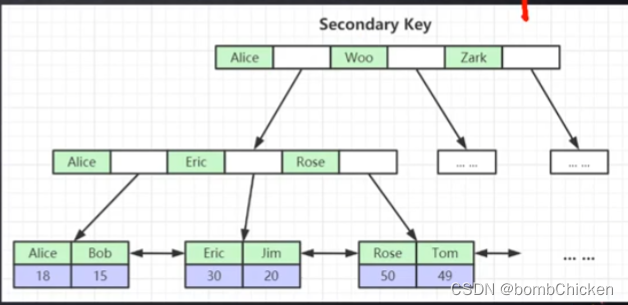
为什么非主键索引结构叶子节点存储的是主键值?
保证一致性和节省存储空间
InnoDB其实还有一种存储结构Hash结构,这种结构用的很少,稍微讲一下,他查询很快但只满足与=和IN,他不支持范围查询
下面再来俩聊联合主键索引如下图
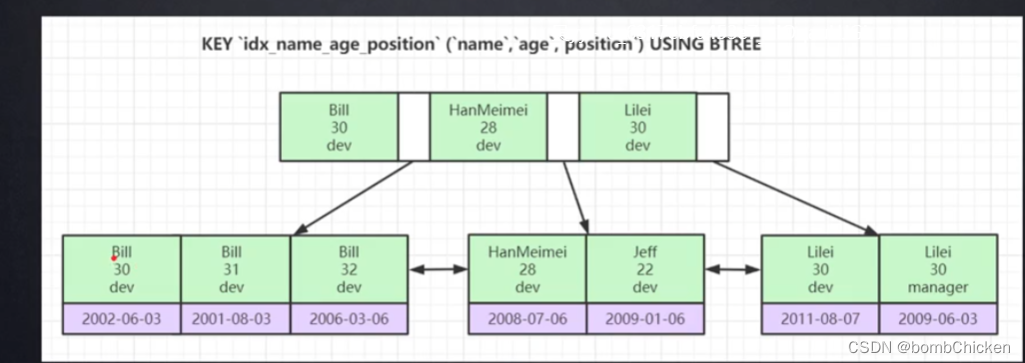
这边要注意最左前缀原则。举个例子如果查name会走索引,如果查name age也会走索引,而如果直接查age则不会走索引。















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









