






kmp的用途
一句话概括就是用来判断一个字符串是否是一个字符串的子集
举例说明
当然暴力求解也可以,两次for循环即可,纯暴力的是m*n的复杂度,简单思考一下再进行暴力遍历可以达到(n-m)*m的时间复杂度上面两种暴力方法比较简单,这就不说了
首先明确一下kmp的时间复杂度是m+n,字符串长度不大的时候可能看不出来结果,下面我们举个例子
文本串里有10万个字符
模式串有3万个字符
那么暴力法的时间复杂度是以亿为单位的,而kmp仅仅13万,这差距非常之大,这也说明kmp的高效,当然高效的东西理解起来就比较困难是正常的。
kmp的由来
我个人觉的需要先从最容易想到的方法即暴力法进行思考,创造这种的大佬亦是如此
暴力遍历存在的问题
造成如此高复杂度的原因就是每次重新搜索,那么之前已经搜索过的将不复存在,也就是说在找到正确答案之前的遍历没有任何价值,那么这造成了严重资源浪费。
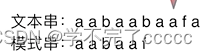
目的
上面已经知道了暴力法时间复杂度高的原因,那么就想要对之前遍历过的进行复用,不用再从头开始遍历。尤其是在一个字符两边是相同字符的情况下怎么保证不从头开始遍历
解决方法(即kmp的核心)
我是这样的逻辑:找一个数组对之前遍历的进行记录然后避免造成重复访问
但是这个数组如何生成,怎么记录之前访问过的字符都没什么想法。在看了KMP之后惊为天人!!!这么妙的想法是怎么想出来的。
说简单点就是,作者创造了一个next数组对之前访问过的进行记录。竟然和大佬的想法不谋而合哈哈。
关键是next的生成只要这个理解了kmp也就理解了
我下面先拿carl的图来讲
引入两个概念
前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串;
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
next数组也叫最长前后缀相等数组
遍历查看是否相等的时候是相等然后遍历下一个,不相等重新来
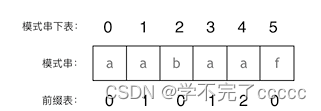
那么先将 模式串分为6个子串
即:
a 0
aa 1
aab 0
aaba 1
aabaa 2
aabaaf 0
因为每次查找不同之后不想再重复查找,所以我们记录每个字串的最长相等长度用来进行不等时的向前回退
由于每个子字符串都是从头开始的,拿图里的例子来说为什么f不匹配的时候找到前一位而前一位正好是2呢
原因如下:
- 明确next数组里到底存的是什么,是模式串从头开始的子串的最长公共长度
- 明确公共长度是前后缀长度即两头开始的长度
- 从头开始那么就对应了数组下标0,由于第二点那么就对应了公共之前的一位字符,数组从0开始,而长度从1开始相当于加1,但是下一位就不是公共前后缀子串了正好对应上
next的代码实现
思路看起来是比较好懂的,但是代码看起来很难说明思路的细节点还没理解透彻(我以为自己懂了,但是代码看起来很费解,再深入理解了每一个点之后代码就很简单了)
void getnext(int* next, const string &s)
{ // 同时 j 也是以i这个字符结尾的字符串的最长相等前后缀的长度
int j = 0; // 前缀指针下标
next[0] = 0; //第一个元素0直接初始化即可
// i是后缀指针的下标就是从1开始
// 分为三个步骤 相等怎么办 不相等怎么办 数组存储
for(int i = 1; i<s.size(); i++)
{
// 不相等说白了就是一直回退 为什么回退j-1 因为[j-1]里存着上一个元素的公共前缀长度即要找的下标
while(j>0 && s[i] != s[j])
{
j = next[j-1];
}
// 相等j++就行 下移一位
if(s[i] == s[j])
{
j++;
}
// i是每个子串的最后一位 将j存在i里面
next[i] = j;
}
}
剩下的就是匹配了很简单
大体与next一样
int strStr(string haystack, string needle) {
if(needle.size() == 0)
{
return 0;
}
int next[needle.size()];
getnext(next, needle);
int j = 0;
for(int i = 0; i<haystack.size(); i++)
{
while(j>0 && haystack[i] != needle[j])
{
j = next[j-1];
}
if(haystack[i] == needle[j])
{
j++;
}
if(j == needle.size())
{
return (i - needle.size() + 1);
}
}
return -1;
}















 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









