







一、字符串String
- 单引号 ’ 和双引号 " 使用完全相同。
- 使用三引号(’’’ 或 “”")可以指定一个多行字符串。
- “\”反斜杠可以用来转义, r 可让反斜杠不发生转义。 如 r"this is Python\n" , \n 会显示出来,并不是换行。
- 字符串用 + 运算符连接在一起,用 * 运算符重复。
- 字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始
- 字符串不能改变,没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串的截取的语法格式如下:变量[头下标:尾下标:步长]

1.拼接字符时加入任何函数,都和没有的一样。
2.注意字符和数字不能一起打印,需要用函数强制转化为数字或直接字符输入。
二、数字Number
数字有四种类型:整数、布尔型、浮点数和复数( 1 + 2j、 1.1 + 2.2j),且只有一种整数类型 int,表示为长整型。
1、数值运算
9//3 #取整符
>>3
9//2
>>4
9%2 #取余符
>>1
8%2
>>0
4**2 #4的平方
>>16
2**4 #2的4次方
>>16
2^4 #这个不是平常的平方计算
>>6
2、整数运算
- 可以在同一行中使用多条语句,语句之间使用分号 ; 分割
- print 默认输出是换行的,若要不换行需要在变量末尾加上 end="":
#下面两个功能一样
print(1+2,end=" ");print(int('1')+2)
3、小数运算

float型数值与int型数值运算时,不能直接用int来转换,需要float来转换。
三、循环结构
1、while循环
1.在 Python 中没有 do…while 循环。
2.使用缩进来表示代码块,不需要使用大括号{},同一个代码块的语句必须包含相同的缩进空格数。
condition=1
while condition < 10: #格式:while true:(注意:后面的”:“不能省略)
# flase
print(condition)
condition=condition+2
注意:如果是while true:就会陷入无限循环中,可使用 CTRL+C 来退出当前的无限循环。
>>1
>>3
>>5
>>7
>>9
2、for循环
python_list=[3,6,8,9,1]
for i in python_list:
print(i)
print("inner of for")
print("outer of for")
#第一种情况
3
inner of for
6
inner of for
8
inner of for
9
inner of for
1
inner of for
outer of for
#第二种情况
>>3
>>6
>>8
>>9
>>1
>>outer of for
#range
for i in range(1,11): #只能打印小于11的数
print(i)
>>1
>>2
>>3
>>4
>>5
>>6
>>7
>>8
>>9
>>10
for i in range(1, 11,3): # 只能打印小于11的数,而且步长以3增加
print(i)
>>1
>>4
>>7
>>10
四、if条件结构
在Python中没有switch – case语句。
1、判断条件
<=、>=、!=、==,=不是判断条件,是赋值条件
if a_python<aPython>A_PYTHON: #(a_python<aPython>A_PYTHON)为true条件,可以多个判断
print(aPython , A_PYTHON)
>>13 11
2、深层次判断
c=8
if c<2: #多条件判断分开
print("fail")
elif c>1:
print("sucess")
else:
print("not sucess and fail")
>>sucess #第一种c=8,c<2,c>1
>>fail #第二种c=1,c<2,c>1
>>not sucess and fail #第二种c=1,c<1,c>1
五、def函数
1、一般定义调用
def learn_python(time,courses,note): #命名+变量
print(time,courses,note) #def函数前面空四个空格,才在def定义的函数内
learn_python(1,36,36) #一定要调用,否则没有值输出
1 36 36
2、默认定义
def learn_python1(time,courses=36,note=36): #可以在变量里定义默认值
print('time:',time,'courses:',courses,'note:',note)
learn_python1(1) #没有定义的需要赋予值,才能调用
>>time: 1 courses: 36 note: 36
3、默认注意
def learn_python(time,courses=36,note): #def定义的函数里面,如果有默认值和没有默认的值,需要把没有的全部写在前面,默认的放在后面,否则会出错
print(time,courses,note)
learn_python(1)

六、局部变量与全局变量
return [表达式] 结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
1、变量命名
#命名规则:
#(1)两个单词组成,用下斜杆连接
#(2)可以全部大写或如下面不用下斜杆,第二个单词首字母大写
a_python=10
A_PYTHON=11
aPython=12+1 #可以直接用变量来进行运算
a,b=6,8 #变量可以直接全部定义,逗号分割;也可以如上面分别定义
print(a_python,A_PYTHON,aPython,a,b)
>>10 11 13 6 8
2、局部变量与全局变量使用
#定义全局变量,第一种如PYTHON直接大写,第二种如a,先在前面定义为none,函数里面再用global定义,在输出时,需要先运行函数,才能输出函数里a值
PYTHON=100
a=None
def learn_python2():
global a
a=100
e=11
print(e)
return a+100
#第一种a为全局变量
print(PYTHON)
print('a past=',a) #没有运行learn_python2函数前,a的值
print(learn_python2()) #print打印调用函数,则a为全局变量的含义
print('a now=',a) #运行learn_python2函数后,a的值
>>
>100
>a past= None
>11
>200
>a now= 100
#第二种a为局部变量
learn_python2() #有return语句时,如果直接调用函数,则a的值只有局部变量含义
>>
>100
>a past= None
>11
>a now= 100
#第三种有调用函数和print打印调用函数,无论是函数在哪,a都只有局部变量的含义
learn_python2() #有return语句时,如果直接调用函数,则a的值只有局部变量含义
print(learn_python2()) #print打印调用函数,则a为全局变量的含义,但是如果两者都有,无论是函数在哪,a都只有局部变量的含义
>>
>100
>a past= None
>11
>
>11
>200
>a now= 100
七、读写文件
1、读文件
text='Good morning.\n''I am very glad to have the opportunity write Python.\n' #文档中每一句都需要‘’+\n括起来
append_text='\nThis is my text.' #追加文件
my_introduce=open('myIntroduce.text','w') #open如果没有该文件,则会首先创建,然后再写入
my_introduce.write(text) #写入
my_introduce.write(append_text) #追加
my_introduce.close() #一定要关闭,否则没有结果

2、写文件
f.readline() 会从文件中读取单独的一行,换行符为 ‘\n’
f.readline() 如果返回一个空字符串,说明已经已经读取到最后一行。
f.readlines() 将返回该文件中包含的所有行。
#基础读
readfile=open('myIntroduce.text','r')
read_content=readfile.read()
print(read_content)
>>
>Good morning.
>I am very glad to have the opportunity write Python.
>This is my text.
#类似python_list=[1,2,3,'291','277'],一行一行读出放在list中;readline只读前面一行,readlines全部读出
readfile=open('myIntroduce.text','r')
read_line=readfile.readline()
read_lines=readfile.readlines()
print(read_line)
print()
print(read_lines)
>>
>>Good morning.
>
>['Good morning.\n', 'I am very glad to have the opportunity write Python.\n', 'This is my text.']
3、input
str(): 函数返回一个用户易读的表达形式。
p_input=input('Please give a number:')
if p_input==1:
print('The input number is:',p_input)
elif p_input==6:
print('you are fail!')
else:
print('lucky')
>>
>Please give a number:1
>lucky
>
>Please give a number:6
>lucky
>
>Please give a number:8
>lucky
注:由于input定义的是字符串,此时无论输出何值,输出都是lucky,因为int型值不能匹配,下面有两种改进方法
#第一种,把输入的input转化为int型
p_input=int(input('Please give a number:'))
if p_input==1:
print('The input number is:',p_input)
elif p_input==6:
print('you are fail!')
else:
print('lucky')
>>
>Please give a number:1
>The input number is: 1
>
>Please give a number:6
>you are fail!
#第二种,if中数值中用‘’括起来或str转化数值
p_input=input('Please give a number:')
if p_input=='1':
print('The input number is:',p_input)
elif p_input=='6':
print('you are fail!')
else:
print('lucky')
p_input=input('Please give a number:')
if p_input==str(1):
print('The input number is:',p_input)
elif p_input==str(6):
print('you are fail!')
else:
print('lucky')
>>
>Please give a number:6
>you are fail!
八、类
1.空行不是Python语法的一部分,书写时不插入空行,Python解释器运行也不会出错。但是空行是程序代码的一部分,作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
2.类的方法与普通的函数只有一个特别的区别——必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
3.类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类
class Cfile:
name = 'Good file'
#__init__() (构造方法),在类实例化时会自动调用
def __init__(self,name,content,time):
self.na=name
self.co=content
self.ti=time
def add(self,content, time):
print(self.name,content)
def update(self,time):
print(time,self.name)

九、元组Tuple和列表List
1.列表中元素的类型可不相同,支持数字,字符串以及嵌套列表;元组中的元素类型也可不相同
2.列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
3.元组写在小括号 () 里,元素之间用逗号隔开。
4.元组的元素不能修改,可包含可变的对象list列表;List中的元素是可以改变的
1、元组
#第一种定义
p_tuple=(3,6,1,8,9)
#第二种定义
another_tuple=6,8
#输出元组
for content in another_tuple: #从元组中取出值,一个一个输出
print(content)
>>
>6
>8
#索引输出
for index in range(len(p_tuple)): #range(5)生成长度为5的迭代器,从0到4,index为其索引
print('index=',index,'number=',p_tuple[index])
>>
>index= 0 number= 3
>index= 1 number= 6
>index= 2 number= 1
>index= 3 number= 8
>index= 4 number= 9
2、列表
#列表定义形式
p_list=[6,9,1,8,3]
#索引输出
for index in range(len(p_list)):
print('index=',index,'number=',p_list[index])
>>
>index= 0 number= 6
>index= 1 number= 9
>index= 2 number= 1
>index= 3 number= 8
>index= 4 number= 3
3、多维列表
#定义多维列表
multi_list=[[1,2,3],
[4,5,6],
[7,8,9]]
print(multi_list[2][1]) #按第三行第二列打印数值
>>
>8
4、索引用法
(1)列表
p_list.append(66) #在列表后面追加值66
print(p_list)
p_list.insert(1,88) #在列表第一个位置上添加值88
print(p_list)
print(p_list[0]) #打印该列表第一位的数
print(p_list[-1]) #打印该列表最后一位的数
print(p_list[0:3]) #或another_tuple[:3]表示打印该列表前三位的数值
print(p_list[3:]) #打印第三位后面的数值
print(p_list[-3:]) #打印最后面三位数值
print(p_list.index(66)) #输出66的索引,也就是66在该列表中的位置
print(p_list.count(88)) #计算该列表中出现88数值的个数
p_list.sort() #必须先在外面排序,再打印
print(p_list) #对列表从小到大排序,再输出
p_list.sort(reverse=True)
print(p_list) #对列表按从大到小输出
p_list.remove(1) #从列表中移除值为1的数,如果有相同值,则是最前面的
print(p_list)
>>
>[6, 9, 1, 8, 3, 66]
>[6, 88, 9, 1, 8, 3, 66]
>6
>66
>[6, 88, 9]
>[1, 8, 3, 66]
>[8, 3, 66]
>6
>1
>[1, 3, 6, 8, 9, 66, 88]
>[88, 66, 9, 8, 6, 3, 1]
>[88, 66, 9, 8, 6, 3]
(2)元组
print(p_tuple[0]) #打印该元组第一位的数
print(p_tuple[-1]) #打印该元组最后一位的数
print(p_tuple[0:3]) #或another_tuple[:3]表示打印该数组前三位的数值
print(p_tuple[3:]) #打印第三位后面的数值
print(p_tuple[-3:]) #打印最后面三位数值
print(p_tuple.index(6)) #输出66的索引,也就是66在该元组中的位置
print(p_tuple.count(8)) #计算该元组中出现88数值的个数
>>
>3
>9
>(3, 6, 1)
>(8, 9)
>(1, 8, 9)
>1
>1
十、字典Dictionary
- 列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
- 键必须是唯一的,但值则不必。
3.值可以取任何数据类型,但键必须是不可变的,如字符串,数字,或元组充当,而用列表就不行。
#字典用{ }标识,是一个无序的键(key) : 值(value) 的集合,可字符与字符,字符与数值和数值与数值形式
d={'python':'p','java':'j','c':2,1:1}
print(d['python'])
# 在同一个字典中,键(key)必须是唯一的,删除一个元素时,用前面的键
del d['java']
print(d)
# 字典添加一个元素
d['ja']='ja'
print(d)
#字典复杂定义形式,可以多种形式嵌套
dd={'python':[1,2,3],'java':{'j':'a','v':'a'},'c':['c','c++']}
print(dd['java']['v'])
>>
>p
>{'python': 'p', 'c': 2, 1: 1}
>{'python': 'p', 'c': 2, 1: 1, 'ja': 'ja'}
>a
十一、加载模块
1、库中模块
#将整个模块(time)导入,格式为: import time
import time
print(time.localtime())
# 名字替代
import time as t
print(t.time())
# 从某个模块中导入多个函数,格式为: from time import time, localtime
from time import time,localtime
print(localtime())
print(time)
# 将某个模块中的全部函数导入,格式为: from time import *
from time import *
print(gmtime())
print()
>>
>time.struct_time(tm_year=2022, tm_mon=3, tm_mday=7, tm_hour=16, tm_min=42, tm_sec=53, tm_wday=0, tm_yday=66, tm_isdst=0)
>1646642573.4760947
>time.struct_time(tm_year=2022, tm_mon=3, tm_mday=7, tm_hour=16, tm_min=42, tm_sec=53, tm_wday=0, tm_yday=66, tm_isdst=0)
>1646642573.4760947
>time.struct_time(tm_year=2022, tm_mon=3, tm_mday=7, tm_hour=8, tm_min=42, tm_sec=53, tm_wday=0, tm_yday=66, tm_isdst=0)
2、自己定义
(1)定义模块impot.py
def importData(data):
print('I am impot!')
print(data)
(2)a.p加载impot.py使用
import impot
impot.importData('I am learning python!')
>>
>I am impot!
>I am learning python!
十二、break和continue
1、一般终止
# 一般循环,当python_1==1时,先执行print('still in while')语句,才终止循环
python=True
while python:
python_1=int(input('please print python'))
if python_1==1:
python=False
else:
pass #什么都不做,跳过
print('still in while')
print('finish run') #终止循环

2、break
#break-当python_2==2时,直接终止循环,不再执行下面的print('still in while')
while True:
python_2 = int(input('please print python'))
if python_2==2:
break
else:
pass
print('still in while')
print('finish run')

3、continue
#continue-当python_3==3时,直接跳过下面所有语句,进入下一个循环,一直在循环中
while True:
python_3= int(input('please print python'))
if python_3==3:
continue
else:
pass
print('still in while')
print('finish run')

十三、错误处理
#r:以只读方式打开文件。
#r+:打开一个文件用于读写。
try:
file=open('ee','r') #当文件创建成功后,必须改为“r+”格式,因为此时文件已经存在,而且需要写入eee
except Exception as e:
print('there is no file ee')
response = input('do you want to create a new file!')
if response == 'y': #‘y’时就会创建文件ee,否则跳过
file=open('ee','w')
else:
pass
else:
file.write('eee')
file.close()

十四、函数
1、zip
作用: 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象。
a,b=[1,2,3],[4,5,6]
print(list(zip(a,b))) #zip作用:把两个列表按列来组合在一起
#zip中a的第一位和b的第一位进行运算,以此类推
for i,j in zip(a,b):
print(i*2,j/2)
#zip多个元素进行组合
print(list(zip(b,b,a)))
>>
>[(1, 4), (2, 5), (3, 6)]
>
>2 2.0
>4 2.5
>6 3.0
>
>[(4, 4, 1), (5, 5, 2), (6, 6, 3)]
2、lamba——创建匿名函数
- lambda 只是一个表达式,函数体比 def 简单很多。
lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda表达式中封装有限的逻辑进去。
lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
虽然 lambda函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
#一般运算
def add1(x,y):
return (x+y)
print(add1(2,3))
>>
>5
#lamba运算,加简便
add2=lambda x,y:x+y
print(add2(2,3))
>>
>5
3、map——根据提供的函数对指定序列做映射
1.语法:map(function – 函数,iterable – 一个或多个序列)
2.返回值:返回一个迭代器
print(list(map(add1,[1],[2])))
>>
>[3]
print(list(map(add1,[1,3],[2,4]))) #1和2相加,3和4相加,再组合
>>
>[3, 7]
十五、复制
1、一般复制
#一般复制,通过复制后,完全一样,改变一个,另一个也会改变,因为所用内存地址是一个的
a=[1,2,3]
b=a
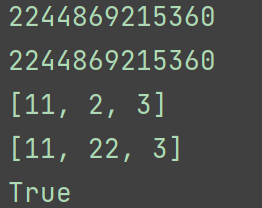
print(id(a))
print(id(b))
b[0]=11
print(a)
a[1]=22
print(b)
print(id(a)==id(b))
2、copy
```python
#copy-第一层指定在不同空间,不在同一空间,改变值的话不影响另外一个
c=copy.copy(a)
print(id(c)==id(a))
c[2]=33
print(a)
>>
>False
>[11, 22, 3]
#copy-第二层指定在同一空间,这时改变一个的值,另外的也会改变
aa=[1,2,[3,4]]
cc=copy.copy(aa)
print(id(cc)==id(aa))
print(id(aa[2])==id(cc[2]))
>>
>False
>True
cc[0]=11
print(aa)
aa[2][0]=111
print(cc)
print()
>>
>[1, 2, [3, 4]]
>[11, 2, [111, 4]]
3、deepcopy
#deepcopy完完全全复制过来,任何东西都不会重复,即内存空间不一样,但是对应值的空间是一样的
d=copy.deepcopy(b)
print(id(d)==id(b))
print(id(b[2])==id(d[2]))
>>
>False
>True
十六、pickle
pickle模块实现了基本的数据序列和反序列化。
(1)通过pickle模块的序列化操作能够将程序中运行的对象信息保存到文件中去,永久存储。
(2)通过pickle模块的反序列化操作,能够从文件中创建上一次程序保存的对象。
# pickle:保存和提取字典、列表以及变量等
import pickle
p_dict={'java':'ja',369:[16,69],'va':{6:8,'java':'va'}}
file=open('pickle_exam.pickle','wb') #以写入二进制形式**写入**
pickle.dump(p_dict,file) #把p_dict装入file中
file.close()
#第一种打开文件形式,能够自动关闭
with open('pickle_exam.pickle','rb') as file: #打开后可自动关闭,rb:以二进制格式打开一个文件用于只读。
p_dict1=pickle.load(file)
#第二种打开文件形式,不能自动关闭
file=open('pickle_exam.pickle','rb') #**读出**
p_dict1=pickle.load(file)
file.close()
print(p_dict1)
>>
>{'java': 'ja', 369: [16, 69], 'va': {6: 8, 'java': 'va'}}
十七、集合set
- 集合(set)是由一个或数个形态各异的大小整体组成的
2.type() 函数可以用来查询变量所指的对象类型- isinstance 和 type 的区别在于:
(1)type()不会认为子类是一种父类类型。
(2)isinstance()会认为子类是一种父类类型。
4.可用大括号 { } 或者 set() 函数创建集合,但是创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
#set找不同之处,去除重复的,留下不一样的;没有按顺序;不能传列表+列表的形式,只能单独
char_list=['a','a','b','c','c','c']
print(set(char_list))
print(type(set(char_list))) #打印出该类型
>>
>{'b', 'a', 'c'}
><class 'set'>
#空格也是重复的,相当于字符串,而且区分大小写
sentence='Welcome to the Python!'
print(set(sentence))
>>
>{'e', 'y', 'm', 't', 'W', 'h', 'l', 'c', 'o', 'P', 'n', ' ', '!'}
#追加,只能单独加一个;如果存在没有变化
unique_char=set(char_list)
unique_char.add('x')
print(unique_char)
>>
>{'a', 'x', 'c', 'b'}
#单独去除,remove如果列表中没有会报错,有的话返回none;discard的话没有返回none,没有报错
print(unique_char.remove('x'))
print(unique_char)
>>
>None
>{'c', 'a', 'b'}
print(unique_char.discard('x'))
print(unique_char)
>>
>None
>{'c', 'b', 'a'}
# 找出一个有,另一个没有的
set1=unique_char
set2={'a','c','d'}
print(set1.difference(set2)) #不同的
print(set1.intersection(set2)) #相同的
>>
>{'b'}
>{'a', 'c'}
#全部去除,传回空set
unique_char.clear()
print(unique_char)
>>
>set()
remove中出错的

十八、正则表达式
(一)一般匹配
1、简单Python匹配
word1='python'
word2='c'
string='python and java'
print(word1 in string)
print(word2 in string)
>>
>True
>False
2、用正则寻找常规配对
word1='python'
word2='c'
string='python and java'
print(re.search(word1,string))
print(re.search(word2,string))
>>
><re.Match object; span=(0, 6), match='python'>
>None
3、匹配多种可能,使用[]
print(re.search('r[au]n','ran and runs')) #只能匹配前面的
print(re.search(r'r[A-Z]n','ran and run')) #大写字母
print(re.search(r'r[a-z]n','ran and run')) #小写字母
print(re.search(r'r[0-9]n','ran and r2n')) #数字
print(re.search(r'r[0-9a-z]n','r2n and runs')) #小写字母和数字
>>
><re.Match object; span=(0, 3), match='ran'>
>None
><re.Match object; span=(0, 3), match='ran'>
><re.Match object; span=(8, 11), match='r2n'>
><re.Match object; span=(0, 3), match='r2n'>
(二)特殊种类匹配
1、数字
print(re.search(r'r\dn','run r6n'))#\d所有数字的形式
print(re.search(r'r\Dn','run r6n'))#\D所有不是数字的形式
>>
><re.Match object; span=(4, 7), match='r6n'>
><re.Match object; span=(0, 3), match='run'>
2、空白
print(re.search(r'r\sn','r\nn r4n'))#\s任何空白符,如[\t\n\f\v]
print(re.search(r'r\Sn','r\nn r4n'))#\S任何不是空白符
>>
><re.Match object; span=(0, 3), match='r\nn'>
><re.Match object; span=(4, 7), match='r4n'>
3、所有字母数字和“_”
print(re.search(r'r\wn','r\nn r4n'))#\w和所有字母数字以及“_”匹配
print(re.search(r'r\Wn','r\nn r4n'))#\W除开所有字母数字和“_”的
>>
><re.Match object; span=(4, 7), match='r4n'>
><re.Match object; span=(0, 3), match='r\nn'>
4、前后空白字符
print(re.search(r'\bruns\b','ran and runs'))#\b匹配runs前后有空白的字符,前后有两个字符或是只有一个都匹配不到
print(re.search(r'\B runs \B','ran and runs '))#\B匹配前后有多个空白的字符,而且'\B runs \B'中字符必须空格
>>
><re.Match object; span=(8, 12), match='runs'>
><re.Match object; span=(8, 14), match=' runs '>
5、任意字符
print(re.search(r'runs\\','runs\ and ran'))#\\匹配字符\
print(re.search(r'r.n','r[ns and ran'))#.匹配除开"\"的任何字符
>>
><re.Match object; span=(0, 5), match='runs\\'>
><re.Match object; span=(0, 3), match='r[n'>
6、句尾句首
print(re.search(r'^runs','runs and ran'))#^匹配在句首的单词
print(re.search(r'ran$','runs and ran'))#$匹配在句尾的单词
>>
><re.Match object; span=(0, 4), match='runs'>
><re.Match object; span=(9, 12), match='ran'>
7、是否
# “?”出现或不出现都匹配
print(re.search(r'Tues(day)?','Tuesday'))
print(re.search(r'Tue(sday)?','Tues'))
>>
><re.Match object; span=(0, 7), match='Tuesday'>
><re.Match object; span=(0, 3), match='Tue'>
8、多行匹配
print(re.search(r'^re','runs and ran\nren and rbn'))
print(re.search(r'rbn$','runs and ran\nren and rbn',flags=re.M))#flags把一段话分成每一句话,从而去匹配
>>
>None
><re.Match object; span=(21, 24), match='rbn'>
9、0或多次
#“*”可以匹配后面出现0次的,也可以匹配出现多次的
print(re.search(r'ru*','r'))#前面不同字符不能超过一个,也就是如果是run*,则none不能匹配到
print(re.search(r'run*','runnnnnnn'))
>>
><re.Match object; span=(0, 1), match='r'>
><re.Match object; span=(0, 9), match='runnnnnnn'>
10、1或多次
#“+”只能匹配后面出现1次或多次,不能0次
print(re.search(r'ru+','r'))
print(re.search(r'run+','runnnnnnn'))
>>
>None
><re.Match object; span=(0, 9), match='runnnnnnn'>
11、可选次数
#{n,m}表示出现n次到m次
print(re.search(r'ru{1,10}','r'))#'r{1,10}'可以匹配到'r','ru{1,10}'不能匹配到'r'
print(re.search(r'run{2,10}','runnnnnnn'))
>>
>None
><re.Match object; span=(0, 9), match='runnnnnnn'>
12、group组
#按第1,2组……形式来匹配
sens=re.search(r'(\d+),Date:(.+)','ID:291277,Date:Tuesday/8/3/2022')
print(sens.group())
print(sens.group(1))
print(sens.group(2))
>>
>291277,Date:Tuesday/8/3/2022
>291277
>Tuesday/8/3/2022
#?P<名字>按名字来匹配
sense=re.search(r'(?P<id>\d+),Date:(?P<date>.+)','ID:291277,Date:Tuesda/8/3/2022')
print(sense.group('id'))
print(sense.group('date'))
>>
>291277
>Tuesda/8/3/2022
13、寻找所有匹配
print(re.findall(r'r[ua]n','ran and rbn run'))#一次性寻找出所有匹配的
print(re.findall(r'run|rbn','ran and rbn run'))#"|"表示或者
>>
>['ran', 'run']
>['rbn', 'run']
14、替换
print(re.sub(r'r[ua]n','rmn','ran and rbn run'))#寻找匹配的替换成rmn
>>
>rmn and rbn rmn
15、分裂
print(re.split(r'[,;\.]','r,u;n.d\e'))#"."匹配除开\字符的任何字符,\.去除字符后的"."字符
>>
>['r', 'u', 'n', 'd\\e']
16、compile
compile_re=re.compile(r'r[ua]n')#先编译
print(compile_re.search('runs and ran'))#再匹配
>>
><re.Match object; span=(0, 3), match='run'>















 3642
3642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









