







官网下载地址: https://www.elastic.co/downloads/past-releases
部署环境:centos7
主机 192.168.141.146: 安装 elasticsearch
主机 192.168.141.147: 安装 logstash
主机 192.168.141.154: 安装 kibana
常用的curl命令
1.查看elasticsearch服务是否正常
curl -X GET http://192.168.141.130:9200
2.查看集群状态信息
curl -X GET http://192.168.141.130:9200/_cluster/stats?pretty
3.查看索引信息
curl -X GET http://192.168.141.130:9200/_cat/indices?v
4.过滤出索引名称
curl -s -X GET http://192.168.141.130:9200/_cat/indices?v | awk ‘{print $3}’ | grep ‘log’ | sort | uniq
5.删除索引
curl -X DELETE http://192.168.141.130:9200/(填写要删除的索引名称)
部署之前我们先要了解什么是ELK
ElasticSearch
ElasticSearch 是一个高可用开源全文检索和分析组件。提供存储服务,搜索服务,大数据准实时分析等。一般用于提供一些提供复杂搜索的应用
基本概念:
Index
定义:类似于mysql中的database。索引只是一个逻辑上的空间,物理上是分为多个文件来管理的。
命名:必须全小写
描述:在实践过程中每个index都会有一个相应的副 本。主要用来在硬件出现问题时,用来回滚数据的。这也某种程序上,加剧了ES对于内存高要求。
Type
定义:类似于mysql中的table,根据用户需求每个index中可以新建任意数量的type。
Document
定义:对应mysql中的row。有点类似于MongoDB中的文档结构,每个Document是一个json格式的文本
Mapping
更像是一个用来定义每个字段类型的语义规范。在mysql中类似sql语句,在ES中经过包装后,都被封装为友好的Restful风格的接口进行操作。
这一点也是为什么开发人员更愿意使用ES的原因。
Shards & Replicas
定义:能够为每个索引提供水平的扩展以及备份操作。保证了数据的完整性和安全性
描述:
Shards:在单个节点中,index的存储始终是有限制,并且随着存储的增大会带来性能的问题。为了解决这个问题,ElasticSearch提供一个能够分割单个index到集群各个节点的功能。你可以在新建这个索引时,手动的定义每个索引分片的数量。
Replicas:在每个node出现宕机或者下线的情况,Replicas能够在该节点下线的同时将副本同时自动分配到其他仍然可用的节点。而且在提供搜索的同时,允许进行扩展节点的数量,在这个期间并不会出现服务终止的情况。
默认情况下,每个索引会分配5个分片,并且对应5个分片副本,同时会出现一个完整的副本【包括5个分配的副本数据】。
logstash
logstash工作原理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。
支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Input模块:输入数据到logstash。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tail-f命令
redis:从redis service中读取
beats:从filebeat中读取
kafka:从kafka队列中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。
它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
官方提供的grok表达式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
grok在线调试:https://grokdebug.herokuapp.com/
mutate [ˈmjuːteɪt]:对字段进行转换。
例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs模块:outputs是logstash处理管道的最末端组件。
一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite [ˈɡræfaɪt]:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs模块:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
kibana
主要作用是前端页面展示,不做过多说明。
##################################################
下面开始安装部署
首先在192.168.141.146上配置elasticsearch
jdk官方下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
关闭防火墙和setenforce(三台虚拟机都需要关闭)
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# setenforce 0
安装jdk和elasticsearch
[root@localhost ~]# rpm -ivh jdk-8u131-linux-x64_.rpm
[root@localhost ~]# yum -y install elasticsearch-6.6.2.rpm
配置elasticsearch
[root@localhost ~]# vim /etc/elasticsearch/elasticsearch.yml
# 以下为要修改的内容
cluster.name: wg007 (集群名称)
node.name: node-1 (节点名称)
network.host: 192.168.141.146 (主机ip)
http.port: 9200 (端口)
启动服务查看端口
[root@localhost ~]# systemctl start elasticsearch
[root@localhost ~]# ss -ntl | grep 9200
LISTEN 0 128 ::ffff:192.168.141.146:9200 :::*
[root@localhost ~]# ss -ntl | grep 9300
LISTEN 0 128 ::ffff:192.168.141.146:9300 :::*
在主机192.168.147上配置logstash
安装jdk和logstash
[root@bogon ~]# rpm -ivh jdk-8u131-linux-x64_.rpm
[root@bogon ~]# yum -y install logstash-6.6.0.rpm
这里我们要收集nginx的日志和messages日志
首先安装启动nginx
[root@bogon ~]# yum -y install epel-release
[root@bogon ~]# yum -y install nginx
[root@bogon ~]# systemctl start nginx
给要收集的日志授权
[root@bogon ~]# chmod 777 -R /var/log/nginx
[root@bogon ~]# chmod -R 777 /var/log/messages
添加logstash的配置文件
[root@bogon ~]# cd /etc/logstash/conf.d/
[root@bogon conf.d]# vim messages.conf
input {
file {
path => "/var/log/messages"
type => "msg-log"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => "192.168.141.146:9200" #ip为安装elasticsearch的ip地址
index => "msg_log-%{+YYYY.MM.dd}"
}
}
获取nginx日志之前我们要保证nginx日志的内容不能为空,我们可以用压测命令来添加多条访问信息
在其它两台虚拟机上的任意一台操作
[root@localhost ~]# yum -y install httpd-tools
[root@localhost ~]# ab -n100 -c100 http://192.168.141.147/index.html
添加完访问信息后回到192.168.141.147上继续操作
编写获取nginx日志的配置文件我们可以添加logstash筛选功能的正则模块
[root@bogon conf.d]# cd /usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/
[root@bogon patterns]# vim nginx_access
NGINXACCESS %{IPORHOST:client_ip} (%{USER:ident}|- ) (%{USER:auth}|-) \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} (%{NOTSPACE:request}|-)(?: HTTP/%{NUMBER:http_version})?|-)" %{NUMBER:status} (?:%{NUMBER:bytes}|-) "(?:%{URI:referrer}|-)" "%{GREEDYDATA:agent}"
[root@bogon patterns]# cd /etc/logstash/conf.d/
[root@bogon conf.d]# vim nginx.conf
input {
file {
path => "/var/log/nginx/access.log"
type => "nginx-log"
start_position => "beginning"
}
}
filter {
grok {
match => {"message" => "%{NGINXACCESS}"}
}
}
output {
elasticsearch {
hosts => "192.168.141.146:9200"
index => "nginx_log-%{+YYYY.MM.dd}"
}
}
当logstash有多个配置文件是需要添加管道
[root@bogon logstash]# pwd
/etc/logstash
[root@bogon logstash]# vim pipelines.yml
# This file is where you define your pipelines. You can define multiple.
# For more information on multiple pipelines, see the documentation:
# https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
- pipeline.id: msg
path.config: "/etc/logstash/conf.d/messages.conf"
- pipeline.id: nginx
path.config: "/etc/logstash/conf.d/nginx.conf"
配置完成后启动logstash,查看日志及端口
[root@bogon logstash]# tailf /var/log/logstash/logstash-plain.log
[root@bogon logstash]# ss -ntl | grep 9600
LISTEN 0 50 ::ffff:127.0.0.1:9600 :::*
到主机l92.168.141.146上查看是否成功创建索引
方法1:查看日志
[root@localhost ~]# tailf /var/log/elasticsearch/wg007.log
方法2:使用curl命令
root@localhost ~]# curl -X GET http://192.168.141.146:9200/_cat/indices?v
yellow open nginx_log-2020.04.07 T9bkfy0URXiX8Q9HYxY5BA 5 1 302 0 205.1kb 205.1kb
yellow open msg_log-2020.04.07 1mZJG2YfQ3q-_CJRQLwZ1w 5 1 4876 0 1.6mb 1.6mb
成功创建索引后,去主机192.168.141.154上安装配置kibana
[root@localhost ~]# yum -y install kibana-6.6.2-x86_64.rpm
[root@localhost ~]# vim /etc/kibana/kibana.yml
#以下为要修改的内容
server.port: 5601
server.host: "192.168.141.154" #填本机的ip地址
elasticsearch.hosts: ["http://192.168.141.146:9200"] #填写安装elasticsearch的ip地址
启动kibana查看端口
[root@localhost ~]# systemctl start kibana
[root@localhost ~]# ss -ntl | grep 5601
LISTEN 0 128 192.168.141.154:5601 *:*
端口启动后就可以去页面访问了
http://192.168.141.154:5601




下面介绍下kibana的可视化操作
删除旧的索引

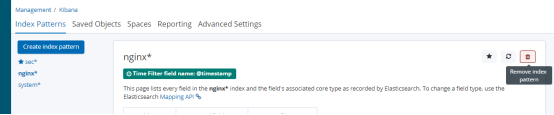
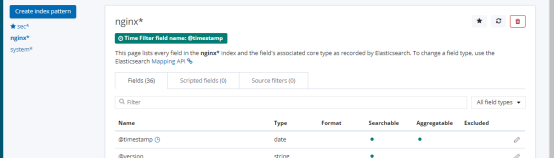
快速创建新的索引
ab -n100 -c100 http://192.168.141.147/index.html
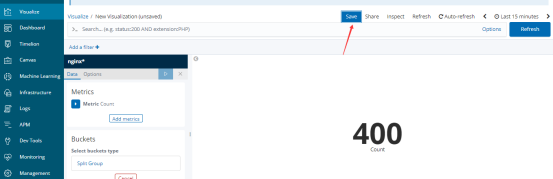
创建饼图




多添加几个访问状态效果更明显
ab -n100 -c100 http://192.168.141.147/path

添加统计网站pv的图形

统计访问网站排名前十的ip


添加访问趋势


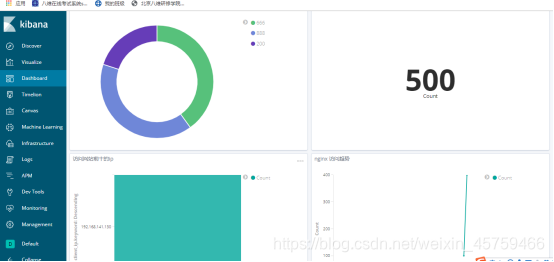
仪表盘


最终效果















 2982
2982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









