







目录
二、SparkSQL的编程模型(DataFrame和DataSet)
2.6 SparkSQL的DataFrame和DataSet创建
一、SparkSQL介绍
SparkSQL,顾名思义,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。SparkSQL的前身不叫SparkSQL,而叫Shark,最开始的时候底层代码优化,sql的解析、执行引擎等等完全基于Hive,总是Shark的执行速度要比Hive高出一个数量级,但是hive的发展制约了Shark,所以在15年中旬的时候,Shark负责人,将Shark项目结束掉,重新独立出来的一个项目,就是SparkSQL,不在依赖Hive,做了独立的发展,逐渐的形成两条互相独立的业务:SparkSQL和Hive-On-Spark。在SparkSQL发展过程中,同时也吸收了Shark有些的特点:基于内存的列存储,动态字节码优化技术。
Spark SQL是用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。有几种与Spark SQL交互的方法,包括SQL和Dataset API。计算结果时,将使用相同的执行引擎,这与用于表示计算的API/语言无关。这种统一意味着开发人员可以轻松地在不同的API之间来回切换,基于API的切换提供了表示给定转换的最自然的方式。
SparkSQL就是Spark生态体系中用于处理结构化数据的一个模块。
- 结构化数据是什么?
- 存储在关系型数据库中的数据,就是结构化数据.
- 半结构化数据是什么?
- 类似xml、json等的格式的数据被称之为半结构化数据.
- 非结构化数据是什么?
- 音频、视频、图片等为非结构化数据.
换句话说,SparkSQL处理的就是二维表数据。
二、SparkSQL的编程模型(DataFrame和DataSet)
2.1 编程模型简介
主要通过两种方式操作SparkSQL,一种就是SQL,另一种为DataFrame和Dataset。
- SQL
SQL不用多说,就和Hive操作一样,但是需要清楚一点的时候,SQL操作的是表,所以要想用SQL进行操作,就需要将SparkSQL对应的编程模型转化成为一张表才可以。
同时支持,通用SQL和HQL。
- DataFrame和Dataset
DataFrame和Dataset是SparkSQL中的编程模型。DataFrame和Dataset我们都可以理解为是一张mysql中的二维表,表有什么?表头,表名,字段,字段类型。RDD其实说白了也是一张二维表,但是这张二维表相比较于DataFrame和Dataset却少了很多东西,比如表头,表名,字段,字段类型,只有数据。
Dataset是在spark1.6.2开始出现出现的api,DataFrame是1.3的时候出现的,早期的时候DataFrame叫SchemaRDD,SchemaRDD和SparkCore中的RDD相比较,就多了Schema,所谓约束信息,元数据信息。
一般的,将RDD称之为Spark体系中的第一代编程模型;DataFrame比RDD多了一个Schema元数据信息,被称之为Spark体系中的第二代编程模型;Dataset吸收了RDD的优点(强类型推断和强大的函数式编程)和DataFrame中的优化(SQL优化引擎,内存列存储),成为Spark的最新一代的编程模型。
2.2 RDD\DataSet\DataFrame
RDD
弹性分布式数据集,是Spark对数据进行的一种抽象,可以理解为Spark对数据的一种组织方式,更简单些说,RDD就是一种数据结构,里面包含了数据和操作数据的方法。
从字面上就能看出的几个特点:
●弹性:
- 数据可完全放内存或完全放磁盘,也可部分存放在内存,部分存放在磁盘,并可以自动切换
- RDD出错后可自动重新计算(通过血缘自动容错)
- 可checkpoint(设置检查点,用于容错),可persist或cache(缓存)
- 里面的数据是分片的(也叫分区,partition),分片的大小可自由设置和细粒度调整
●分布式:
- RDD中的数据可存放在多个节点上
相对于与DataFrame和Dataset,RDD是Spark最底层的抽象,目前是开发者用的最多的,但逐步会转向DataFrame和Dataset(当然,这是Spark的发展趋势)
DataFrame
DataFrame:理解了RDD,DataFrame就容易理解些,DataFrame的思想来源于Python的pandas库,RDD是一个数据集,DataFrame在RDD的基础上加了Schema(描述数据的信息,可以认为是元数据,DataFrame曾经就有个名字叫SchemaRDD)
假设RDD中的两行数据长这样;
| 1 | 张三 | 20 |
| 2 | 李四 | 21 |
| 3 | 王五 | 2 |
那么在DataFrame中数据就变成这样;
| ID:Int | Name:String | Age:Int |
| 1 | 张三 | 20 |
| 2 | 李四 | 21 |
| 3 | 王五 | 22 |
从上面两个表格可以看出,DataFrame比RDD多了一个表头信息(Schema),像一张表了,DataFrame还配套了新的操作数据的方法等,有了DataFrame这个高一层的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了,对开发者来说,易用性有了很大的提升。,不仅如此,通过DataFrame API或SQL处理数据,会自动经过Spark 优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快。
Dataset
相对于RDD,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。
假设RDD中的两行数据长这样;
| 1 | 张三 | 20 |
| 2 | 李四 | 21 |
| 3 | 王五 | 22 |
那么在DataSet中数据就变成这样;
| Person(id:Int,Name:String,Age:Int) |
| Person(1,张三,20) |
| Person(2,李四,21) |
| Person(3,王五,22) |
目前仅支持Scala、Java API,尚未提供Python的API(所以一定要学习Scala),相比DataFrame,Dataset提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,实在是想骂人,这也是引入Dataset的一个重要原因。
使用DataFrame的代码中json文件中并没有score字段,但是能编译通过,但是运行时会报异常!如下代码所示。
val df1 = spark.read.json( "/tmp/people.json")
// json文件中没有score字段,但是能编译通过
val df2 = df1.filter("score > 60")
df2.show()
而使用Dataset实现,会在IDE中就报错,出错提前到了编译之前
val ds1 = spark.read.json( "/tmp/people.json" ).as[People]
// 使用dataset这样写,在IDE中就能发现错误
val ds2 = ds1.filter(_.score < 60)
val ds3 = ds1.filter(_.age < 18)
// 打印
ds3.show( )
三者的区别
RDD
- RDD一般和Spark MLib同时使用
- RDD不支SparkSQL操作
DataFrame
- 与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析(模式匹配)才能获取各个字段的值
- DataFrame与DataSet一般不与 Spark MLib 同时使用
- DataFrame与DataSet均支持 SparkSQL 的操作
DataSet
- Dataset每一行的数据类型可以不同。
2.3 SparkSQL的编程入口
在SparkSQL中的编程模型,不再是SparkContext,但是创建需要依赖SparkContext。SparkSQL中的编程模型,在spark2.0以前的版本中为SQLContext和HiveContext,HiveContext是SQLContext的一个子类,提供Hive中特有的一些功能,比如row_number开窗函数等等,这是SQLContext所不具备的,在Spark2.0之后将这两个进行了合并——SparkSession。SparkSession的构建需要依赖SparkConf或者SparkContext。使用工厂构建器(Builder方式)模式创建SparkSession。
SparkSession如何实例化
通过静态类Builder来实例化。
Builder又有很多方法,包括:
1) appName函数
appName(String name)
用来设置应用程序名字,会显示在Spark web UI中
值类型:SparkSession.Builder
2) config函数
这里有很多重载函数。其实从这里我们可以看出重载函数,是针对不同的情况,使用不同的函数,但是他们的功能都是用来设置配置项的。
如config(SparkConf conf)
根据给定的SparkConf设置配置选项列表。
config(String key, String value)
设置配置项,针对值为String 的
值类型:SparkSession.Builder
3) enableHiveSupport函数
表示支持Hive,包括 链接持久化Hive metastore, 支持Hive serdes, 和Hive用户自定义函数
值类型:SparkSession.Builder
4) getOrCreate函数
getOrCreate()
获取已经得到的 SparkSession,或则如果不存在则创建一个新的基于builder选项的SparkSession
值类型:SparkSession
5) master函数
master(String master)
设置Spark master URL 连接,比如"local" 设置本地运行,"local[4]"本地运行4cores,或则"spark://master:7077"运行在spark standalone 集群。
值类型:SparkSession.Builder
SparkSession对象的常用方法
1)SparkSession.read()
返回一个DataFrameReader,可用于读取多种格式的文件,生成DataFrame
2)SparkSession.readStream()
用于读取数据流生成流式DataFrame,还处于实验阶段
3)SparkSession.sql()
将sql语句对应的查询结果以DataFrame的形式返回
4)SparkSession.stop()
关闭SparkSession对象,终止底层SparkContext,释放资源
2.4 SparkSQL基本编程
创建SparkSQL的模块
创建工程省略,直接在原有工程引入Pom即可
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>2.5 SparkSQL编程初体验
SparkSession的构建
val spark = SparkSession.builder()
.appName("SparkSQLOps")
.master("local[*]")
//.enableHiveSupport()//支持hive的相关操作
.getOrCreate()
Demo
package com.sparkSQL_example
import org.apache.spark.sql.{Column, SparkSession}
object SparkSQL_demo1 {
def main(args: Array[String]): Unit = {
//1、获取sparkSQL的上下文
val sparksql = SparkSession
.builder()
.master("local[*]")
.appName("sparkSQL1")
//.enableHiveSupport() //支持操作hive
.getOrCreate()
//2、读取数据源
val df = sparksql.read.json("C:\\Users\\80621\\Desktop\\data\\sqldata\\people.json")
//3、对初始化后的数据进行加工
df.show()
//二维表结构
df.printSchema()
df.select("name").show()
//导入sparksession中的隐式转换操作,增强sql的功能
import sparksql.implicits._
//列的运算,给每个人的年龄+10 select name, age+10,height-1 from tbl
df.select($"name",new Column("age").+(10)).show()
//起别名 select name, age+10 as age,height-1 as height from tbl
df.select($"name", new Column("age").+(10).as("age")).show()
//做聚合统计 统计不同年龄的人数 select age, count(1) counts from tbl group by age
df.select($"age").groupBy($"age").count().show()
//条件查询 获取年龄超过18的用户 select * from tbl where age > 18
// pdf.select("name", "age", "height").where($"age".>(18)).show()
df.select("name", "age").where("age > 18").show()
//在spark2.0之后处于维护状态,使用createOrReplaceTempView
/*
从使用范围上说,分为global和非global
global是当前SparkApplication中可用,非global只在当前SparkSession中可用
从创建的角度上说,分为createOrReplace和不Replace
createOrReplace会覆盖之前的数据
create不Replace,如果视图存在,会报错
*/
//编写SQL
df.createOrReplaceTempView("people")
val df2 = sparksql.sql(
"""
|select
|*
|from people
|where age > 20
|""".stripMargin)
sparksql.sql(
"""
|select
|age,
|count(age) cnt
|from people
|group by age
|""".stripMargin).show()
//4、对结果数据进行持久化
df2.show()
//5、关闭sparkSession对象
sparksql.stop()
}
}
为了方便查看结果,只报error的INFO,将log4j.properties放置到resources文件下。
2.6 SparkSQL的DataFrame和DataSet创建
2.6.1 DataFrame的构建方式
构建方式有两,一种通过Javabean+反射的方式来进行构建;还有一种的话通过动态编码的方式来构建。
- JavaBean+反射
package com.sparkSQL_example
import org.apache.spark.sql.{DataFrame, SparkSession}
// 构建反射方式的样例类
case class student(id:Int,name:String,gender:Int,age:Int)
object javaBeanCreateDF {
def main(args: Array[String]): Unit = {
// 创建执行入口
val sparksql = SparkSession.builder()
.appName("createDF")
.master("local[*]")
.getOrCreate()
// 创建集合数据,并将数据封装到样例类中
val list = List(
student(1,"王凯",0,23),
student(2,"赵凯",0,32),
student(3,"姜华劲",1,24)
)
// 导入隐式转换
import sparksql.implicits._
// 创建DF,创建DF的同时可以进行字段名重命名
val df: DataFrame = list.toDF("ids","names","genders","ages")
// 打印输出
df.printSchema()
df.show()
// 关闭
sparksql.stop()
}
}
- 动态编程
package com.sparkSQL_example
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object sparkCreateDF {
def main(args: Array[String]): Unit = {
val sparksql = SparkSession.builder()
.master("local[*]")
.appName("SparkSQLDataFrame")
.getOrCreate()
/*
使用动态编程的方式构建DataFrame
Row-->行,就代表了二维表中的一行记录,jdbc中的resultset,就是java中的一个对象
*/
val row:RDD[Row] = sparksql.sparkContext.parallelize(List(
Row(1, "李伟", 1, 180.0),
Row(2, "汪松伟", 2, 179.0),
Row(3, "常洪浩", 1, 183.0),
Row(4, "麻宁娜", 0, 168.0)
))
//表对应的元数据信息
val schema = StructType(List(
StructField("id", DataTypes.IntegerType, false),
StructField("name", DataTypes.StringType, false),
StructField("gender", DataTypes.IntegerType, false),
StructField("height", DataTypes.DoubleType, false)
))
//创建DataFrame
val df = sparksql.createDataFrame(row, schema)
df.printSchema()
df.show()
//关闭sparksql
sparksql.stop()
}
}
说明:这里学习三个新的类:
Row:代表的是二维表中的一行记录,或者就是一个Java对象
StructType:是该二维表的元数据信息,是StructField的集合
StructField:是该二维表中某一个字段/列的元数据信息(主要包括,列名,类型,是否可以为null)
总结:
这两种方式,都是非常常用,但是动态编程更加的灵活,因为javabean的方式的话,提前要确定好数据格式类型,后期无法做改动。
2.6.2 Dataset的构建方式
Dataset是DataFrame的升级版,创建方式和DataFrame类似,但有不同。
package com.sparkSQL_example
import org.apache.spark.sql.{DataFrame, SparkSession}
object javaBeanCreateDataset {
def main(args: Array[String]): Unit = {
// 创建执行入口
val sparksql = SparkSession.builder()
.appName("createDF")
.master("local[*]")
.getOrCreate()
// 创建集合数据,并将数据封装到样例类中
val list = List(
student(1, "王凯", 0, 23),
student(2, "赵凯", 0, 32),
student(3, "姜华劲", 1, 24)
)
// 导入隐式转换
import sparksql.implicits._
// 创建DS
val ds = sparksql.createDataset(list)
// 打印输出
ds.printSchema()
ds.show()
// 关闭
sparksql.stop()
}
}
2.7 RDD、DF、DS的相互转换
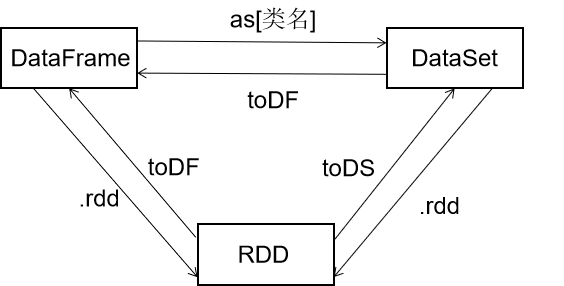
package com.sparkSQL_example
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Dataset, SparkSession}
// 构建反射方式的样例类
case class student1(id:Int,name:String,gender:Int,age:Int)
object RDD_DF_DS_Convert {
def main(args: Array[String]): Unit = {
// 创建执行入口
val sparksql = SparkSession.builder()
.appName("createDF")
.master("local[*]")
.getOrCreate()
//构建RDD
val stuRDD1 = sparksql.sparkContext.parallelize(List(
new student1(1,"Zhangsan",1,56),
new student1(2, "LiSi", 1, 49),
new student1(3, "WangWu", 1, 39),
new student1(4, "ZhaoLiu", 0, 29)
))
// //1.rdd_to_df
// beanRDD_to_DataFrame(sparksql,stuRDD1)
// //2.rdd_to_ds
// rdd_to_Dataset(sparksql,stuRDD1)
// //3.dataframe_to_DataSet
// dataFrame_to_DataSet(sparksql,stuRDD1)
// //4.dataSet_to_DataFrame
// dataSet_to_DataFrame(sparksql,stuRDD1)
//5.dataFrame和DataSet转rdd
DFAndDS_to_RDD(sparksql,stuRDD1)
//关闭spark
sparksql.stop()
}
/**
* Rdd_to_DF
*/
def beanRDD_to_DataFrame(spark:SparkSession,stuRDD:RDD[student1]): Unit = {
//如下指定类型反而不能推断,即不能正常转换
//val sdf =spark.createDataFrame(stuRDD, classOf[Student])
//通过rdd来创建ds实现转换
val sdf =spark.createDataFrame(stuRDD)
sdf.printSchema()
sdf.show()
//通过简单方式实现rdd.toDF
import spark.implicits._
val df1 = stuRDD.toDF()
df1.show()
df1.printSchema()
}
/**
* RDD_to_DataSet
*/
def rdd_to_Dataset(spark:SparkSession,stuRDD:RDD[student1]): Unit = {
//通过rdd创建ds方式实现转换
import spark.implicits._
val ds:Dataset[student1] = spark.createDataset(stuRDD)
ds.show()
ds.printSchema()
//通过简单的rdd.toDS
val ds1 = stuRDD.toDS()
ds1.show()
ds1.printSchema()
}
/**
* dataFrame_to_DataSet
*/
def dataFrame_to_DataSet(spark:SparkSession,stuRDD:RDD[student1]): Unit ={
import spark.implicits._
val df = stuRDD.toDF()
//Dataframe转换成DS
val ds = df.as("stu")
ds.show()
ds.printSchema()
}
/**
* dataSet_to_DataFrame
*/
def dataSet_to_DataFrame(spark:SparkSession,stuRDD:RDD[student1]): Unit ={
import spark.implicits._
val ds = stuRDD.toDS()
//DataSet转换成DF
val df = ds.toDF()
df.show()
df.printSchema()
}
/**
* dataframe和dataset转换rdd
*/
def DFAndDS_to_RDD(spark:SparkSession,stuRDD:RDD[student1]): Unit ={
import spark.implicits._
val df = stuRDD.toDF()
val ds = stuRDD.toDS()
val rddf = df.rdd
val rdds = ds.rdd
println(rddf.collect().toBuffer)
println(rdds.collect().toBuffer)
}
}
三、SparkSQL读写数据
3.1 数据的加载
Sparksql中加载外部的数据,使用统一的API入口
spark.read.format(数据文件格式).load(path)
这个方式有更加清晰的简写方式,比如要加载json格式的文件
spark.read.json(path)
默认加载的文件格式为parquet
package com.sparkSQL_example
import org.apache.spark.sql.SparkSession
import java.util.Properties
object sparkDataLoad {
def main(args: Array[String]): Unit = {
//1、获取sparkSQL的上下文
val sparksql = SparkSession
.builder()
.master("local[*]")
.appName("dataload")
.getOrCreate()
//format读取数据源
val df = sparksql.read.format("json").load("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\people.json")
df.show()
//比较清晰的方式加载
val df1 = sparksql.read.json("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\people.json")
df1.show()
val df2 = sparksql.read.csv("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\student.csv")
df2.show()
val df3 = sparksql.read.orc("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\student.orc")
df3.show()
val df4 = sparksql.read.textFile("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\topn.txt")
df4.show()
val df5 = sparksql.read.parquet("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\users.parquet")
df5.show()
//读取jdbc
//没有mysql依赖的话现在pom.xml文件里添加mysql的依赖
val url = "jdbc:mysql://user1:3306/test"
val table = "wc"
val prop = new Properties()
prop.put("user","root")
prop.put("password","root")
val df6 = sparksql.read.jdbc(url, table, prop)
df6.show()
//5、关闭sparkSession对象
sparksql.stop()
}
}
3.2 数据的落地
SparkSQL对数据的落地保存使用api为:spark.write.save(),需要指定数据的落地格式,因为和read的默认格式一样,save的默认格式也是parquet,需要在write和save之间指定具体的格式format(format)。
复杂格式数据写出:spark.write.format(格式).save(路径)
同样也有简写方式:spark.write.json/parquet()
package com.sparkSQL_example
import org.apache.spark.sql.{SaveMode, SparkSession}
import java.util.Properties
object sparkDataWrite {
def main(args: Array[String]): Unit = {
//1、获取sparkSQL的上下文
val spark = SparkSession
.builder()
.master("local[*]")
.appName("dataload")
.getOrCreate()
//format读取数据源
val df = spark.read.json("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\people.json")
df.show()
df.printSchema()
//数据写出
df.write.format("json").save("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\out\\7001")
df.write.save("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\out\\7002") //默认parquet格式snappy压缩
df.write.csv("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\out\\7003")
/*
数据的落地--->默认的存储格式为parquet,同时基于snappy压缩方式存储
落地的保存方式SaveMode
ErrorIfExists:目录存在保存,默认的格式
Append:在原有的基础之上追加
Ignore:忽略,如果目录存在则忽略,不存在则创建
Overwrite:覆盖(删除并重建)
*/
df.write.mode(SaveMode.Overwrite).csv("C:\\Users\\80621\\Desktop\\data\\sparksqlData\\out\\7003")
//写出到jdbc
val url = "jdbc:mysql://user1:3306/mydb"
val table = "mytb1"
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "root")
df.write.mode(SaveMode.Overwrite).jdbc(url, table, prop)
//5、关闭sparkSession对象
spark.stop()
}
}
四、Spark-SQL命令
-- 进入SparkSQL命令行
[root@node1 spark-3.1.2]# spark-sql
.....
spark-sql> show databases;
default
spark-sql> create database mydatabase;
spark-sql> show databases;
default
mydatabase
spark-sql> use mydatabase;
spark-sql> show tables;
-- 指定目录创建表
spark-sql> create table if not exists content(str string) location "/home/input";
spark-sql> select * from content;
hello flink flink flink flink flink
hi hi flink flink
Time taken: 0.88 seconds, Fetched 2 row(s)
spark-sql> select count(*) from content;
2
-- 指定列分隔符创建表
spark-sql> create table if not exists test(content String) row format delimited fields terminated by " " location "/home/input";
spark-sql> select * from test;
hello
hi
Time taken: 0.88 seconds, Fetched 2 row(s)
-- 练习使用SQL统计词频???
spark-sql> select explode(split(str," ")) words,1 as cnt from t2;
-- 联系统计签到人数,来了的、未来的、请假的人数
select
sum(tmp.iscome) comes,
sum(tmp.nocome) nocomes,
sum(tmp.qj) qjs
from (select case status when 1 then 1 else 0 end as iscome,case status when 0 then 1 else 0 end as nocome,case status when 2 then 1 else 0 end as qj from stu) as tmp;
五、SparkSQL函数操作
5.1 函数的定义
SQL中函数,其实说白了就是各大编程语言中的函数,或者方法,就是对某一特定功能的封装,通过它可以完成较为复杂的统计。这里的函数的学习,就基于Hive中的函数来学习。
5.2 函数的分类
功能分类
5.2.1 数值
1) round(x, [d]):对x保留d位小数,同时会四舍五入
spark-sql> select round(0.33,1);
2) floor(x):获取不大于x的最大整数.
spark-sql> select floor(-3.5);
3) ceil(x):获取不小于x的最小整数.
spark-sql> select ceil(-3.1);
4) rand():获取0到1之间的随机数,获取表中随机的两条记录
spark-sql> select * from test order by rand() limit 2;
or
spark-sql> select *, rand() rand from test order by rand limit 2;
5.2.2 数学
1) 取绝对值
spark-sql> select abs(-1);
2) 取幂次方
spark-sql> select pow(2,3);
3) 平方根
spark-sql> select sqrt(16);
5.2.3 条件
spark-sql> select if(1=2,100,200);
spark-sql> Select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
5.2.4 日期
1) UNIX时间戳转日期函数: from_unixtime
语法: from_unixtime(bigint unixtime[, string format])
返回值: string
说明: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间
举例:
spark-sql> select from_unixtime(1323308943,'yyyyMMdd');
2) 获取当前UNIX时间戳函数: unix_timestamp
语法: unix_timestamp()
返回值: bigint
说明: 获得当前时区的UNIX时间戳
举例:
spark-sql> select unix_timestamp();
3) 日期转UNIX时间戳函数: unix_timestamp
语法: unix_timestamp(string date)
返回值: bigint
说明: 转换格式为"yyyy-MM-dd HH:mm:ss"的日期到UNIX时间戳。如果转化失败,则返回0。
举例:
spark-sql> select unix_timestamp('2011-12-07 13:01:03');
4) 指定格式日期转UNIX时间戳函数: unix_timestamp
语法: unix_timestamp(string date, string pattern)
返回值: bigint
说明: 转换pattern格式的日期到UNIX时间戳。如果转化失败,则返回0。
举例:
spark-sql> select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
5) 日期时间转日期函数: to_date
语法: to_date(string timestamp)
返回值: string
说明: 返回日期时间字段中的日期部分。
举例:
spark-sql> select to_date('2011-12-08 10:03:01');
6)日期转年函数: year
语法: year(string date)
返回值: int
说明: 返回日期中的年。
举例:
spark-sql> select year('2011-12-08 10:03:01');
还有一些其他函数 日期转月/日/小时/分钟/秒函数: month,day,hour,minute,second等这里不再详述
7) 日期比较函数: datediff
语法: datediff(string enddate, string startdate)
返回值: int
说明: 返回结束日期减去开始日期的天数。
举例:
spark-sql> select datediff('2012-12-08','2012-05-09');
8) 日期增加函数: date_add 减少函数: date_sub
语法: date_add(string startdate, int days)
返回值: string
说明: 返回开始日期startdate增加days天后的日期。
举例:
spark-sql> select date_add('2012-12-08',10);
5.2.5 字符串
注意:数据库中的字符串索引从1开始,而不是0
1) length(str) 返回字符串str的长度
spark-sql> select length(123);
2) instr(str, substr),作用等同于str.indexOf(substr)
spark-sql> select instr("www.qfnb.com","b");
3) substr substring(str, pos[, len]):从str的pos位置开始,截取子字符串,截取len的长度,如果不传len,截取余下所有。
spark-sql> select substr("www.qfnb.com",5);
+----------------------------------------------------+
| substr(www.qfnb.com, 5, 2147483647) |
+----------------------------------------------------+
| qfnb.com |
+----------------------------------------------------+
4) concat(str1, str2)拼接字符串
spark-sql> select concat("www.qfnb.com",".",2);
+----------------------------------------------------------------+
| concat(www.qfnb.com, ., CAST(2 AS STRING)) |
+----------------------------------------------------------------+
| www.qfnb.com.2 |
+----------------------------------------------------------------+
5.2.6 特殊
- array:返回数组
- collect_set:返回一个元素不重复的set集合
- collect_list:返回一个元素可重复的list集合
- split(str, regex):使用regex分隔符将str进行切割,返回一个字符串数组
- explode(array):将一个数组,转化为多行
- cast(type1 as type2):将数据类型type1的数据转化为数据类型type2
eg:使用sql方式统计WordCount
select
tmp.word,
count(1) counts
from (
select
explode(split(line, "\\s+")) word
from test_wc
) tmp
group by tmp.word
order by counts desc, tmp.word;实现方式分类
- UDF(User Defined function)用户自定义函数
一路输入,一路输出,比如year,date_add, instr
- UDAF(User Defined aggregation function)用户自定义聚合函数
多路输入,一路输出,常见的聚合函数,count、sum、collect_list
- UDTF(User Defined table function)用户自定义表函数
一路输入,多路输出,explode
- 开窗函数
Row_Number() --->分组topN的求解
select
tmp.*
from (
select
name,
age,
married,
height,
row_number() over(partition by married order by height) rank
from teacher
) tmp
where tmp.rank < 35.3 自定义函数
概述
当系统提供的这些函数,满足不了咱们的需要的话,就只能进行自定义相关的函数,一般自定义的函数两种,UDF和UDAF。
UDF
一路输入,一路输出,完成就是基于scala函数。
通过模拟获取字符串长度的udf来学习自定义udf操作。
代码实现
object sparkSQLUDFOps {
def main(args: Array[String]): Unit = {
// 创建执行入口
val spark = SparkSession.builder()
.master("local[*]")
.appName("SparkSQLUDF")
.getOrCreate()
// 导入隐式转换及构建数据
import spark.implicits._
val rdd = spark.sparkContext.parallelize(List(
"songhaining",
"yukailu",
"liuxiangyuan",
"maningna"
))
//使用sparksession进行udf和udaf的注册
// spark.udf.register[Int, String]("myLen", (str:String) => myStrLength(str))
// spark.udf.register[Int, String]("myLen", str => myStrLength(str))
spark.udf.register[Int, String]("myLen", myStrLength)
// 创建表
val df = rdd.toDF("name")
df.createOrReplaceTempView("test")
//求取每个字符串的长度
val sql =
"""
|select
| name,
| length(name) nameLen,
| myLen(name) myNameLen
|from test
""".stripMargin
spark.sql(sql).show()
spark.stop()
}
//自定义udf
def myStrLength(str:String):Int = str.length
}六、SparkSQL操作MongoDB
添加MongoDB的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- 加入MongoDB的驱动 -->
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>casbah-core_2.12</artifactId>
<version>3.1.1</version>
</dependency>
<!-- 加入Spark读写MongoDB的驱动 -->
<dependency>
<groupId>org.mongodb.spark</groupId>
<artifactId>mongo-spark-connector_2.12</artifactId>
<version>2.4.3</version>
</dependency>通过SparkSQL读写MongoDB
对象MongoClient提供了连接到MongoDB服务器和访问数据库的功能
1)无验证连接
MongoClient 的构造函数可接受多种不同形式的参数
- MongoClient() : 创建一个客户端实例 , 并连接到本地主机的默认端口
- MongoClient(String host , int port) : 创建一个客户端实例,并连接到指定主机的指定端口
- MongoClient(MongoClientURI uri) : 创建一个客户端实例,并连接到连接uri指定的服务器
如:
MongoClient mongoClient = new MongoClient("127.0.0.1",27017);
MongoClientURI("mongodb://127.0.0.1:27017"));
2)验证连接
MongoClient mongoClient = new MongoClient(new MongoClientURI("mongodb://用户名:密码@127.0.0.1:27017/?authSource=数据库名&ssl=false"));
MongoClient实例提供的方法
方法 描述 close() 关闭连接 getDB(dbName) 返回一个与指定数据库相关联的DB对象,DB对象可再使用getCollection()方法得到表 dropDatabase(dbName) 删除指定数据库 getDatabaseNames() 返回数据库名称列表
package com.sparkSQL_example
import com.mongodb.casbah.Imports.{MongoClient, MongoClientURI, MongoDBObject}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* spark读写MongoDB
*/
//封装数据
case class Stu1(classID:String,name:String,age:Int,gender:String,category:String,score:Double)
case class MongoDBConfig(url:String,db:String)
object sparkSQL_MongoDB {
val config = Map("url"->"mongodb://user1:27017/mydb","db"->"mydb") //端口号和MongoDB中的哪个数据库
val COL = "stu"
val stuPath = "C:\\Users\\80621\\Desktop\\data\\sparksqlData\\input\\stu.txt"
def main(args: Array[String]): Unit = {
//获取spark的上下文
val conf = new SparkConf().setAppName("rdd").setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//读取stu.txt数据
val stuDF = spark.sparkContext.textFile(stuPath)
.filter(_.length > 0)
.map(x => {
val fields = x.split(" ")
//提取字段
Stu1(fields(0).trim, fields(1).trim, fields(2).trim.toInt, fields(3).trim, fields(4).trim, fields(5).trim.toDouble)
}).toDF() //.toDF() 必须要加隐式
//打印DF
stuDF.show()
//构建mongo客户端所需参数
val client = MongoDBConfig(config.getOrElse("url",""),config.getOrElse("db",""))
//存储到mongoDB
saveDFtoMongoDB(stuDF,client)
//从mongodb读取数据
writeFromMongoDB(spark,client)
//关闭spark
spark.stop()
}
//将数据保存MongoDB中
def saveDFtoMongoDB(df:DataFrame,client:MongoDBConfig): Unit ={
//获取mongoDB的Client
val mongoClient = MongoClient(MongoClientURI(client.url))
//获取集合
val stuCollection = mongoClient(client.db)(COL)
//线删除stu集合
stuCollection.dropCollection()
//插入数据
df
.write
.option("uri",client.url)
.option("collection",COL) //要写入的表名
.mode(SaveMode.Overwrite)
.format("com.mongodb.spark.sql")
.save()
//创建索引
stuCollection.createIndex(MongoDBObject("name" -> 1))
}
//将数据读取出来
def writeFromMongoDB(spark:SparkSession,client:MongoDBConfig): Unit ={
//读取数据
spark
.read
.option("uri",client.url)
.option("collection",COL) //要读取的是那张表
.format("com.mongodb.spark.sql")
.load()
.show()
}
}
















 6220
6220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









