







tensor数据类型
Tensor在使用时可以有不同的数据类型,官方给出了 7种CPU Tensor类型与8种GPU Tensor类型。16位半精度浮点是专为GPU模型设计的,以尽可能地节省GPU显存占用,但这种节省显存空间的方式也缩小了所能表达数据的大小。PyTorch中默认的数据类型是 torch.FloatTensor,即torch.Tensor等同于torch.FloatTensor。
PyTorch可以通过set_default_tensor_type函数设置默认使用的Tensor 类型,在局部使用完后如果需要其他类型,则还需要重新设置回所需的 类型。
torch.set_default_tensor_type('torch.DoubleTensor')
类型转换
对于Tensor之间的类型转换,可以通过type(new_type)、type_as()、 int()等多种方式进行操作,尤其是type_as()函数,在后续的模型学习中 可以看到,我们想保持Tensor之间的类型一致,只需要使用type_as()即 可,并不需要明确具体是哪种类型。下面分别举例讲解这几种方法的使 用方式。
# 创建新Tensor,默认类型为torch.FloatTensor
>>> a = torch.Tensor(2, 2)
>>> a tensor(1.00000e-36 *
[[-4.0315, 0.0000],
[ 0.0700, 0.0000]])
# 使用int()、float()、double()等直接进行数据类型转换
>>> b = a.double()
>>> b tensor(1.00000e-36 *
[[-4.0315, 0.0000],
[ 0.0700, 0.0000]], dtype=torch.float64)
# 使用type()函数 >>> c = a.type(torch.DoubleTensor)
>>> c
tensor(1.00000e-36 *
[[-4.0315, 0.0000],
[ 0.0700, 0.0000]], dtype=torch.float64)
# 使用type_as()函数
>>> d = a.type_as(b)
>>> d
tensor(1.00000e-36 *
[[-4.0315, 0.0000],
[ 0.0700, 0.0000]], dtype=torch.float64)
Tensor的创建与维度查看
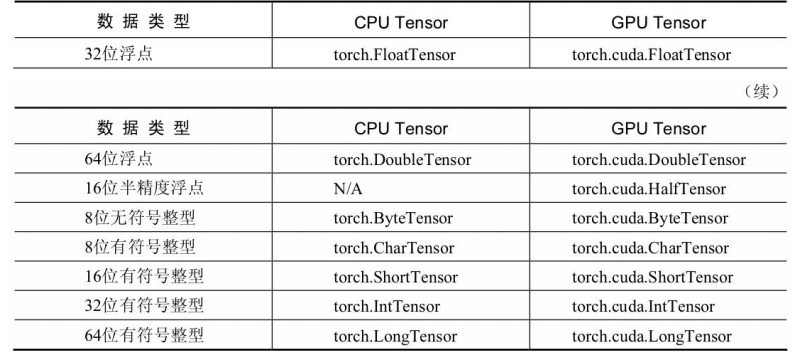
Tensor有多种创建方法,如基础的构造函数Tensor(),还有多种与 NumPy十分类似的方法,如ones()、eye()、zeros()和randn()等,图2.1列 举了常见的Tensor创建方法。
# 最基础的Tensor()函数创建方法,参数为Tensor的每一维大小
>>> a=torch.Tensor(2,2)
>>> a
tensor(1.00000e-18 *
[[-8.2390, 0.0000],
[ 0.0000, 0.0000]])
>>> b = torch.DoubleTensor(2,2)
>>> b
tensor(1.00000e-310 *
[[ 0.0000, 0.0000],
[ 6.9452, 0.0000]], dtype=torch.float64)
# 使用Python的list序列进行创建
>>> c = torch.Tensor([[1, 2], [3, 4]])
>>> c
tensor([[ 1., 2.], [ 3., 4.]])
# 使用zeros()函数,所有元素均为0
>>> d = torch.zeros(2, 2)
>>> d
tensor([[ 0., 0.], [ 0., 0.]])
# 使用ones()函数,所有元素均为1 >>> e = torch.ones(2, 2)
>>> e
tensor([[ 1., 1.], [ 1., 1.]])
# 使用eye()函数,对角线元素为1,不要求行列数相同,生成二维矩阵
>>> f = torch.eye(2, 2)
>>> f
tensor([[ 1., 0.], [ 0., 1.]])
# 使用randn()函数,生成随机数矩阵
>>> g = torch.randn(2, 2)
>>> g
tensor([[-0.3979, 0.2728], [ 1.4558, -0.4451]])
# 使用arange(start, end, step)函数,表示从start到end,间距为step,一维向量
>>> h = torch.arange(1, 6, 2)
>>> h
tensor([ 1., 3., 5.])
# 使用linspace(start, end, steps)函数,表示从start到end,一共steps份,一维向量
>>> i = torch.linspace(1, 6, 2)
>>> i
tensor([ 1., 6.]) .
# 使用randperm(num)函数,生成长度为num的随机排列向量
>>> j = torch.randperm(4)
>>> j
tensor([ 1, 2, 0, 3])
# PyTorch 0.4中增加了torch.tensor()方法,参数可以为Python的list、NumPy的ndarray等
>>> k = torch.tensor([1, 2, 3])
tensor([ 1, 2, 3])
对于Tensor的维度,可使用Tensor.shape或者size()函数查看每一维 的大小,两者等价。
>>> a=torch.randn(2,2)
# 使用shape查看Tensor维度
>>> a.shape
torch.Size([2, 2])
# 使用size()函数查看Tensor维度 torch.Size([2, 2])
>>> a.size()
torch.Size([2, 2])
查看Tensor中的元素总个数,可使用Tensor.numel()或者 Tensor.nelement()函数,两者等价。
# 查看Tensor中总的元素个数
>> a.numel()
4
>>> a.nelement()
4
Tensor的组合与分块
组合与分块是将Tensor相互叠加或者分开,是十分常用的两个功 能,PyTorch提供了多种操作函数,如图2.2所示。
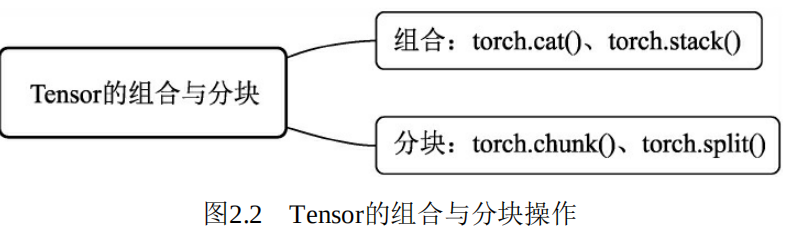
组合操作是指将不同的Tensor叠加起来,主要有torch.cat()和 torch.stack()两个函数。cat即concatenate的意思,是指沿着已有的数据的 某一维度进行拼接,操作后数据的总维数不变,在进行拼接时,除了拼 接的维度之外,其他维度必须相同。而torch.stack()函数指新增维度,并 按照指定的维度进行叠加,具体示例如下:
# 创建两个2×2的Tensor
>>> a=torch.Tensor([[1,2],[3,4]])
>>> a tensor([[ 1., 2.], [ 3., 4.]])
>>> b = torch.Tensor([[5,6], [7,8]])
>>> b
tensor([[ 5., 6.], [ 7., 8.]])
# 以第一维进行拼接,则变成4×2的矩阵
>>> torch.cat([a,b], 0)
tensor([[ 1., 2.], [ 3., 4.], [ 5., 6.], [ 7., 8.]])
# 以第二维进行拼接,则变成24的矩阵
>>> torch.cat([a,b], 1)
tensor([[ 1., 2., 5., 6.], [ 3., 4., 7., 8.]])
# 以第0维进行stack,叠加的基本单位为序列本身,即a与b,因此输出[a, b],输出维度为2×2×2
>>> torch.stack([a,b], 0)
tensor([[[ 1., 2.], [ 3., 4.]], [[ 5., 6.], [ 7., 8.]]])
# 以第1维进行stack,叠加的基本单位为每一行,输出维度为2×2×2
>>> torch.stack([a,b], 1)
tensor([[[ 1., 2.], [ 5., 6.]], [[ 3., 4.], [ 7., 8.]]])
# 以第2维进行stack,叠加的基本单位为每一行的每一个元素,输出维度为2×2×2
>>> torch.stack([a,b], 2)
tensor([[[ 1., 5.], [ 2., 6.]], [[ 3., 7.], [ 4., 8.]]])
分块则是与组合相反的操作,指将Tensor分割成不同的子Tensor, 主要有torch.chunk()与torch.split()两个函数,前者需要指定分块的数量, 而后者则需要指定每一块的大小,以整型或者list来表示。具体示例如 下:
>>> a=torch.Tensor([[1,2,3],[4,5,6]])
>>> a tensor([[ 1., 2., 3.], [ 4., 5., 6.]])
# 使用chunk,沿着第0维进行分块,一共分两块,因此分割成两个1×3的Tensor
>>> torch.chunk(a, 2, 0)
(tensor([[ 1., 2., 3.]]), tensor([[ 4., 5., 6.]]))
# 沿着第1维进行分块,因此分割成两个Tensor,当不能整除时,最后一个的维数会小于前面的因此第一个Tensor为2×2,第二个为2×1
>>> torch.chunk(a, 2, 1)
(tensor([[ 1., 2.], [ 4., 5.]]), tensor([[ 3.], [ 6.]])) # 使用split,沿着第0维分块,每一块维度为2,由于第一维维度总共为2,因此相当于没有分割
>>> torch.split(a, 2, 0)
(tensor([[ 1., 2., 3.], [ 4., 5., 6.]]),)
# 沿着第1维分块,每一块维度为2,因此第一个Tensor为2×2,第二个为2×1
>>>> torch.split(a, 2, 1)
(tensor([[ 1., 2.], [ 4., 5.]]), tensor([[ 3.], [ 6.]]))
# split也可以根据输入的list进行自动分块,list中的元素代表了每一个块占的维度
>>> torch.split(a, [1,2], 1)
(tensor([[ 1.], [ 4.]]), tensor([[ 2., 3.], [ 5., 6.]]))



















 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











