







JDK10新特性
注意:Java9和Java10都不是LTS(Long-Term-Support)版本。这两个版本迭代周期短,⽽JDK11才是JDK8之后第⼀个LTS版本。JDK10⼀共定义了109个特性,其中包含12个JEP-JDK Enhancement Proposal(对于程序员有价值的新特性只有⼀个),还有些新API和JVM规范以及JAVA语⾔规范上的改动
官⽅⽂档:http://openjdk.java.net/projects/jdk/10/
JDK10的12个JEP:
- 286:局部变量类型推断
- 296:将JDK森林整合到单个存储库中
- 304:垃圾收集器接⼝
- 307:G1的并⾏完整GC
- 310:应⽤程序类数据共享
- 312:线程局部握⼿
- 313:删除本机头⽣成⼯具(javah)
- 314:其他Unicode语⾔标签扩展
- 316:备⽤内存设备上的堆分配
- 317:基于Java的实验性JIT编译器
- 319:根证书
- 322:基于时间的发⾏版本控制
1.局部变量类型推断
概要
增强Java语⾔,以使⽤初始化程序将类型推断扩展到局部变量的声明。
⽬标
我们试图通过减少与编写Java代码有关的仪式来改善开发⼈员的体验,同时通过允许开发⼈员取消经常不需要的局部变量类型的清单声明来维护Java对静态类型安全的承诺。例如,此功能将允许以下声明:
var list = new ArrayList<String>(); // infers ArrayList<String>
var stream = list.stream(); // infers Stream<String>
这种处理将仅限于具有初始值设定项的局部变量,增强的 for -loop中的索引以及在传统的 for -loop中声明的locals 。它不适⽤于⽅法形式,构造函数形式,⽅法返回类型,字段,catch形式或任何其他类型的变量声明。
优点
减少形式代码,避免数据冗余,增强代码阅读
应⽤场景
- 类实例化时,省略对象名声明时的类型名
- 对于有复杂泛型的类型,也简化了写法
- 当创建的对象或调取的⽅法返回的是固定且不会更改的类型时,可以使⽤类型推断,简化代码
//1.声明变量时,根据new的对象,推断变量类型
var s1=new ArrayList<String>();
s1.add("11");
//2.遍历数据时,变量声明可以使⽤var
for (var s : s1) {
System.out.println(s);
}
注意:以下情况不⽀持局部变量类型推断
- 初始值为null

- Lambda表达式

- ⽅法引⽤

- 为数组静态初始化

- 没有初始化的局部变量声明
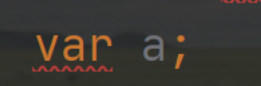
- ⽅法的返回类型

- ⽅法的参数类型

- 构造器的参数类型
- 属性
- catch块
⼩结
- 对于var来说,编译器先查看表达式右侧部分的内容,以此推断左边类型,然后将该类型定义到字节码⽂件中
- var并不是⼀个关键字,⽽是⼀个类型名。给变量或⽅法命名时,并不会冲突。但是实际使⽤时,尽量避免使⽤var来作为⽅法名或者变量名等。
- 这⾥的var并不是js中的var,java仍旧是⼀⻔静态类型语⾔。只不过会⾃⾏推断出类型,写⼊到字节码⽂件中
2.集合中新增copyof()
⽤于创建⼀个只读(不能进⾏增加,修改,删除,排序等操作)的集合(jdk9新增的是of()⽅法)
List<String> aa = List.of("aa", "bb", "cc");
List<String> stringList = List.copyOf(aa);
System.out.println(aa==stringList);//true
//stringList.add("dd"); //编译不报错,运⾏时报错:UnsupportedOperationException
//说明:copyOf() 如果参数集合本身就是⼀个只读集合,则copyOf()返回的为原集合
//如果参数是⼀个⾮只读集合,则copyOf()返回⼀个新的集合,这个集合是只读的
var a2=new ArrayList<String>();
a2.add("aaa");
List<String> copyOf = List.copyOf(a2);
System.out.println(a2==copyOf);//false
原理:
跟踪源码后会发现,copyOf()⽅法中会判断集合是否是AbstractImmutableList类型的,如果是,则直接返回。如果不是则调取of()创建⼀个新的集合。
static <E> List<E> copyOf(Collection<? extends E> coll) {
if (coll instanceof ImmutableCollections.AbstractImmutableList) {
return (List<E>)coll;
} else {
return (List<E>)List.of(coll.toArray());
}
}
3.G1垃圾回收器
概要
通过使整个GC并⾏化来提⾼G1最坏情况的延迟。
⾮⽬标
在所有⽤例中,都应匹配并⾏收集器的完整GC的性能。
动机
G1垃圾收集器在JDK 9中成为默认值。先前的默认值,即并⾏收集器,具有并⾏的完整GC。为了最⼤程度地降低对使⽤完整GC的⽤户的影响,G1完整GC也应并⾏进⾏。
描述
G1垃圾收集器的设计避免了完整收集,但是当并发收集不能⾜够快地回收内存时,将发⽣回退完整GC。G1完整GC的当前实现使⽤单线程的mark-sweep-compact算法。我们打算并⾏化marksweep-compact算法,并使⽤与Young和Mixed集合相同数量的线程。线程数可以通过该 -XX:ParallelGCThreads 选项控制,但这也会影响⽤于Young和Mixed集合的线程数。
补充
- 并⾏Parallel
多条垃圾收集线程并⾏⼯作,但此时⽤户线程仍然处于等待状态。 - 并发Concurrent
指⽤户线程与垃圾收集线程同时执⾏(但并不⼀定是并⾏的,可能会交替执⾏),⽤户程序在继续运⾏,⽽垃圾收集程序运⾏于另⼀个CPU上。
Minor GC和Full GC的区别
- 新⽣代GC(Minor GC):指发⽣在新⽣代的垃圾收集动作,因为Java对象⼤多都具备朝⽣夕灭的特性(存活率不⾼),所以Minor GC⾮常频繁,⼀般回收速度也⽐较快。
- ⽼年代GC(Major GC / Full GC):指发⽣在⽼年代的垃圾收集动作,出现了Major GC,经常会伴随⾄少⼀次的Minor GC(但⾮绝对的,在Parallel Scavenge收集器的收集策略⾥就有直接进⾏Major GC的策略选择过程)。Major GC的速度⼀般会⽐Minor GC慢10倍以上。
吞吐量
就是CPU⽤于运⾏⽤户代码的时间与CPU总消耗时间的⽐值,即吞吐量 = 运⾏⽤户代码时间 /(运⾏⽤户代码时间 + 垃圾收集时间)。虚拟机总共运⾏了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
HotSpot虚拟机中7种垃圾回收器组合
新⽣代收集器:Serial、ParNew、Parallel Scavenge;
⽼年代收集器:Serial Old、Parallel Old、CMS;
整堆收集器:G1;
**G1(Garbage-First)**是⼀款⾯向服务端应⽤的垃圾收集器,JDK 7 Update4 后开始进⼊商⽤。HotSpot开发团队赋予它的使命是未来可以替换掉JDK 1.5中发布的CMS收集器。
在G1之前的其他收集器进⾏收集的范围都是整个新⽣代或者⽼年代,⽽G1不再是这样。使⽤G1收集器时,Java堆的内存布局就与其他收集器有很⼤差别,它将整个Java堆划分为多个⼤⼩相等的独⽴区域(Region),虽然还保留有新⽣代和⽼年代的概念,但新⽣代和⽼年代不再是物理隔离的了,它们都是⼀部分Region(不需要连续)的集合。
G1收集器之所以能建⽴可预测的停顿时间模型,是因为它可以有计划地避免在整个Java堆中进⾏全区域的垃圾收集。G1跟踪各个Region⾥⾯的垃圾堆积的价值⼤⼩(回收所获得的空间⼤⼩以及回收所需时间的经验值),在后台维护⼀个优先列表,每次根据允许的收集时间,优先回收价值最⼤的Region(这也就是Garbage-First名称的来由)。这种使⽤Region划分内存空间以及有优先级的区域回收⽅式,保证了G1收集器在有限的时间内可以获取尽可能⾼的收集效率。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









