







目录
一、YARN系统架构
YARN是一个全局的资源管理器和作业调度平台。
YARN的基本思想是将资源管理和作业调度/监视功能划分为单独的守护进程。其思想是拥有一个全局ResourceManager (RM),以及每个应用程序拥有一个ApplicationMaster (AM)。应用程序可以是单个作业,也可以是一组作业。
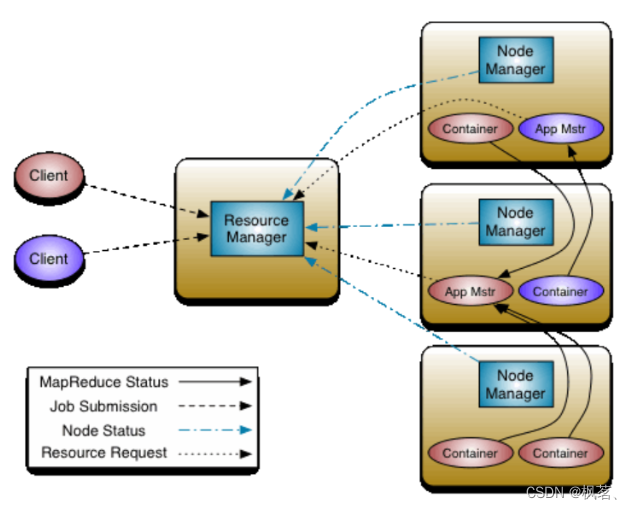
一个ResourceManager和多个NodeManager构成了YARN资源管理框架。他们是YARN启动后长期运行的守护进程,来提供核心服务。
- ResourceManager:是在系统中的所有应用程序之间仲裁资源的最终权威,即管理整个集群上的所有资源分配,内部含有一个Scheduler(资源调度器)
- NodeManager:是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器(container)资源使用情况,并向ResourceManager及其 Scheduler报告使用情况
- container:集群上的可使用资源的抽象,包含cpu、内存、磁盘、网络等
- ApplicationMaster(简称AM):每启动一个应用程序,都会启动一个AM,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务
二、 YARN的配置
YARN属于Hadoop的核心组件,不需要单独安装,只需要修改一些配置文件即可。
2.1 修改配置文件
①mapred-site.xml
<configuration>
<!-- 指定MapReduce作业执行时,使用YARN进行资源调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定MapReduce作业执行时,需要使用到的路径 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
</configuration>②yarn-site.xml
<configuration>
<!-- 设置ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>user1</value>
</property>
<!--配置yarn的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>③hadoop-env.sh
# 添加如下,如果有就不用配置:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root④ 分发到其他节点
#分发hadoop配置到user2和user3服务器对应位置
scp -r /usr/local/hadoop-3.3.1/etc/hadoop/* user2:/usr/local/hadoop-3.3.1/etc/hadoop/
scp -r /usr/local/hadoop-3.3.1/etc/hadoop/* user3:/usr/local/hadoop-3.3.1/etc/hadoop/
2.2 YARN的服务启停
| 描述 | 命令 |
| 开启YARN全部服务 | start-yarn.sh |
| 停止YARN全部服务 | stop-yarn.sh |
| 单点开启YARN相关进程 | yarn --daemon start resourcemanager |
| 单点停止YARN相关进程 | yarn --daemon stop resourcemanager |
当YARN的进程开启之后,我们可以在WebUI上查看到集群的资源信息、任务的运行状态等
2.3 任务测试
当开启所有的YARN的进程之后,我们再次运行之前的Hadoop的官方案例: wordcount
[root@user1 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
当任务运行起来之后,我们可以在WebUI上查看到任务的运行状态: http://192.168.10.101:8088
三、YARN的历史日志
3.1 历史日志概述
我们在YARN运行MapReduce的程序的时候,任务会被分发到不同的节点,在不同的Container内去执行。如果一个程序执行结束后,我们想去查看这个程序的运行状态呢?每一个MapTask的执行细节?每一个ReduceTask的执行细节?这个时候我们是查看不到的,因此我们需要开启记录历史日志的服务。
历史日志服务开启之后,Container在运行任务的过程中,会将日志记录下来,保存到当前的节点。例如: 在user2节点上开启了一个Container去执行MapTask,那么此时就会在qianfeng02的$HADOOP_HOME/logs/userlogs中记录下来日志。我们可以到不同的节点上去查看日志。虽然这样可以查看,但是很不方便!因此,我们一般还会开启另外的一个服务: 日志聚合。顾名思义,就是将不同节点的日志聚合到一起保存起来。
3.2 mr-historyserver
顾名思义,就是去记录MapReduce的历史日志的。接下来我们从配置开始、到日志聚合、运行任务去讲解。
3.3 配置文件
①mapred-site.xml
<!-- 添加如下配置 -->
<!-- 历史任务的内部通讯地址 -->
<property>
<name>MapReduce.jobhistory.address</name>
<value>user1:10020</value>
</property>
<!--历史任务的外部监听页面-->
<property>
<name>MapReduce.jobhistory.webapp.address</name>
<value>user1:19888</value>
</property>②yarn-site.xml
<!-- 添加如下配置 -->
<!-- 是否需要开启日志聚合 -->
<!-- 开启日志聚合后,将会将各个Container的日志保存在yarn.nodemanager.remote-app-log-dir的位置 -->
<!-- 默认保存在/tmp/logs -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 历史日志在HDFS保存的时间,单位是秒 -->
<!-- 默认的是-1,表示永久保存 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://user1:19888/jobhistory/logs</value>
</property>③分发
#分发hadoop配置到user2和user3服务器对应位置
scp -r /usr/local/hadoop-3.3.1/etc/hadoop/* user2:/usr/local/hadoop-3.3.1/etc/hadoop/
scp -r /usr/local/hadoop-3.3.1/etc/hadoop/* user3:/usr/local/hadoop-3.3.1/etc/hadoop/
3.4 开启历史服务
# 重启YARN集群
[root@user1 ~]# stop-yarn.sh
[root@user1 ~]# start-yarn.sh
# 打开历史服务
[root@user1 ~]# mapred --daemon start historyserver# 开启之后,通过jps可以查看到 JobHistoryServer 进程,表示开启成功
3.5 执行任务
[root@user1 ~]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output
以官方案例wordcount为例,现在在运行完这个任务后,就会在WebUI上看到这个任务。我们可以点击任务的ID进入到任务的详情页,此时可以查看日志。

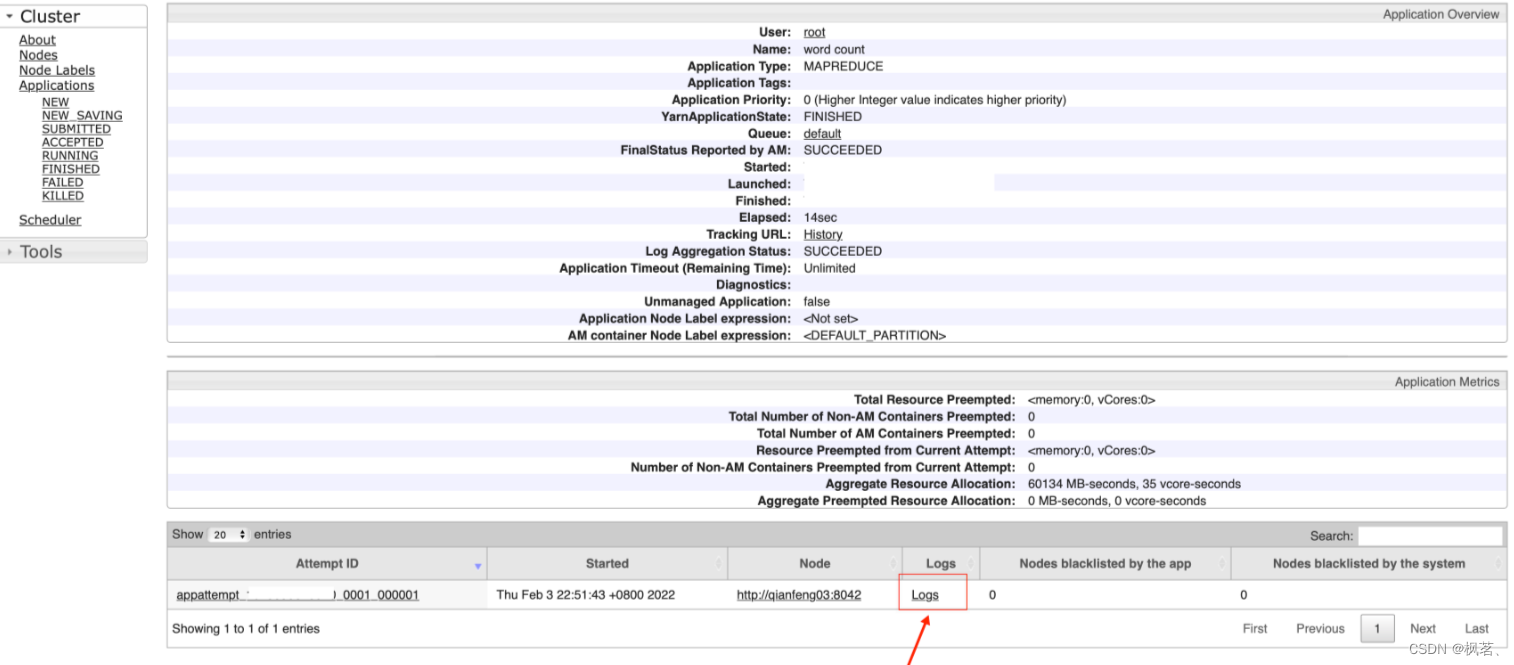 也可以在http://192.168.10.101:19888查看每一个MapTask、ReduceTask的日志
也可以在http://192.168.10.101:19888查看每一个MapTask、ReduceTask的日志


四、YARN的Job提交
在MR程序运行时,有五个独立的进程:
- YarnRunner: 用于提交作业的客户端程序
- ResourceManager: yarn资源管理器,负责协调集群上计算机资源的分配
- NodeManager: yarn节点管理器,负责启动和监视集群中机器上的计算容器(container)
- Application Master: 负责协调运行MapReduce作业的任务,他和任务都在容器中运行,这些容器由资源管理器分配并由节点管理器进行管理。
- HDFS:用于共享作业所需文件。

1. 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到控制台
2. JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。
3. 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10.
4. 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。
5. ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。
6. application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。
7. 然后从HDFS上接受资源,主要是split。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配
8. 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。(5%)
9. 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。
10. 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件)
11. 然后开始运行MapTask或ReduceTask。
12. 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台
五、YARN的命令
- yarn top
类似于Linux的top命令,查看正在运行的程序资源占用情况。
- yarn queue -status root.default
查看指定队列使用情况,下文会讲解任务队列
- yarn application
-list
# 通过任务的状态,列举YARN的任务。使用 -appStates 指定状态
# 任务状态: ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED
# 查看所有正在运行的任务
[root@user1 ~]# yarn application -list -appStates RUNNING
# 查看所有的失败的任务
[root@user1 ~]# yarn application -list -appStates FAILED
-movetoqueue
# 将一个任务移动到指定的队列中
[root@user1 ~]# yarn application -movetoqueue application_xxxxxx_xxx -queue root.small
-kill
#杀死指定的任务
[root@user1 ~]# yarn application -kill application_xxxxxx_xxx
- yarn container
-list
# 查看正在执行的任务的容器信息
[root@user1 ~]# yarn container -list application_xxxxxx_xxx
-status
# 查看指定容器信息
[root@user1 ~]# yarn container -status container_xxxxx
- yarn jar
# 提交任务到YARN执行
[root@user1 ~]# yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar /input /output
- yarn logs
# 查看YARN的程序运行时的日志信息
[root@user1 ~]# yarn logs -applicationId application_1528080031923_0064
- yarn node -all -list
查看所有节点信息















 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









