







文章目录
CH1 绪论
1.1 程序与本课程的关系
程序 = 算法 + 数据结构
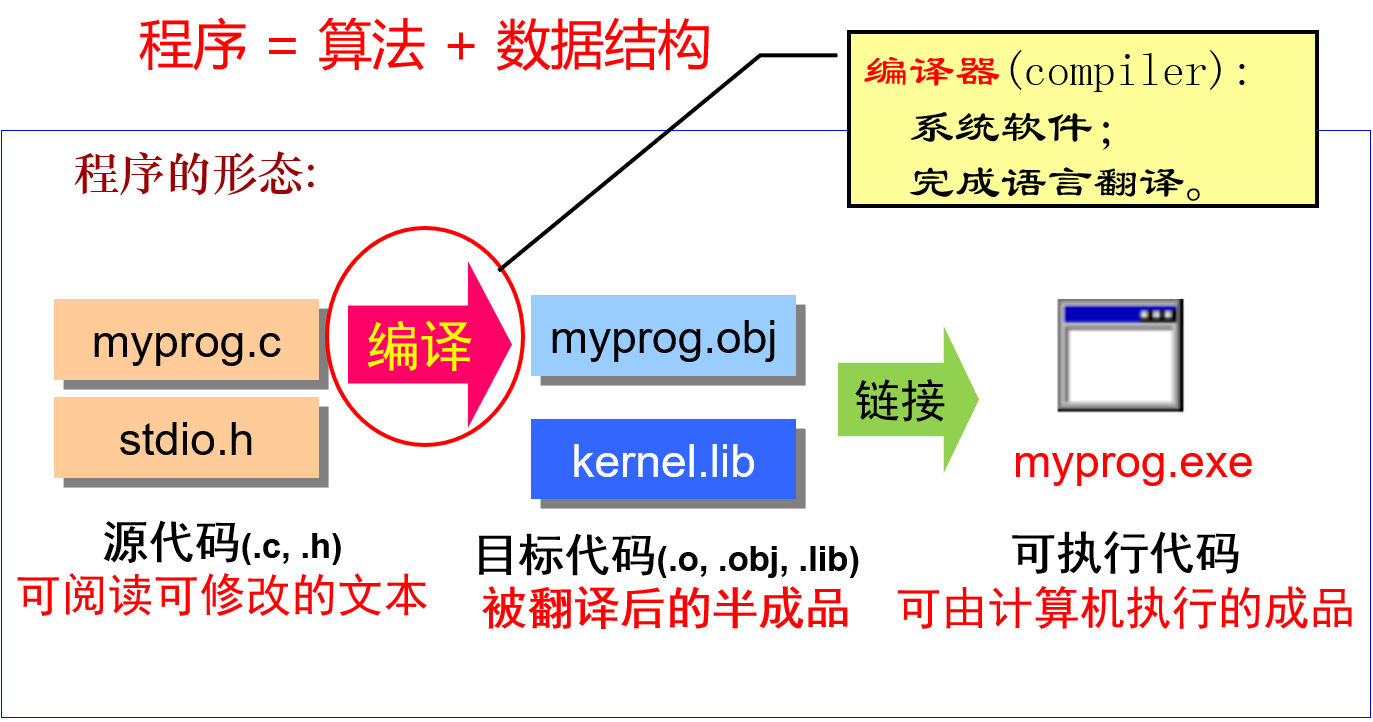
1.2 从面向机器的语言到面向人类的语言
面向机器的语言:机器指令、汇编语言
面向人类的语言:通用程序设计语言,数据查询语言等

语言的分类:
语
言
的
分
类
{
通
用
程
序
设
计
语
言
{
P
A
S
C
A
C
/
C
+
+
J
A
V
A
程
序
员
需
要
思
考
前
因
后
果
,
做
什
么
,
怎
么
做
数
据
查
询
语
言
:
S
Q
L
,
程
序
员
考
虑
怎
么
做
,
如
何
做
形
式
化
描
述
语
言
{
公
式
化
描
述
产
生
式
描
述
语
言
结
构
L
E
X
和
Y
A
C
C
语言的分类\begin{cases}通用程序设计语言\begin{cases}PASCA\\C/C++\\JAVA\end{cases}程序员需要思考前因后果,做什么,怎么做\\数据查询语言:SQL,程序员考虑怎么做,如何做\\形式化描述语言\begin{cases}公式化描述\\产生式描述语言结构\\LEX和YACC\end{cases}\end{cases}
语言的分类⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧通用程序设计语言⎩⎪⎨⎪⎧PASCAC/C++JAVA程序员需要思考前因后果,做什么,怎么做数据查询语言:SQL,程序员考虑怎么做,如何做形式化描述语言⎩⎪⎨⎪⎧公式化描述产生式描述语言结构LEX和YACC
1.2 语言之间的翻译
1.2.1 翻译模式*
习惯称法:
- 高级语言->汇编语言或机器语言:编译(交叉编译)
- 汇编语言->机器语言:汇编(交叉汇编)
- 高级语言之间:预编译,预处理
- 逆向:反汇编,反编译

1.3 编译器与解释器*
语言翻译的两种基本形态:
-
先翻译后执行
先将源程序翻译为目标程序,再执行目标程序。
编译成功后,所得目标程序可被多次执行。
只要源程序不变,运行环境不变,则目标程序仅需要生成一次即可。

-
边翻译边执行
源代码的翻译、程序的执行一般是“交替、串行”进行的。即翻译一段就执行一段。
每次执行都必须先翻译。

1.3.1 编译器和解释器的特点
| 高作效率 | 可移植性 | 交互性/动态性 | |
|---|---|---|---|
| 编译器 | 高 | 低 | 低 |
| 解释器 | 低(翻译+运行) | 高(JVM) | 高(用户交互式) |
1.3.2 基本功能
二者相同,都是完成语言的翻译。
1.3.3 所采用的技术
从翻译的角度来讲,两种方式所涉及的原理、方法、技术相似。
1.4 编译器的工作原理和基本组成
1.4.1 通用程序设计语言的主要成分
从语言的抽象演变来看:
过程 → \rightarrow →抽象数据类型(程序包) → \rightarrow →类
共同特点:
由两大部分组成:声明 + 操作 = 完整定义
- 声明性语句:提供操作对象的性质,如数据类型,值,作用域等
- 操作性语句:确定操作的计算次序,完成实际操作

过程定义 = 过程头 + 过程体
- 过程头:声明性语句
- 过程体:声明 + 操作
procedure sample(y: integer); // {过程头}
var x : integer; // {过程体(开始)}
begin x := y;
if x>100 then x := 0
end; // {过程体(结束)}
1.4.2 以阶段划分的编译器***
(1)阶段的划分
前一个阶段的输出是后一个阶段的输入。

1.4.3 编译器各个阶段的工作
var x, y, z : real;
x := y + z * 60;
-
词法分析:识别记号,记号要分类
-
词法分析的输入是源程序,词法分析器是唯一直接处理源程序的部分
-
词法分析器的输出是记号流
-
词法分析需要略去空格
-

-
语法分析
语法分析需要识别语法结构,以树的形式表示
- 语法分析的输入是记号流
- 输出是语法树

-
语义分析
考查是否复合语法,修改树的结构【填符号表】

-
中间代码生成
中间代码:生成一种既接近目标语言又与具体机器无关的表示,便于优化与代码生成
三地址码:result = arg1 op arg2
四元式:(i)(op, arg1, arg2, result)
经过后序遍历,并且按需生成变量,得到下面的结果:
(1) (itr, 60, , T1) (2) (*, id3, T1, T2) (3) (+, id2, T2, T3) (4) (:=, T3, , id1) -
代码优化
代码优化是等价变换,变换前和变换后的功能相同,但空间上更省,时间更短。
原代码是机械生成的,代码存在冗余

-
目标代码生成

-
符号表管理
合理组织,便于增,删,查,改
-
出错处理
错误分类:
-
分类1

-
分类2
-
错 误 分 类 { 动 态 错 误 ( 动 态 语 义 错 误 ) : 运 行 时 才 能 检 测 出 来 { 除 数 为 0 : a b − c 数 组 下 标 越 界 . . . 静 态 错 误 { 词 法 错 误 : 非 法 字 符 或 者 拼 写 错 关 键 字 , 标 识 符 语 法 错 误 { 缺 括 号 y = 2 ∗ / x 静 态 语 义 错 误 { i n t a , x [ 10 ] ; x = a a x − x 错误分类\begin{cases}动态错误(动态语义错误):运行时才能检测出来\begin{cases}除数为0:\frac{a}{b-c}\\数组下标越界\\...\end{cases}\\ 静态错误\begin{cases}词法错误:非法字符或者拼写错关键字,标识符\\语法错误\begin{cases}缺括号\\y=2*/x\end{cases}\\ 静态语义错误\begin{cases}int\ a,x[10];x = a\\\frac{a}{x-x}\end{cases}\end{cases}\end{cases} 错误分类⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧动态错误(动态语义错误):运行时才能检测出来⎩⎪⎨⎪⎧除数为0:b−ca数组下标越界...静态错误⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧词法错误:非法字符或者拼写错关键字,标识符语法错误{缺括号y=2∗/x静态语义错误{int a,x[10];x=ax−xa
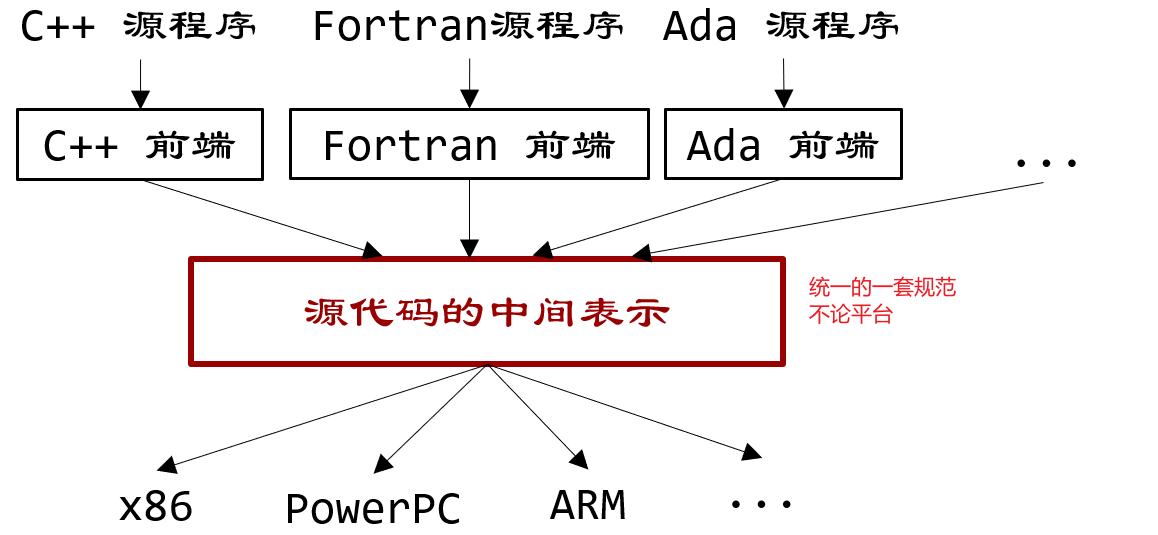
1.4.4 编译器的分析/综合模式
编译器分为前端和后端
- 前端:语言结构和意义的分析
前端有:词法分析,语法分析,语义分析,中间代码生成
- 后端:语言意义的处理
后端:代码优化与生成
- 中间代码是前端与后端的分解

1.4.5 编译器的扫描遍数
1.每个阶段将程序完整分析一遍的工作模式称为一遍扫描。
影响扫描遍数的因素:
- 软、硬件条件,如内存太小
- 语言结构,如规定标识符的先声明后引用
- 编译技术,如拉链-回填
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











