






6-1 凯撒加密解密 (10 分)
本题要求实现一个函数,实现对凯撒加密的密文进行解密。即输入为一个密文和加密参数,输出为解密后的原文。
函数接口定义:
def Decrypt( cryptedText, numToMove);
cryptedText 为等待解密的文本, numToMove 是凯撒加密的参数,即移动位数。
裁判测试程序样例:
在这里给出函数被调用进行测试的例子。例如:
text = input('请输入密文:')
num = eval(input("请输入加密的移动位数:"))
orgText = Decrypt(text, num)
print(orgText)
/* 请在这里填写答案 */
输入样例:
在这里给出一组输入。例如:
mjqqt btwqi
5
输出样例:
在这里给出相应的输出。例如:
hello world
答案
def Decrypt(cryptedText, numToMove):
result=""
for i in cryptedText:
# 若是大写
if i.isupper():
result+=chr((ord(i)-ord('A')-numToMove)%26+ord('A'))
# 若是小写
elif i.islower():
result+=chr((ord(i)-ord('a')-numToMove)%26+ord('a'))
else:
result+=i
return result
6-2 凯撒加密的破解 (10 分)
本题要求实现一个函数,可破解一个凯撒密文
函数接口定义:
在这里描述函数接口。例如:
def Crack(text):
text 是输入的加密字符串,输出为破解后的原字符串
裁判测试程序样例:
在这里给出函数被调用进行测试的例子。例如:
# 可以使用下面的函数,获取英文单词列表
def ReadEnglishWords():
result = ['hello','world','you','me','like','i','python','this',\
'is','are','the','great','so','thank','much','winter','summer']
return result
# 可以使用下面的函数,进行凯撒解密
def Decrypt(text, numToMove):
afterText = ""
for p in text:
if ord("a") <= ord(p) <= ord("z"):
afterText += chr(ord("z")-(ord('z')-ord(p)+numToMove)%26)
elif ord("A") <= ord(p) <= ord("Z"):
afterText += chr(ord("Z")-(ord('Z')-ord(p)+numToMove)%26)
else:
afterText += p
return afterText
/* 请在这里填写答案 */
t = input()
org = Crack(t)
print(org)
输入样例:
在这里给出一组输入。例如:
Ftmzw kag ea ygot!
输出样例:
在这里给出相应的输出。例如:
Thank you so much!
错误答案:
之前是想多了,想成解密句子中单词中的字母与字典的单词字母对比,如hellp与hello对比。
# 之前是想多了,想成解密句子中单词中的字母与字典的单词字母对比,如hellp与hello对比。
# def Crack(text):
# text = text.split(' ')
# flag = True
# if not text[-1].isalpha():
# flag = False
# oldword = list(text[-1])
# restructuring = ""
# symbol = ""
# for i in oldword:
# if i.isalpha():
# restructuring = restructuring + i
# else:
# symbol = i
# text[-1] = restructuring
# # 提供的单词字典
# Englishword = ['hello', 'world', 'you', 'me', 'like', 'i', 'python', 'this',
# 'is', 'are', 'the', 'great', 'so', 'thank', 'much', 'winter', 'summer']
# # 解密后句子
# newlist = []
# for x in range(1, 26):
# for i in text:
# word = i
# # 解密后的单词
# # newWord = ""
# words = ""
# for p in word:
# if p.isupper():
# words += chr((ord(p) - ord('A') - x) % 26 + ord('A'))
# elif p.islower():
# words += chr((ord(p) - ord('a') - x) % 26 + ord('a'))
# else:
# words += i
# for k in Englishword:
# if len(k) == len(words):
# # 计算相同字母数
# count = 0
# # 计算当前字母位置
# m = 0
# for n in k:
# if n == words[m]:
# count += 1
# m += 1
# same = count / len(words)
# if same >= 0.8:
# upword = list(k)
# for c in range(int(len(words))):
# if words[c].isupper():
# upword[c] = upword[c].upper()
# else:
# upword[c] = upword[c].lower()
# upword1="".join(upword)
# newlist.append(upword1)
# break
# a = " ".join(newlist)
# if not flag:
# a = a + symbol
# return a
正确答案:
# 只要解密的句子中的单词有60%符合字典就判断为正确解密
def Crack(text):
# 分割字符串
text = text.split(' ')
# 判断末尾是否有标点
flag = True
# 若有标点则存放起来
if not text[-1].isalpha():
flag = False
oldword = list(text[-1])
restructuring = ""
# 标点存放字符串
symbol = ""
for i in oldword:
if i.isalpha():
restructuring = restructuring + i
else:
symbol = i
text[-1] = restructuring
# 提供的单词字典
EnglishWord = ReadEnglishWords()
# 解密后句子
for x in range(1, 26):
newList = []
for i in text:
# 凯撒解密
words = Decrypt(i, x)
# 将单词组装到解密句子
newList.append(words)
# 统计句子中与字典中相同个数
count = 0
# 在字典中循环寻找对应解密的单词,如果对应则数目加一
for k in EnglishWord:
for m in newList:
if k == m.lower():
count += 1
# 判断正确比例
numbers = count / len(newList)
# 正确比例大于60%则输出,原加密句式中有标点则补上
if numbers >= 0.6:
a = " ".join(newList)
if not flag:
a = a + symbol
return a
6-3 编写函数求短语的缩写词 (5 分)
缩写词是由一个短语中每个单词的第一个字母组成,均为大写。例如,CPU是短语“central processing unit”的缩写。
函数接口定义:
acronym(phrase);
phrase是短语参数,返回短语的缩写词
裁判测试程序样例:
/* 请在这里填写答案 */
phrase=input()
print (acronym(phrase))
输入样例:
central processing unit
输出样例:
CPU
答案
# 思路:输入语句分出单词,创建一个字符串存储单词首字母,然后用upper()转为大写
def acronym(phrase): #phrase是短语参数,返回短语的缩写词
lists=''
newPhrase=phrase.split()
for i in newPhrase:
lists += i[0]
lists = lists.upper()
return lists
6-4 修改句子 (10 分)
本题参考checkio.org
读入一个英文句子,将此句子的第一个字母改为大写字母,并在最后加上句号’.’
注意:读入的句子有可能本来就符和要求。
函数接口定义:
def fun(sentence):
裁判测试程序样例:
/* 请在这里填写答案 */
doc = input()
res = fun(doc)
print(res)
输入样例1:
在这里给出一组输入。例如:
hello, world
输出样例1:
在这里给出相应的输出。例如:
Hello, world.
输入样例2:
在这里给出一组输入。例如:
Hello, world.
输出样例2:
在这里给出相应的输出。例如:
Hello, world.
答案
def fun(sentence):
lists = []
# 放到列表判断
lists = sentence.split()
# 如果首字母不是大写,则转为大写
if lists[0].isupper()==False:
lists[0] = lists[0].capitalize()
word = lists[-1]
# 若最后一个单词的最后一个字符不是 '.' 则列表转字符串然后加'.'
if word[-1]!=".":
a = " ".join(lists)
a = a+'.'
else:
a = " ".join(lists)
return a
6-5 汉诺塔问题 (15 分)
汉诺塔问题求解:有三根相邻的柱子,假设标号分别为A、B、C,其中A柱子从下到上按金字塔状依次叠放了N个不同大小的圆盘,现要把A柱子上的所有圆盘一次一个地移动到C柱子上,移动的过程中可以借助B柱子做中转,并且每根柱子上的圆盘必须始终保持上小下大的叠放顺序。编写一个函数,输出移动轨迹(提示:用递归函数)
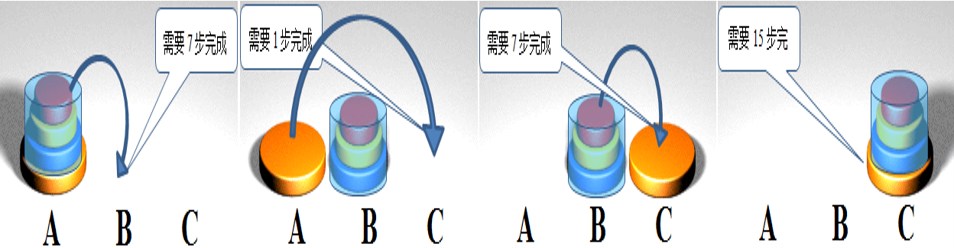
函数接口定义:
函数接口:
hanoi(n,a,b,c),print移动轨迹并统计移动次数
n表示要移动的圆盘个数,a,b,c为三根柱子名称,表示将盘子从a移动到c,b为中转柱。
裁判测试程序样例:
测试样例:
n=int(input())
step=0
hanoi(n,'A','B','C')
print('共移动次数:',step)
输入样例1:
输入n(1<=n<=5):
1
输出样例1:
在这里给出相应的输出。例如:
A -> C
共移动次数: 1
输入样例2:
输入n(1<=n<=5):
3
输出样例2:
在这里给出相应的输出。例如:
A -> C
A -> B
C -> B
A -> C
B -> A
B -> C
A -> C
共移动次数: 7
答案
# 从A经过B移动到C即要解决问题的整体思路,实用二叉树,可以实现汉诺塔问题
def hanoi(num, a, b, c):
# 声明全局变量,才能做到累加
global step
A=a
B=b
C=c
if num > 0:
step+=1
hanoi(num - 1, a, c, b) #从A经过C移动到B
print(A,"->",C)
hanoi(num - 1, b, a, c) #从B经过A移动到C
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









