







声明:该Java常用类分析基于JDK1.8
Object类
概述
官方介绍:
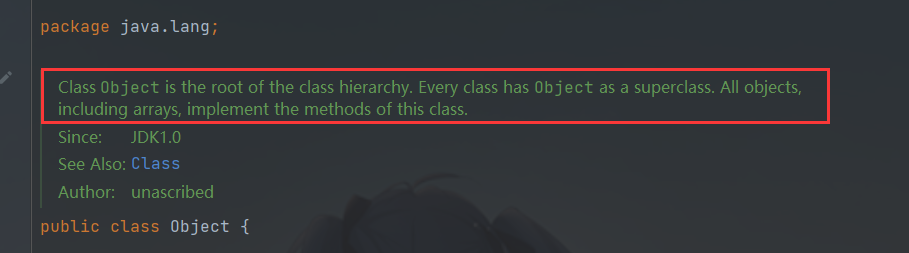
翻译内容:
Object类是类层次结构的根。每个类都有Object作为父类。所有对象,包括数组,都实现这个类的方法。
其中class hierarchy这个词组翻译为类的继承关系会比较容易理解
网上 + 个人理解:
- Object类是
java.lang包下的核心类,Object类是所有类的父类,所有对象(包括数组)都实现这个类的方法; - 何一个类时候如果没有明确的继承一个父类的话,那么它就是Object的子类;
- 可以使用类型为Object的变量指向任意类型的对象。
- Object类的变量只能用作各种值的通用持有者。要对他们进行任何专门的操作,都需要知道它们的原始类型并进行类型转换。
例如:
Object obj = new Test();
Test x = (Test)obj;
方法摘要
Object()
Object类有一个默认构造方法pubilc Object(),在构造子类实例时,都会先调用这个默认构造方法。
getClass()

public final native Class<?> getClass();
翻译
返回此对象的运行时类。返回的类对象是被代表的类的静态同步方法(static synchronized methods)锁定的对象。
实际的结果类型是Class<? extends |X|> ,其中|X|是擦除调用getClass的表达式的静态类型。
总结
注意这里的运行时类,这决定了这个方法获取类的方式有所不同,如下:
我们来看下面这一段代码
/**
* @author 小关同学
* @create 2021/8/9
*/
class User{
}
class Student extends User{
}
public class ObjectTest {
public static void main(String[] args) {
User user1 = new User();
Class<User> userClass1 = User.class;
Class<User> userClass2 = user1.getClass();//报错,需要类型转换
}
}
Class< User > userClass = user1.getClass();这里报错,需要我们类型转换,是不是感觉有点奇怪?
同样是获取当前类,为什么getClass方法需要类型转换,而.class却不需要?
原因:User.class可以在编译时就确定下来Class的泛型,而user1.getClass()实际上是运行时才能确定下来实际是什么泛型。
如下图:
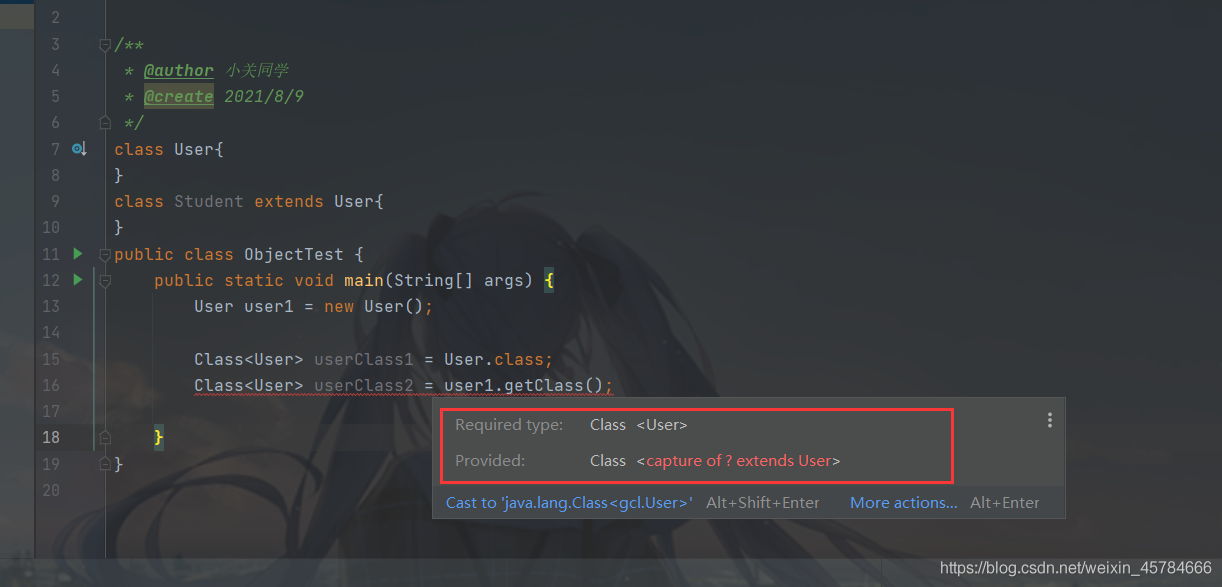
编译器提示未识别泛型的类型。
我们往上再去看一下getClass()方法的源码,
返回此对象的运行时类,Object.getClass()方法返回的Class泛型是运行时才能确定的,所以返回的类型是Class<?>,所以得我们手动进行类型转换。
hashCode()

public native int hashCode();
翻译
返回对象的哈希码值。支持此方法是为了方便使用诸如java.util.HashMap所提供的散列表。
hashCode的一般约定是:
- 在Java应用程序的执行过程中,每当对同一个对象多次调用hashCode方法时,只要在对象上的equals比较中使用的信息没有被修改,hashCode方法就必须始终返回相同的整数。在同一个应用程序的多次执行过程中,每次执行所返回的整数可以不一致。
- 如果根据equals(Object)方法两个对象是相等的,那么调用hashCode方法每一个对象必须产生相同的整数结果。
- 根据equals(Object)方法,如果两个对象不相等,则对这两个对象中的每一个调用hashCode方法都必须产生不同的整数结果,这不是必需的。但是,程序员应该知道,为不相等的对象生成不同的整数结果可能会提高哈希表的性能。
总结
- hashCode 方法返回散列值。
- 返回值默认是由对象的地址转换而来的。
- 同一个对象调用 hashCode 的返回值是相等的。
- 两个对象的 equals 相等,那 hashCode 一定相等。
- 两个对象的 equals 不相等,那 hashCode 也不一定相等。
equals()
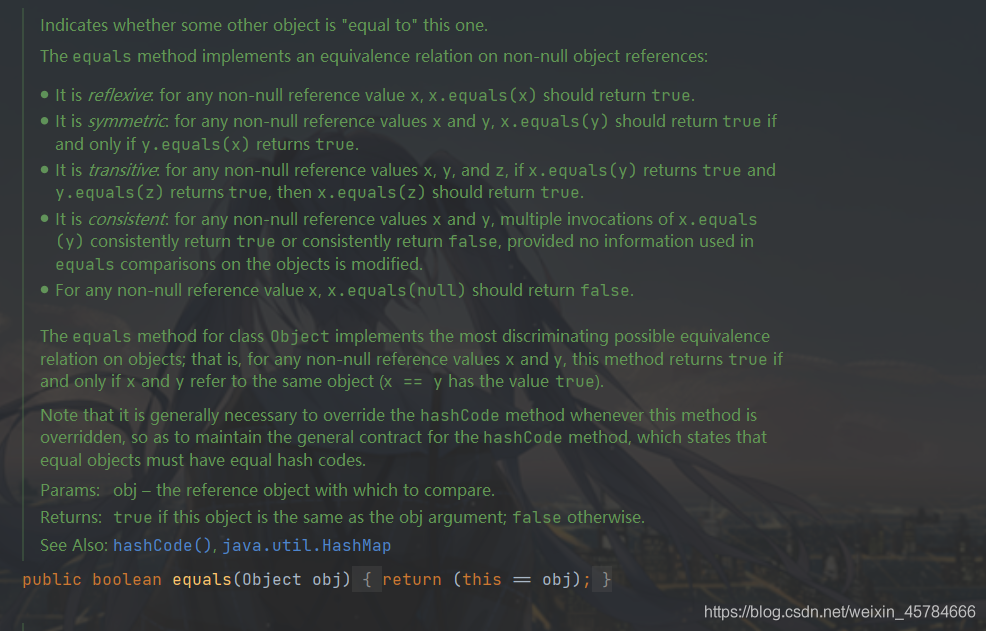
public boolean equals(Object obj) {
return (this == obj);
}
翻译
指示其他对象是否与此对象“相等”。
equals方法在非null对象引用上实现等价关系:
- 自反性:对于任何非空引用值 x,x.equals(x) 都应返回 true。
- 对称性:对于任何非空引用值 x 和 y,当且仅当 y.equals(x) 返回 true 时,x.equals(y) 才应返回 true。
- 传递性:对于任何非空引用值 x、y 和 z,如果 x.equals(y) 返回 true,并且 y.equals(z) 返回 true,那么 x.equals(z) 应返回 true。
- 一致性:对于任何非空引用值 x 和 y,多次调用 x.equals(y) 始终返回 true 或始终返回 false,前提是对象上 equals 比较中所用的信息没有被修改。
- 对于任何非空引用值 x,x.equals(null) 都应返回 false。
类对象的equals方法实现了对象上最有区别的等价关系;也就是说,对于任何非空引用值x和y,当且仅当x和y引用同一对象(x==y的值为true)时,此方法才返回true。
请注意,每当重写hashCode方法时,通常都需要重写该方法,以便维护hashCode方法的一般约定,即相等的对象必须具有相等的哈希代码。
总结
在 Java 中 “==” 是判断两个对象是否同一,而不是判断相等。因此Object类中的equals方法也是判断两个对象是否同一。要判断两个对象是否相等,就需要重写equals()方法。
clone()
这里比较长,就直接放代码块里面了
/**
* Creates and returns a copy of this object. The precise meaning
* of "copy" may depend on the class of the object. The general
* intent is that, for any object {@code x}, the expression:
* <blockquote>
* <pre>
* x.clone() != x</pre></blockquote>
* will be true, and that the expression:
* <blockquote>
* <pre>
* x.clone().getClass() == x.getClass()</pre></blockquote>
* will be {@code true}, but these are not absolute requirements.
* While it is typically the case that:
* <blockquote>
* <pre>
* x.clone().equals(x)</pre></blockquote>
* will be {@code true}, this is not an absolute requirement.
* <p>
* By convention, the returned object should be obtained by calling
* {@code super.clone}. If a class and all of its superclasses (except
* {@code Object}) obey this convention, it will be the case that
* {@code x.clone().getClass() == x.getClass()}.
* <p>
* By convention, the object returned by this method should be independent
* of this object (which is being cloned). To achieve this independence,
* it may be necessary to modify one or more fields of the object returned
* by {@code super.clone} before returning it. Typically, this means
* copying any mutable objects that comprise the internal "deep structure"
* of the object being cloned and replacing the references to these
* objects with references to the copies. If a class contains only
* primitive fields or references to immutable objects, then it is usually
* the case that no fields in the object returned by {@code super.clone}
* need to be modified.
* <p>
* The method {@code clone} for class {@code Object} performs a
* specific cloning operation. First, if the class of this object does
* not implement the interface {@code Cloneable}, then a
* {@code CloneNotSupportedException} is thrown. Note that all arrays
* are considered to implement the interface {@code Cloneable} and that
* the return type of the {@code clone} method of an array type {@code T[]}
* is {@code T[]} where T is any reference or primitive type.
* Otherwise, this method creates a new instance of the class of this
* object and initializes all its fields with exactly the contents of
* the corresponding fields of this object, as if by assignment; the
* contents of the fields are not themselves cloned. Thus, this method
* performs a "shallow copy" of this object, not a "deep copy" operation.
* <p>
* The class {@code Object} does not itself implement the interface
* {@code Cloneable}, so calling the {@code clone} method on an object
* whose class is {@code Object} will result in throwing an
* exception at run time.
*
* @return a clone of this instance.
* @throws CloneNotSupportedException if the object's class does not
* support the {@code Cloneable} interface. Subclasses
* that override the {@code clone} method can also
* throw this exception to indicate that an instance cannot
* be cloned.
* @see java.lang.Cloneable
*/
protected native Object clone() throws CloneNotSupportedException;
翻译
创建并返回此对象的一个副本。“副本”的准确含义可能依赖于对象的类。一般来说,对于任何对象 x,如果表达式:
x.clone() != x
是正确的,则表达式:
x.clone().getClass() == x.getClass()
将为 true,但这些不是绝对条件。一般情况下是:
x.clone().equals(x)
将为 true,但这不是绝对条件。
按照惯例,返回的对象应该通过调用 super.clone 获得。如果一个类及其所有的父类(Object 除外)都遵守此约定,则 x.clone().getClass() == x.getClass()。
按照惯例,此方法返回的对象应该独立于该对象(正被克隆的对象)。要获得此独立性,在 super.clone 返回对象之前,有必要对该对象的一个或多个字段进行修改。这通常意味着要复制包含正在被克隆对象的内部“深层结构”的所有可变对象,并使用对副本的引用替换对这些对象的引用。如果一个类只包含基本字段或对不变对象的引用,那么通常不需要修改 super.clone 返回的对象中的字段。
Object 类的 clone 方法执行特定的克隆操作。首先,如果此对象的类不能实现接口 Cloneable,则会抛出 CloneNotSupportedException。
注意:所有的数组都被视为实现接口 Cloneable。否则,此方法会创建此对象的类的一个新实例,并像通过分配那样,严格使用此对象相应字段的内容初始化该对象的所有字段;这些字段的内容没有被自我克隆。所以,此方法执行的是该对象的“浅表复制”,而不“深层复制”操作。
Object 类本身不实现接口 Cloneable,所以在类为 Object 的对象上调用 clone 方法将会导致在运行时抛出异常。
总结
clone()方法的用法
- 在要使用clone()方法的类上实现Cloneable接口,否则会报CloneNotSupportedException异常
- 在要使用clone()方法的类上面重写clone()方法
浅层复制和深层复制
前面的翻译中讲到Object中默认的的clone方法执行的是浅层复制,而不是深层复制,我们来了解一下。
浅层复制
浅层复制是指我们复制出来的对象内部的引用类型变量和原来对象内部引用类型变量是同一引用(指向同一对象地址)。基本数据类型clone()方法直接进行复制,只有克隆对象内部具有引用数据类型时才考虑浅层复制和深层复制。
但是我们拷贝出来的对象和新对象不是同一对象。
简单来说,新(拷贝产生)、旧(元对象)对象不同,但是内部如果有引用类型的变量,新、旧对象引用的都是同一地址的对象。
如下图:
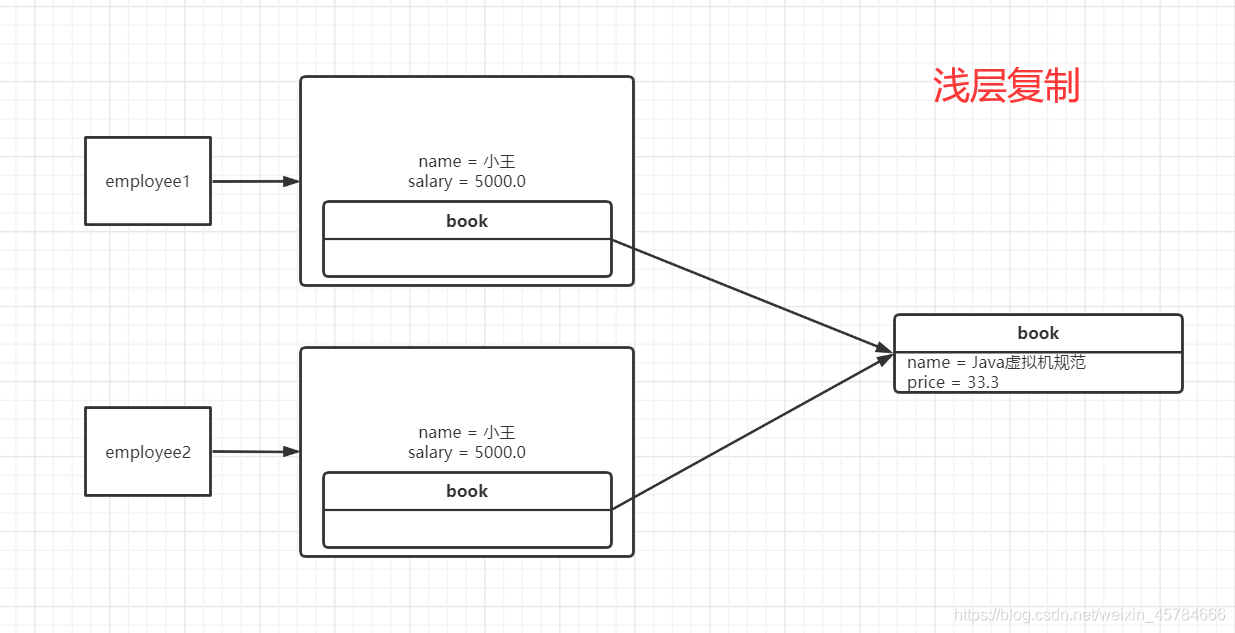
测试代码示例:
/**
* @author 小关同学
* @create 2021/8/10
*/
class Book{
private String name;
private double price;
public Book(String name,double price){
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
class Employee implements Cloneable {
private String name;
private double salary;
private Book book;
public Employee(String name,double salary,Book book){
this.name = name;
this.salary = salary;
this.book = book;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Book getBook() {
return book;
}
public void setBook(Book book) {
this.book = book;
}
@Override
public Object clone() throws CloneNotSupportedException {
Employee cloned = (Employee) super.clone();
return cloned;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", salary=" + salary +
", book=" + book +
'}';
}
}
public class CloneTest {
public static void main(String[] args){
Book book = new Book("Java虚拟机规范",33.3);
Employee employee1 = new Employee("小王",5000.0,book);
Employee employee2 = null;
try {
employee2 = (Employee) employee1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
System.out.println(employee1==employee2);
System.out.println("employee1="+employee1.toString());
System.out.println("employee2="+employee2.toString());
}
}
运行结果:
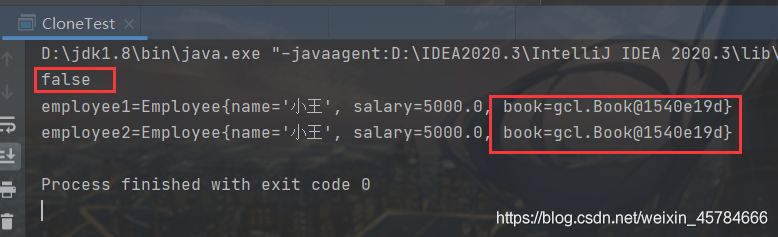
我们可以明显地看到,clone()方法复制属于浅层复制,复制过后的employee1和employee2使用的的是同一地址的book对象。
深层复制
深层复制:复制全部原对象的内容,包括内存的引用类型也进行复制
如下图:
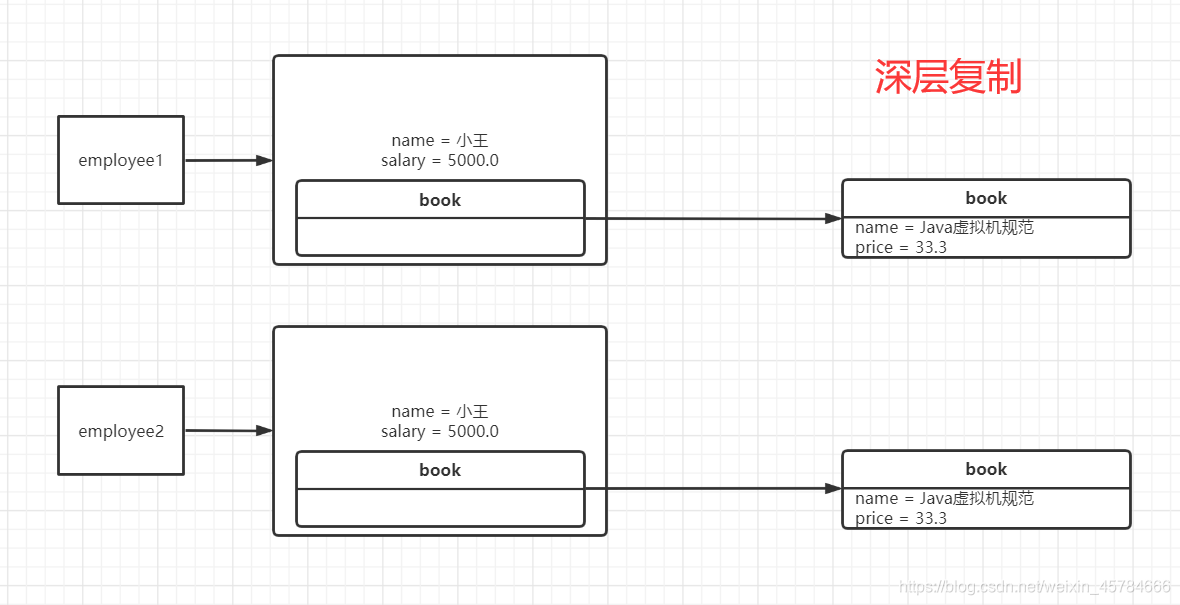
测试代码示例:
/**
* @author 小关同学
* @create 2021/8/10
*/
class Book implements Cloneable{
private String name;
private double price;
public Book(String name,double price){
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public Object clone() throws CloneNotSupportedException{
Book cloned = (Book) super.clone();
return cloned;
}
}
class Employee implements Cloneable {
private String name;
private double salary;
private Book book;
public Employee(String name,double salary,Book book){
this.name = name;
this.salary = salary;
this.book = book;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public Book getBook() {
return book;
}
public void setBook(Book book) {
this.book = book;
}
@Override
public Object clone() throws CloneNotSupportedException {
Employee cloned = (Employee) super.clone();
cloned.book = (Book) book.clone();//给Employee内部的Book对象也进行一次复制
return cloned;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", salary=" + salary +
", book=" + book +
'}';
}
}
public class CloneTest {
public static void main(String[] args){
Book book = new Book("Java虚拟机规范",33.3);
Employee employee1 = new Employee("小王",5000.0,book);
Employee employee2 = null;
try {
employee2 = (Employee) employee1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
System.out.println(employee1==employee2);
System.out.println("employee1="+employee1.toString());
System.out.println("employee2="+employee2.toString());
}
}
运行结果:
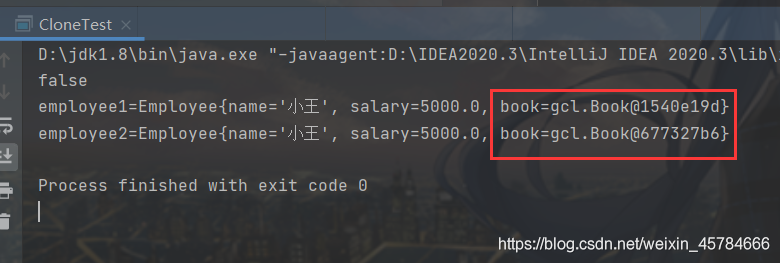
我们可以看到,这次Employee里面book对象的地址不一样了,由此我们可以知道深层复制比浅层复制要麻烦,深层复制中每个对象内部的对象都要进行深层复制。
String类型的clone问题的解释
有人看了上面的代码例子估计会问String类型也是引用数据类型,那么String类型到底算是浅层复制还是深层复制呢?
个人认为String类型的clone算浅层复制,因为String类在Java中是用final修饰的,本身就是一个不可变对象,复制出来的String类型变量也是继续去字符串常量池里面去找对象的引用,所以不算深层复制。
这篇博客总结得挺好的:string 在clone()中的特殊性
toString()
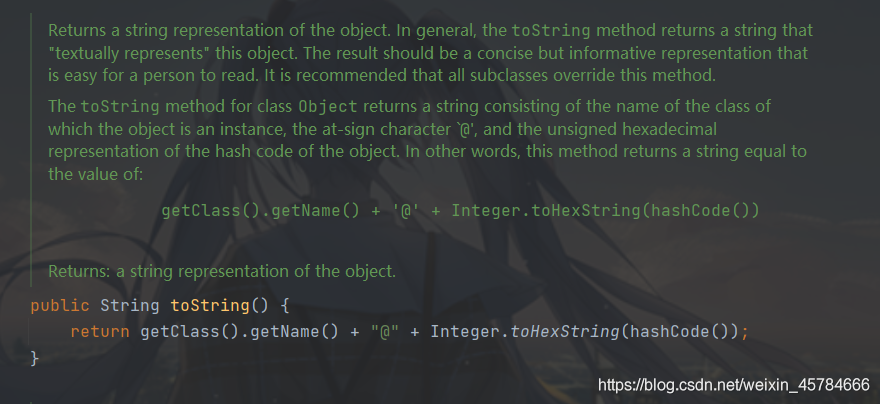
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
翻译
返回该对象的字符串表示。通常,toString 方法会返回一个“以文本方式表示”此对象的字符串。结果应该是一个简明但信息丰富的表示,便于阅读。建议所有子类都重写此方法。
Object 类的 toString 方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和此对象哈希码的无符号十六进制表示组成。换句话说,该方法返回一个字符串,它的值等于:
getClass().getName() + '@' + Integer.toHexString(hashCode())
总结
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
对源代码的解读:
getClass().getName()是返回对象的全限定类名(路径+类名)
Integer.toHexString(hashCode())返回传入的对象哈希值的十六进制的无符号字符串
测试
当Object子类不重写toString()方法时,输出结果为:
/**
* @author 小关同学
* @create 2021/8/11
*/
class Student{
private String name;
private String sex;
public Student(String name,String sex){
this.name = name;
this.sex = sex;
}
}
public class ToStringTest {
public static void main(String[] args) {
Student student = new Student("小王","男");
System.out.println(student.getClass().getName());
System.out.println(student.hashCode());
System.out.println(Integer.toHexString(student.hashCode()));
System.out.println(student.toString());
}
}
运行结果:
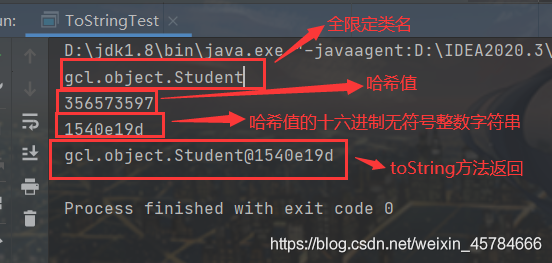
上面没重写的toString()方法打印出来的结果就是对象的引用
当Object子类重写toString()方法时,输出结果为:
/**
* @author 小关同学
* @create 2021/8/11
*/
class Student{
private String name;
private String sex;
public Student(String name,String sex){
this.name = name;
this.sex = sex;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", sex='" + sex + '\'' +
'}';
}
}
public class ToStringTest {
public static void main(String[] args) {
Student student = new Student("小王","男");
System.out.println(student.toString());
}
}
运行结果:
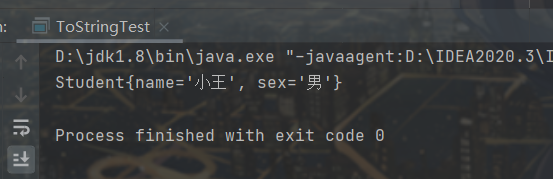
结果输出的是我们重写后的toString()方法的形式。
对象的控制线程状态方法
Object类里面存在三个控制线程状态的方法wait()、notify() 和 notifyAll(),它们都不属于Thread类,而是属于Object基础类,也就是每个对象都有wait(),notify(),notifyAll() 的功能,因为每个对象都有锁(monitor),即下面翻译时出现的对象监视器,锁是每个对象的基础,当然操作锁的方法也是最基础了。
这三个方法都必须在 synchronized 同步关键字所限定的作用域中调用,否则会报错java.lang.IllegalMonitorStateException ,意思是因为没有同步,所以线程对对象锁的状态是不确定的,不能调用这些方法。
notify()
public final native void notify();
翻译
唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。
直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权或劣势。
此方法只应由作为此对象监视器的所有者的线程来调用。通过以下三种方法之一,线程可以成为此对象监视器的所有者:
- 通过执行此对象的同步 (sychronized) 实例方法。
- 通过执行在此对象上进行同步的
synchronized语句的正文。 - 对于
Class类型的对象,可以通过执行该类的同步静态方法。
一次只能有一个线程拥有对象的监视器。
抛出:
IllegalMonitorStateException - 如果当前的线程不是此对象监视器的所有者。
总结
notify() 方法表示,当前的线程已经放弃对资源的占有,通知等待的线程来获得对资源的占有权,但是只有一个线程能够从wait状态中恢复,然后继续运行wait()后面的语句;只会唤醒等待该锁的其中一个线程。
测试代码示例:
/**
* @author 小关同学
* @create 2021/8/12
*/
//等待线程
class WaitThread implements Runnable{
Object lock;
public WaitThread(Object lock){
this.lock = lock;
}
public void run() {
String threadName = Thread.currentThread().getName();
//使用对象锁,锁住传入的lock这个对象
synchronized (lock){
System.out.println(threadName + "开始进入同步代码块区域");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "准备离开同步代码块区域");
}
}
}
//唤醒线程
class NotifyThread implements Runnable{
Object lock;
public NotifyThread(Object lock){
this.lock = lock;
}
public void run() {
String threadName = Thread.currentThread().getName();
//使用对象锁,锁住传入的lock这个对象
synchronized (lock){
System.out.println(threadName + "开始进入同步代码块区域");
lock.notify();
try {
System.out.println(threadName + "业务处理开始");
// 暂停 2s 表示业务处理
Thread.sleep(2000);
System.out.println(threadName + "业务处理结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "准备离开同步代码块区域");
//lock.notify();放在这一行唤醒,效果一样
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "退出同步代码块后续操作");
}
}
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Object lock = new Object();
Thread waitThread = new Thread(new WaitThread(lock), "waitThread");
Thread notifyThread = new Thread(new NotifyThread(lock), "notifyThread");
waitThread.start();
Thread.sleep(1000);
notifyThread.start();
}
}
运行结果:
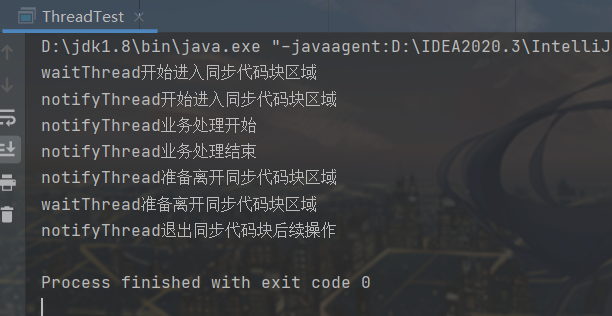
debug调试过程:
我们首先在两个线程的run方法和main方法处打了断点,将断点的形式设置为线程模式,如下图:
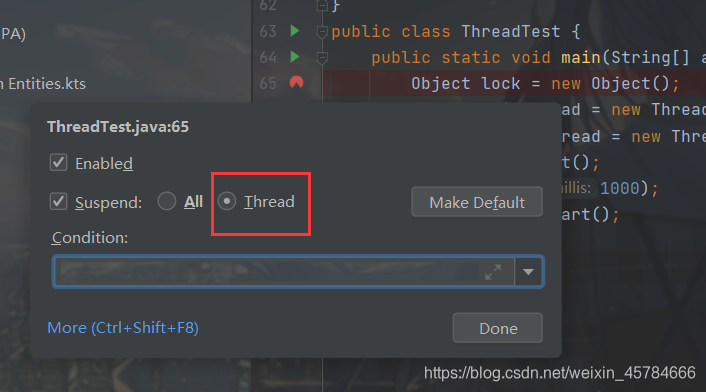
然后开始调试
选择进入waitThread线程的run方法
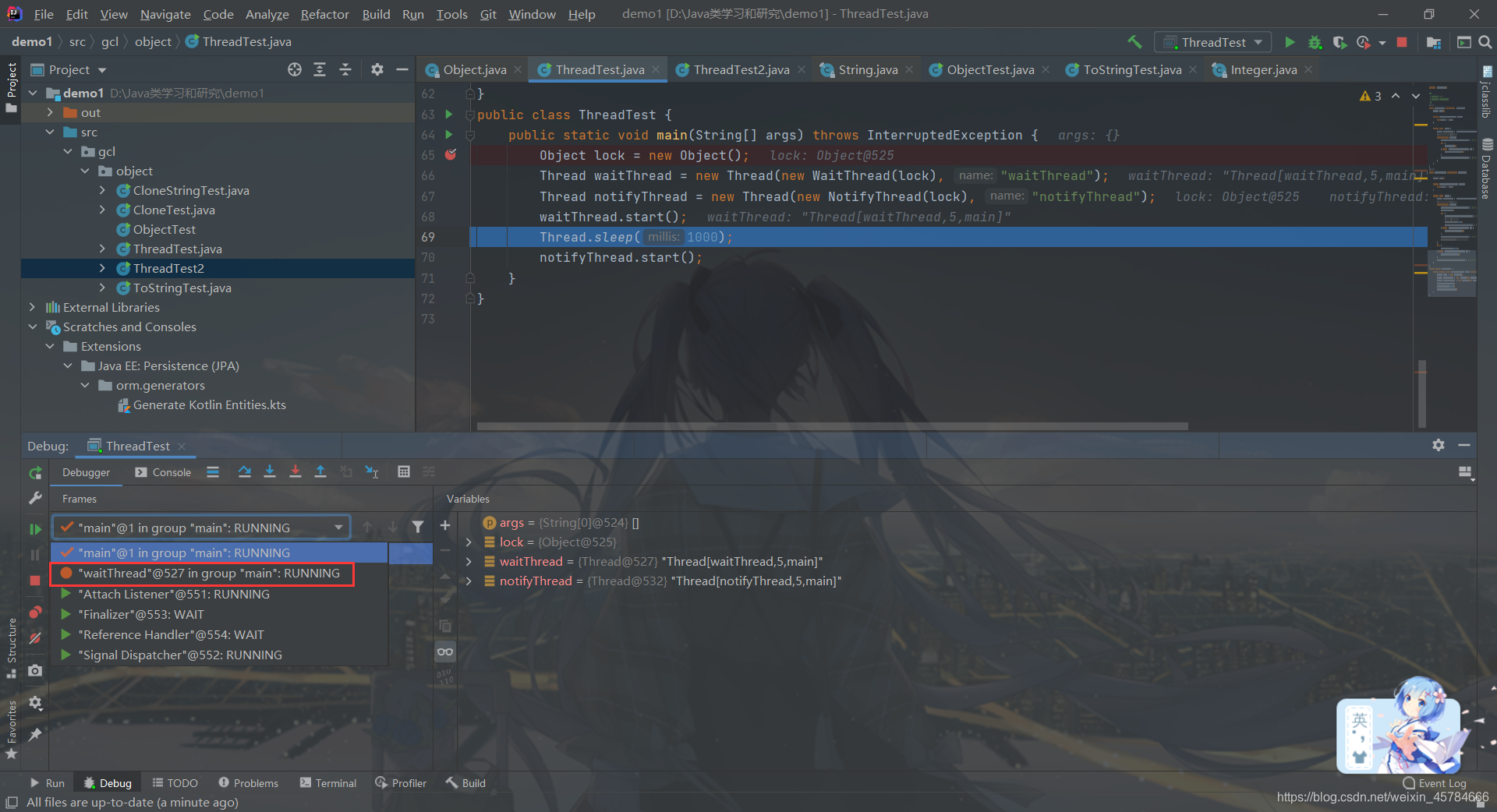
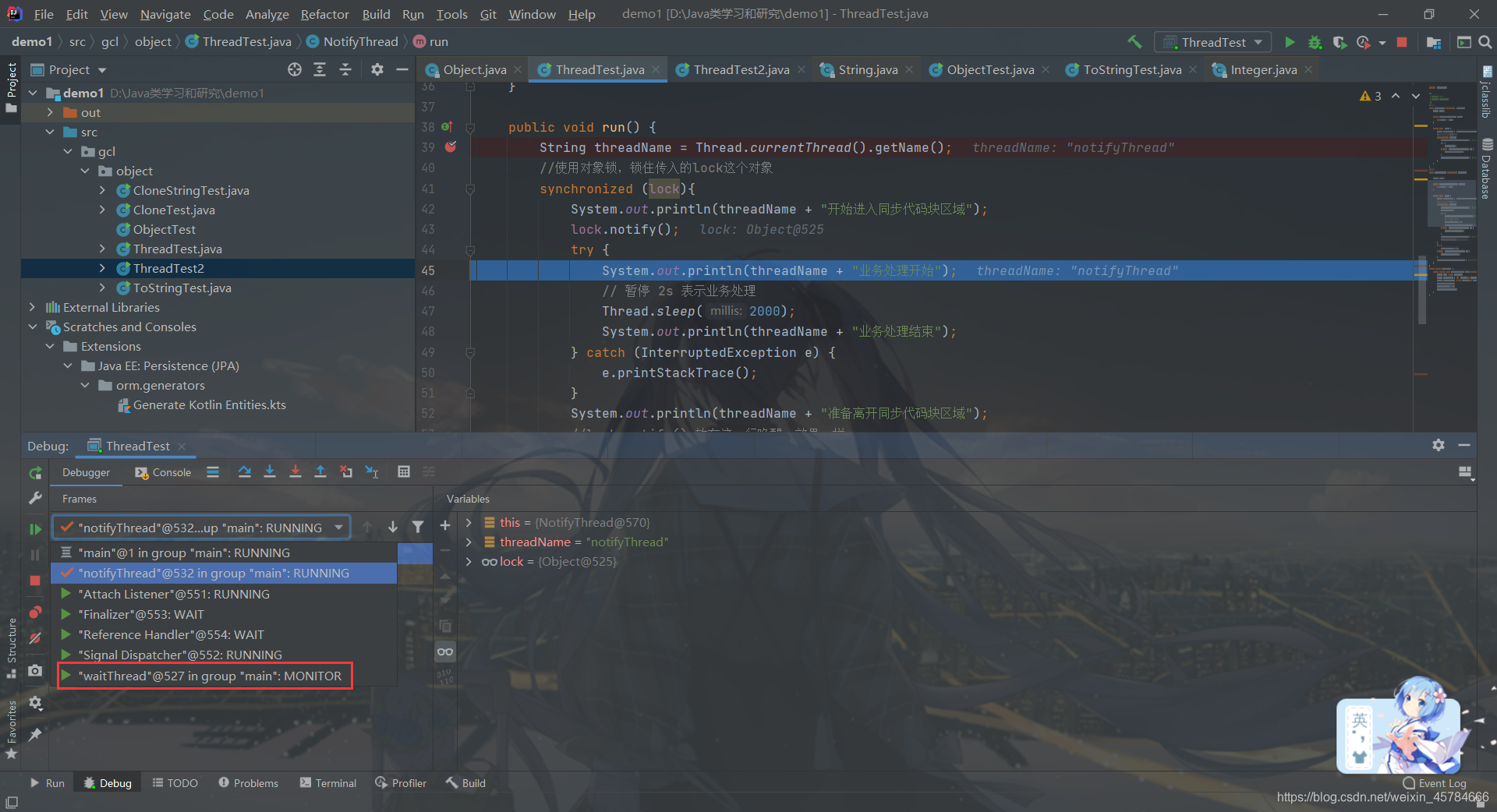
执行完lock.wait();语句之后我们可以发现waitThread线程的状态由Runining变成了Wait

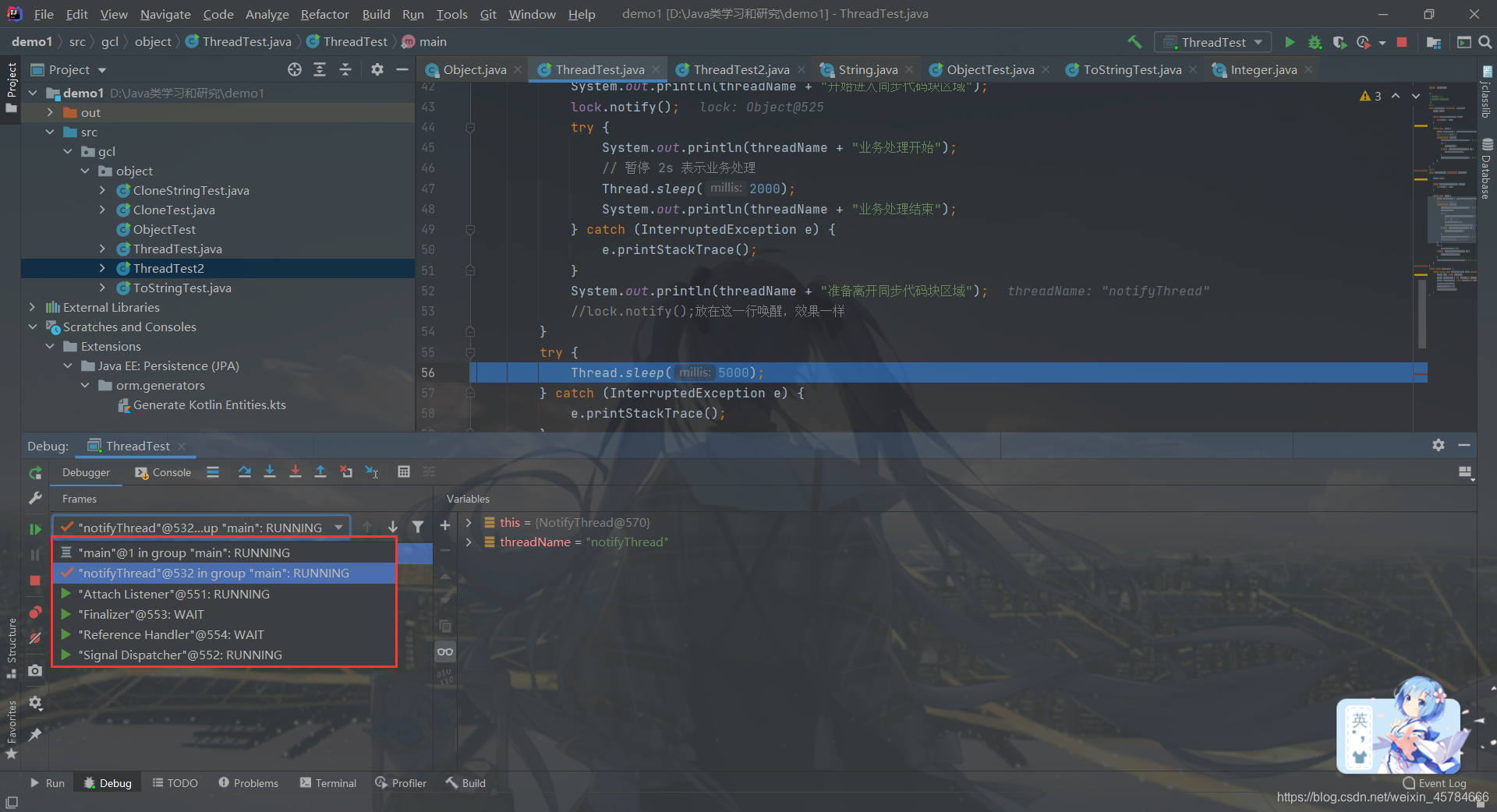
继续切回main线程,执行完notifyThread.start();这条语句启动notifyThread线程之后我们切换到notifyThread线程执行run方法
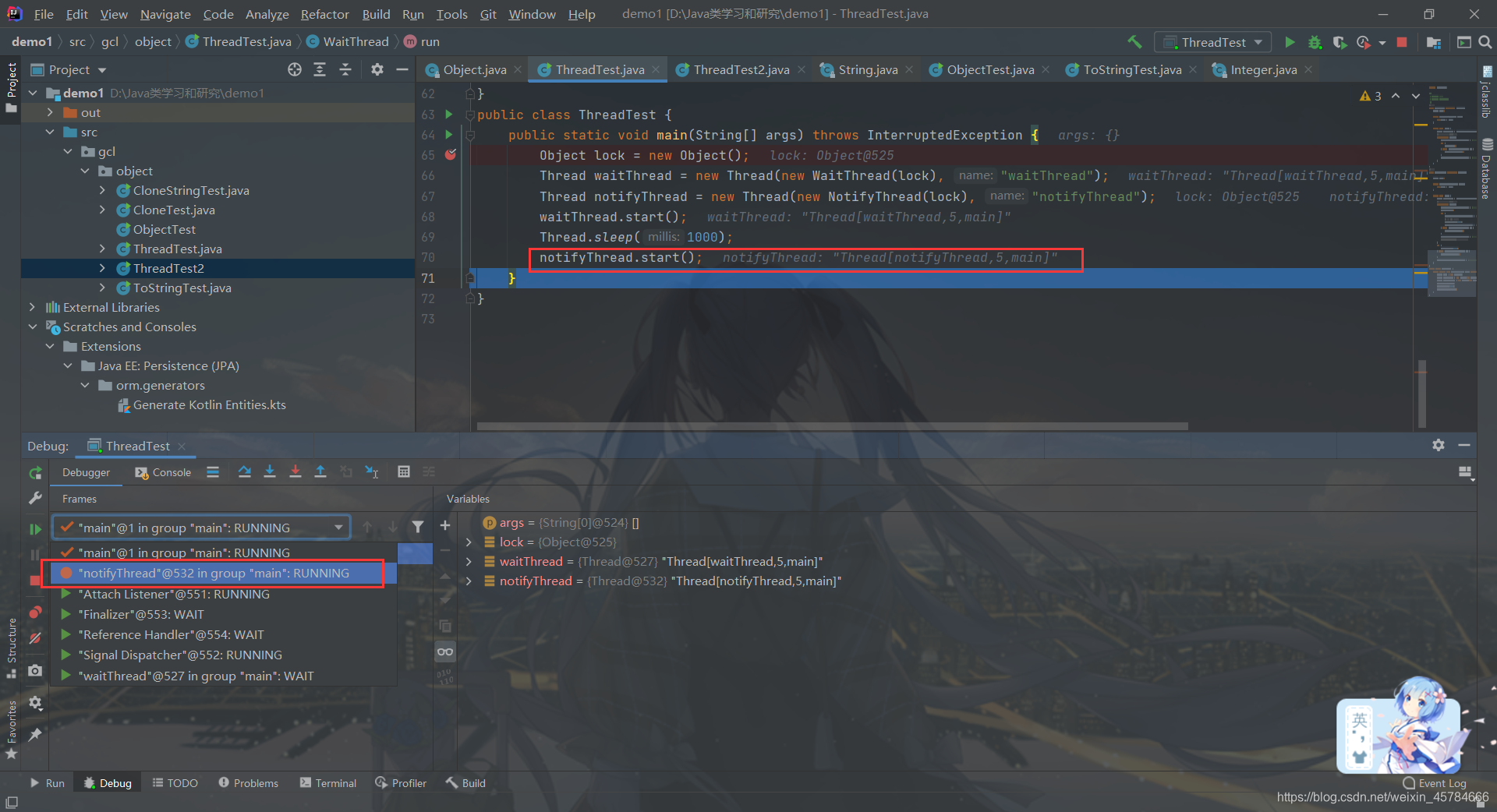
在执行lock.notify();语句之前,waitThread线程还处于Wait等待的状态
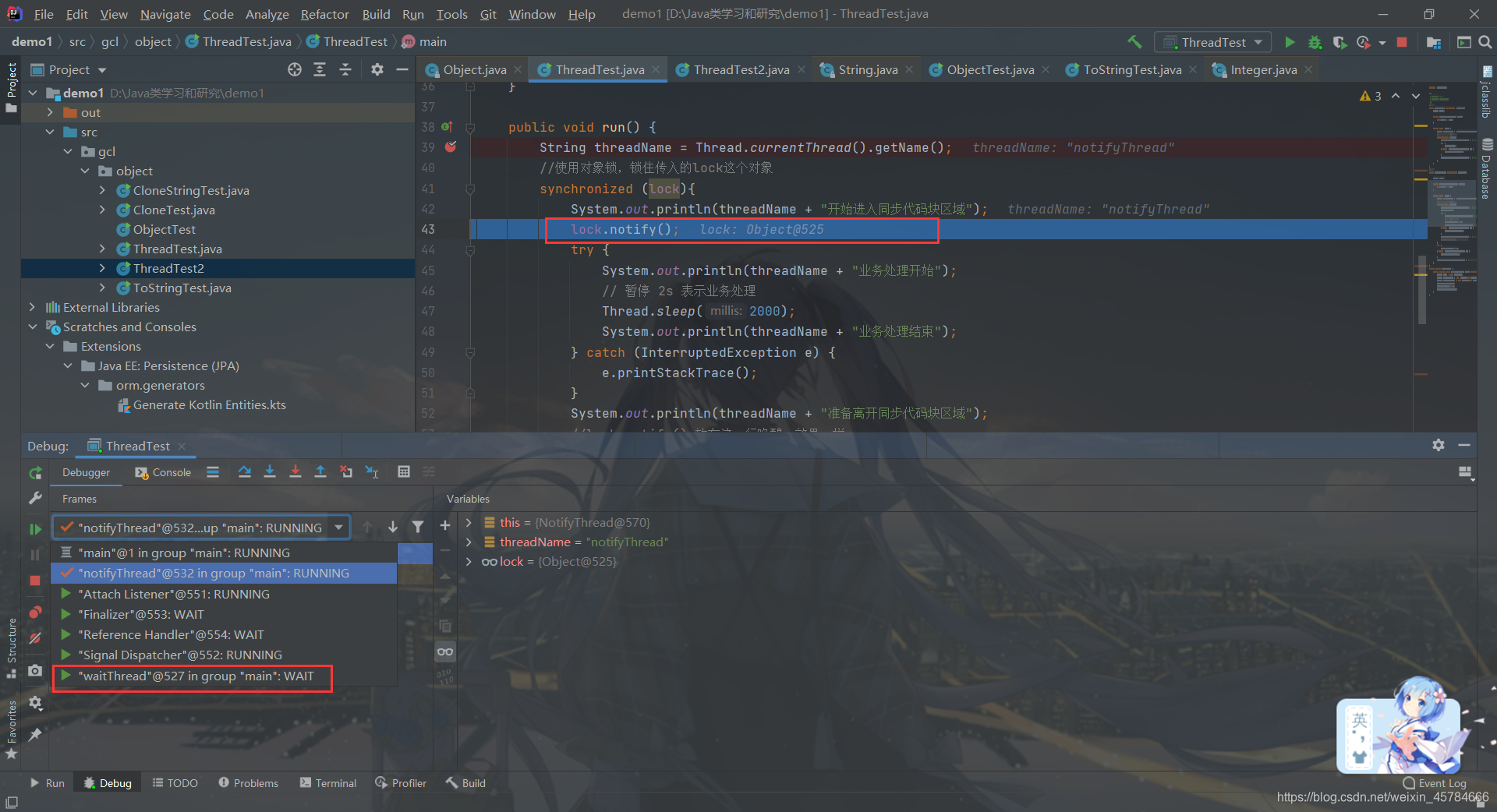
执行完lock.notify();语句之后,waitThread线程就不是Wait状态了,而是变成了Monitor,对应着线程中的BLOCKED(阻塞)状态,至于为什么会是阻塞状态呢?
这是因为此时notifyThread线程还在占用着lock对象锁,waitThread线程一时半会获取不到lock对象的资源,只能等待notifyThread线程退出同步代码块,把lock对象锁移交给waitThread线程。
所以一旦一个线程获取锁进入同步块,在其出来之前,如果其它线程想进入,就会因为获取不到锁而阻塞在同步块之外,这时的状态就是 BLOCKED。
一退出notifyThread的同步代码块之后,waitThread线程就执行完剩下的语句了,
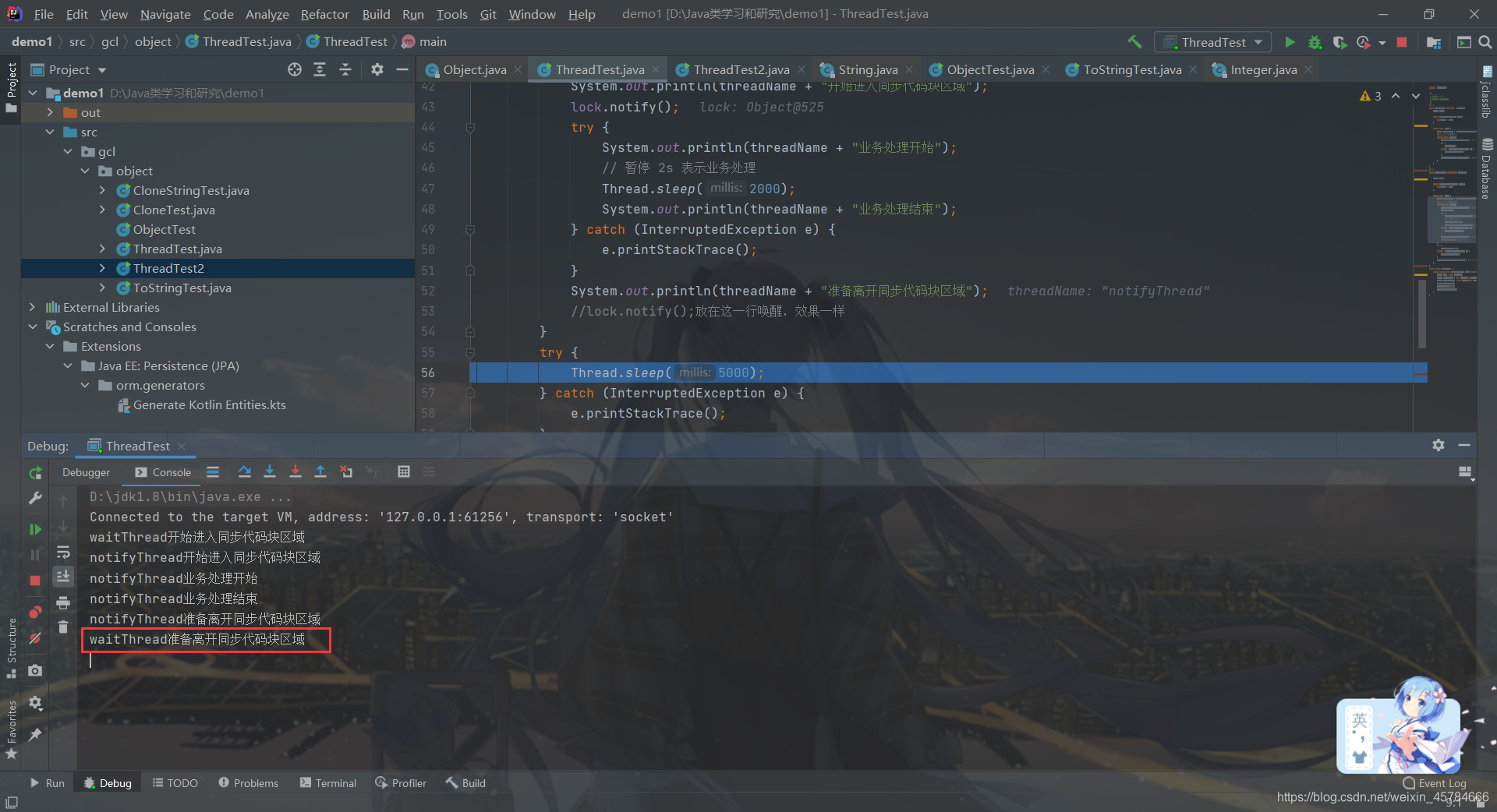
注意:调用当前线程 noitfy() 后,等待的获取对象锁的其他线程(可能有多个)不会立即从 wait() 处返回,而是需要调用 notify() 的当前线程释放锁(退出同步块)之后,等待线程才有机会从 wait() 返回。原因嘛,看上面debug的分析过程应该能够理解
notifyAll()
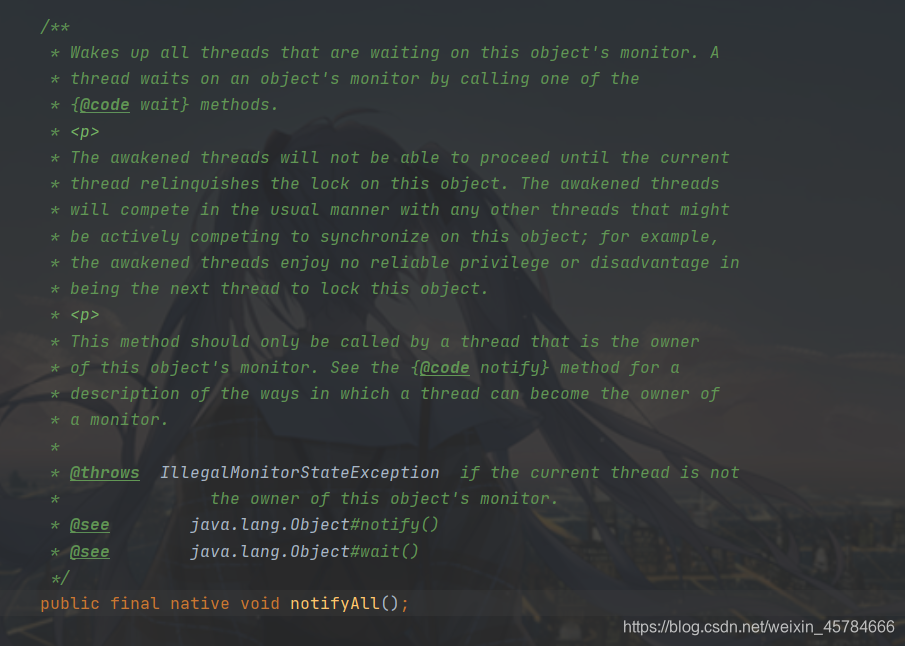
public final native void notifyAll();
翻译
唤醒在此对象监视器上等待的所有线程。线程通过调用其中一个 wait 方法,在对象的监视器上等待。
直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权或劣势。
此方法只应由作为此对象监视器的所有者的线程来调用。请参阅 notify 方法,了解线程能够成为监视器所有者的方法的描述。
抛出:
IllegalMonitorStateException - 如果当前的线程不是此对象监视器的所有者。
总结
notifyAll() 方法可以说是 notify() 方法的升级版,我们来看一下他们的对比,如下:
| 方法 | 作用 |
|---|---|
| notify | 当前的线程已经放弃对资源的占有, 通知任意一个等待线程从 wait() 方法后的语句开始运行;只会唤醒等待该锁的其中一个线程 |
| notifyAll | 当前的线程已经放弃对资源的占有,通知所有的等待线程从 wait() 方法后的语句开始运行; 唤醒等待该锁的所有线程 |
演示代码:
/**
* @author 小关同学
* @create 2021/8/12
*/
//等待线程
class WaitThread1 implements Runnable{
Object lock;
public WaitThread1(Object lock){
this.lock = lock;
}
public void run() {
String threadName = Thread.currentThread().getName();
//使用对象锁,锁住传入的lock这个对象
synchronized (lock){
System.out.println(threadName + "开始进入同步代码块区域");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "准备离开同步代码块区域");
}
}
}
class WaitThread2 implements Runnable{
Object lock;
public WaitThread2(Object lock){
this.lock = lock;
}
public void run() {
String threadName = Thread.currentThread().getName();
//使用对象锁,锁住传入的lock这个对象
synchronized (lock){
System.out.println(threadName + "开始进入同步代码块区域");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "准备离开同步代码块区域");
}
}
}
class WaitThread3 implements Runnable{
Object lock;
public WaitThread3(Object lock){
this.lock = lock;
}
public void run() {
String threadName = Thread.currentThread().getName();
//使用对象锁,锁住传入的lock这个对象
synchronized (lock){
System.out.println(threadName + "开始进入同步代码块区域");
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "准备离开同步代码块区域");
}
}
}
//唤醒线程
class NotifyThread implements Runnable{
Object lock;
public NotifyThread(Object lock){
this.lock = lock;
}
public void run() {
String threadName = Thread.currentThread().getName();
//使用对象锁,锁住传入的lock这个对象
synchronized (lock){
System.out.println(threadName + "开始进入同步代码块区域");
lock.notifyAll();
try {
System.out.println(threadName + "业务处理开始");
// 暂停 2s 表示业务处理
Thread.sleep(2000);
System.out.println(threadName + "业务处理结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "准备离开同步代码块区域");
}
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(threadName + "退出同步代码块后续操作");
}
}
public class ThreadTest {
public static void main(String[] args) throws InterruptedException {
Object lock = new Object();
Thread waitThread1 = new Thread(new WaitThread1(lock), "waitThread1");
Thread waitThread2 = new Thread(new WaitThread2(lock), "waitThread2");
Thread waitThread3 = new Thread(new WaitThread3(lock), "waitThread3");
Thread notifyThread = new Thread(new NotifyThread(lock), "notifyThread");
waitThread1.start();
waitThread2.start();
waitThread3.start();
Thread.sleep(1000);
notifyThread.start();
}
}
运行结果:
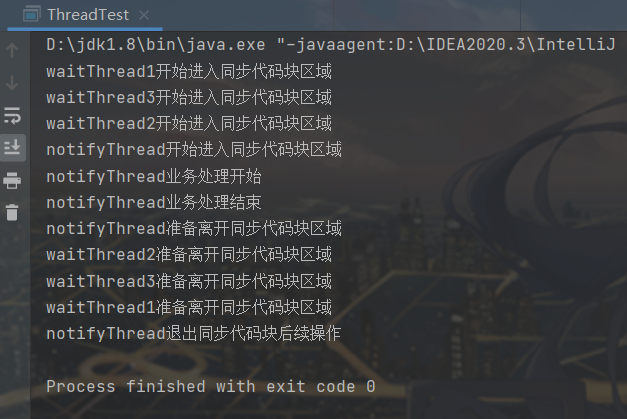
我们可以看到,原来处于等待阶段的三个waitThread线程在lock.notifyAll();语句执行后都退出了 wait 状态。
关于notifyAll()方法的唤醒顺序
notifyAll()方法唤醒线程的顺序是按照“后进先出”的顺序进行的,先进入 wait 状态的线程后唤醒,后进入 wait 状态的线程先唤醒。
测试代码仍然是我们上面的代码,我们来观察一下他们的不同执行结果,如下图:
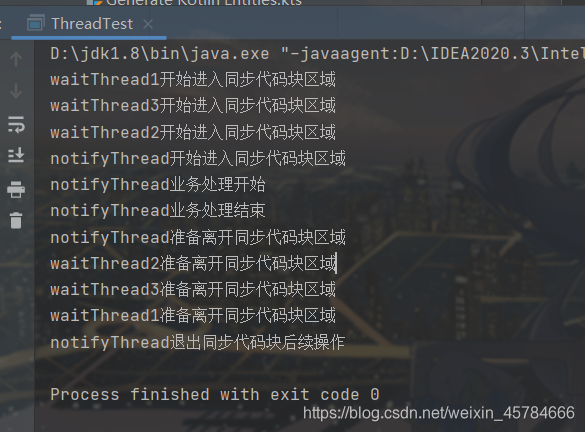
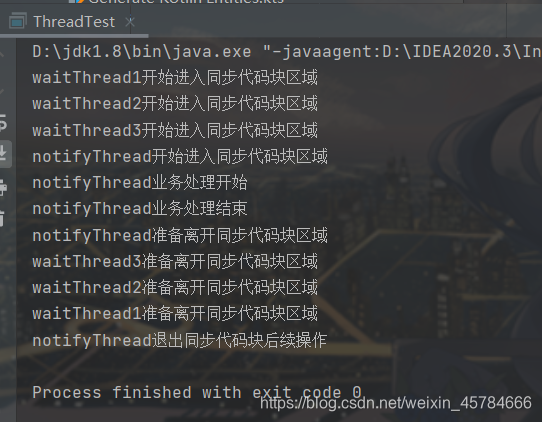
我们可以看到线程唤醒的顺序刚好和进入 wait 状态的顺序是相反的。
wait()
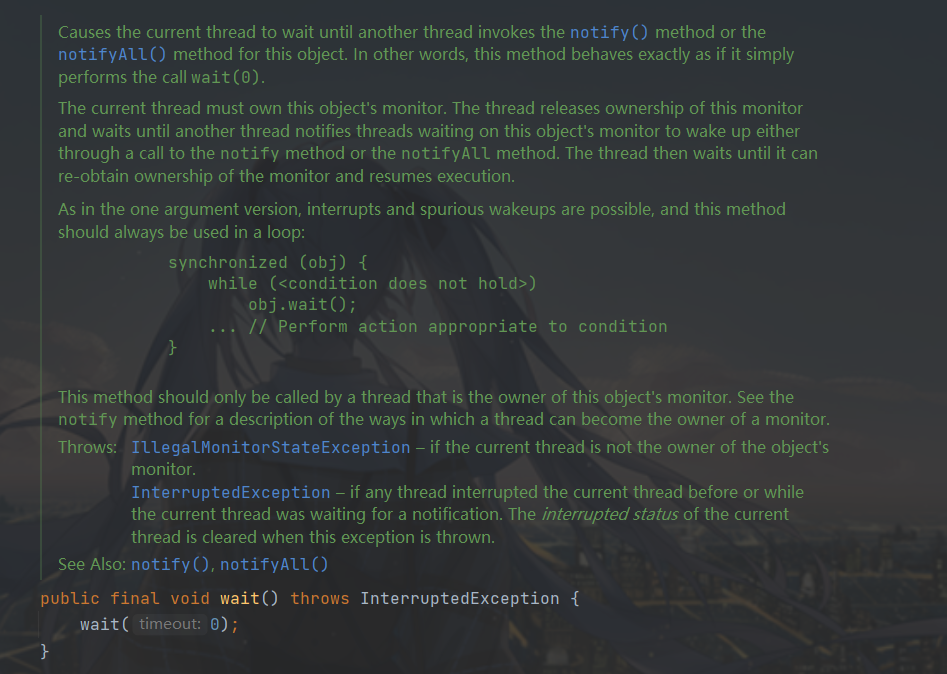
public final void wait() throws InterruptedException {
wait(0);
}
翻译
导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。换句话说,此方法的行为就好像它仅执行 wait(0) 调用一样。
当前的线程必须拥有此对象监视器。该线程发布对此监视器的所有权并等待,直到其他线程通过调用 notify 方法,或 notifyAll 方法通知在此对象的监视器上等待的线程醒来。然后该线程将等到重新获得对监视器的所有权后才能继续执行。
对于某一个参数的版本,实现中断和虚假唤醒是可能的,而且此方法应始终在循环中使用:
synchronized (obj) {
while (<condition does not hold>)
obj.wait();
... //执行适合条件的操作
}
此方法只应由作为此对象监视器的所有者的线程来调用。请参阅 notify 方法,了解线程能够成为监视器所有者的方法的描述。
抛出:
IllegalMonitorStateException - 如果当前的线程不是此对象监视器的所有者。
InterruptedException - 如果在当前线程等待通知之前或者正在等待通知时,另一个线程中断了当前线程。在抛出此异常时,当前线程的中断状态被清除。
wait(long timeout)
/**
* Causes the current thread to wait until either another thread invokes the
* {@link java.lang.Object#notify()} method or the
* {@link java.lang.Object#notifyAll()} method for this object, or a
* specified amount of time has elapsed.
* <p>
* The current thread must own this object's monitor.
* <p>
* This method causes the current thread (call it <var>T</var>) to
* place itself in the wait set for this object and then to relinquish
* any and all synchronization claims on this object. Thread <var>T</var>
* becomes disabled for thread scheduling purposes and lies dormant
* until one of four things happens:
* <ul>
* <li>Some other thread invokes the {@code notify} method for this
* object and thread <var>T</var> happens to be arbitrarily chosen as
* the thread to be awakened.
* <li>Some other thread invokes the {@code notifyAll} method for this
* object.
* <li>Some other thread {@linkplain Thread#interrupt() interrupts}
* thread <var>T</var>.
* <li>The specified amount of real time has elapsed, more or less. If
* {@code timeout} is zero, however, then real time is not taken into
* consideration and the thread simply waits until notified.
* </ul>
* The thread <var>T</var> is then removed from the wait set for this
* object and re-enabled for thread scheduling. It then competes in the
* usual manner with other threads for the right to synchronize on the
* object; once it has gained control of the object, all its
* synchronization claims on the object are restored to the status quo
* ante - that is, to the situation as of the time that the {@code wait}
* method was invoked. Thread <var>T</var> then returns from the
* invocation of the {@code wait} method. Thus, on return from the
* {@code wait} method, the synchronization state of the object and of
* thread {@code T} is exactly as it was when the {@code wait} method
* was invoked.
* <p>
* A thread can also wake up without being notified, interrupted, or
* timing out, a so-called <i>spurious wakeup</i>. While this will rarely
* occur in practice, applications must guard against it by testing for
* the condition that should have caused the thread to be awakened, and
* continuing to wait if the condition is not satisfied. In other words,
* waits should always occur in loops, like this one:
* <pre>
* synchronized (obj) {
* while (<condition does not hold>)
* obj.wait(timeout);
* ... // Perform action appropriate to condition
* }
* </pre>
* (For more information on this topic, see Section 3.2.3 in Doug Lea's
* "Concurrent Programming in Java (Second Edition)" (Addison-Wesley,
* 2000), or Item 50 in Joshua Bloch's "Effective Java Programming
* Language Guide" (Addison-Wesley, 2001).
*
* <p>If the current thread is {@linkplain java.lang.Thread#interrupt()
* interrupted} by any thread before or while it is waiting, then an
* {@code InterruptedException} is thrown. This exception is not
* thrown until the lock status of this object has been restored as
* described above.
*
* <p>
* Note that the {@code wait} method, as it places the current thread
* into the wait set for this object, unlocks only this object; any
* other objects on which the current thread may be synchronized remain
* locked while the thread waits.
* <p>
* This method should only be called by a thread that is the owner
* of this object's monitor. See the {@code notify} method for a
* description of the ways in which a thread can become the owner of
* a monitor.
*
* @param timeout the maximum time to wait in milliseconds.
* @throws IllegalArgumentException if the value of timeout is
* negative.
* @throws IllegalMonitorStateException if the current thread is not
* the owner of the object's monitor.
* @throws InterruptedException if any thread interrupted the
* current thread before or while the current thread
* was waiting for a notification. The <i>interrupted
* status</i> of the current thread is cleared when
* this exception is thrown.
* @see java.lang.Object#notify()
* @see java.lang.Object#notifyAll()
*/
public final native void wait(long timeout) throws InterruptedException;
翻译
导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量。
当前的线程必须拥有此对象监视器。
此方法导致当前线程(称之为 T)将其自身放置在对象的等待集中,然后放弃此对象上的所有同步要求。出于线程调度目的,线程 T 被禁用,且处于休眠状态,直到发生以下四种情况之一:
- 其他某个线程调用此对象的 notify 方法,并且线程 T 碰巧被任选为被唤醒的线程。
- 其他某个线程调用此对象的 notifyAll 方法。
- 其他某个线程中断线程 T。
- 已经到达指定的实际时间。但是,如果 timeout 为零,则不考虑实际时间,该线程将一直等待,直到获得通知。
然后,从对象的等待集中删除线程 T,并重新进行线程调度。然后,该线程以常规方式与其他线程竞争,以获得在该对象上同步的权利;一旦获得对该对象的控制权,该对象上的所有其同步声明都将被还原到以前的状态 - 这就是调用 wait 方法时的情况。然后,线程 T 从 wait 方法的调用中返回。所以,从 wait 方法返回时,该对象和线程 T 的同步状态与调用 wait 方法时的情况完全相同。
在没有被通知、中断或超时的情况下,线程还可以唤醒一个所谓的虚假唤醒 (spurious wakeup)。虽然这种情况在实践中很少发生,但是应用程序必须通过以下方式防止其发生,即对应该导致该线程被提醒的条件进行测试,如果不满足该条件,则继续等待。换句话说,等待应总是发生在循环中,如下面的示例:
synchronized (obj) {
while (<condition does not hold>)
obj.wait(timeout);
... //执行适当的操作
}
(有关这一主题的更多信息,请参阅 Doug Lea 撰写的《Concurrent Programming in Java (Second Edition)》(Addison-Wesley, 2000) 中的第 3.2.3 节或 Joshua Bloch 撰写的《Effective Java Programming Language Guide》(Addison-Wesley, 2001) 中的第 50 项。
如果当前线程在等待时被其他线程中断,则会抛出 InterruptedException。在按上述形式恢复此对象的锁定状态时才会抛出此异常。
注意,由于 wait 方法将当前的线程放入了对象的等待集中,所以它只能解除此对象的锁定;可以同步当前线程的任何其他对象在线程等待时仍处于锁定状态。
此方法只应由作为此对象监视器的所有者的线程来调用。请参阅 notify 方法,了解线程能够成为监视器所有者的方法的描述。
参数:
timeout - 要等待的最长时间(以毫秒为单位)。
抛出:
IllegalArgumentException - 如果超时值为负。
IllegalMonitorStateException - 如果当前的线程不是此对象监视器的所有者。
InterruptedException - 如果在当前线程等待通知之前或者正在等待通知时,另一个线程中断了当前线程。在抛出此异常时,当前线程的中断状态 被清除。
wait(long timeout, int nanos)
/**
* Causes the current thread to wait until another thread invokes the
* {@link java.lang.Object#notify()} method or the
* {@link java.lang.Object#notifyAll()} method for this object, or
* some other thread interrupts the current thread, or a certain
* amount of real time has elapsed.
* <p>
* This method is similar to the {@code wait} method of one
* argument, but it allows finer control over the amount of time to
* wait for a notification before giving up. The amount of real time,
* measured in nanoseconds, is given by:
* <blockquote>
* <pre>
* 1000000*timeout+nanos</pre></blockquote>
* <p>
* In all other respects, this method does the same thing as the
* method {@link #wait(long)} of one argument. In particular,
* {@code wait(0, 0)} means the same thing as {@code wait(0)}.
* <p>
* The current thread must own this object's monitor. The thread
* releases ownership of this monitor and waits until either of the
* following two conditions has occurred:
* <ul>
* <li>Another thread notifies threads waiting on this object's monitor
* to wake up either through a call to the {@code notify} method
* or the {@code notifyAll} method.
* <li>The timeout period, specified by {@code timeout}
* milliseconds plus {@code nanos} nanoseconds arguments, has
* elapsed.
* </ul>
* <p>
* The thread then waits until it can re-obtain ownership of the
* monitor and resumes execution.
* <p>
* As in the one argument version, interrupts and spurious wakeups are
* possible, and this method should always be used in a loop:
* <pre>
* synchronized (obj) {
* while (<condition does not hold>)
* obj.wait(timeout, nanos);
* ... // Perform action appropriate to condition
* }
* </pre>
* This method should only be called by a thread that is the owner
* of this object's monitor. See the {@code notify} method for a
* description of the ways in which a thread can become the owner of
* a monitor.
*
* @param timeout the maximum time to wait in milliseconds.
* @param nanos additional time, in nanoseconds range
* 0-999999.
* @throws IllegalArgumentException if the value of timeout is
* negative or the value of nanos is
* not in the range 0-999999.
* @throws IllegalMonitorStateException if the current thread is not
* the owner of this object's monitor.
* @throws InterruptedException if any thread interrupted the
* current thread before or while the current thread
* was waiting for a notification. The <i>interrupted
* status</i> of the current thread is cleared when
* this exception is thrown.
*/
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
if (nanos > 0) {
timeout++;
}
wait(timeout);
}
翻译
导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量。
此方法类似于一个参数的 wait 方法,但它允许更好地控制在放弃之前等待通知的时间量。用毫微秒度量的实际时间量可以通过以下公式计算出来:
1000000*timeout+nanos
在其他所有方面,此方法执行的操作与带有一个参数的 wait(long) 方法相同。需要特别指出的是,wait(0, 0) 与 wait(0) 相同。
当前的线程必须拥有此对象监视器(当前线程必须取得锁的所有权)。该线程发布对此监视器的所有权,并等待下面两个条件之一发生:
- 其他线程通过调用 notify 方法,或 notifyAll 方法通知在此对象的监视器上等待的线程醒来。
- timeout 毫秒值与 nanos 毫微秒参数值之和指定的超时时间已用完。
然后,该线程等到重新获得对监视器的所有权后才能继续执行。
对于某一个参数的版本,实现中断和虚假唤醒是有可能的,并且此方法应始终在循环中使用:
synchronized (obj) {
while (<condition does not hold>)
obj.wait(timeout);
... //执行适当的操作
}
此方法只应由作为此对象监视器的所有者的线程来调用。请参阅 notify 方法,了解线程能够成为监视器所有者的方法的描述。
参数:
timeout - 要等待的最长时间(以毫秒为单位)。
nanos - 额外时间(以毫微秒为单位,范围是 0-999999)。
抛出:
IllegalArgumentException - 如果超时值是负数,或者毫微秒值不在 0-999999 范围内。
IllegalMonitorStateException - 如果当前线程不是此对象监视器的所有者。
InterruptedException - 如果在当前线程等待通知之前或者正在等待通知时,其他线程中断了当前线程。在抛出此异常时,当前线程的中断状态被清除。
对 wait 方法的总结
三个重载方法的对比
三个 wait 方法中 wait() 和 wait(long timeout, int nanos) 方法其实都是调用 wait(long timeout) 方法实现的,我们来分析一下。
wait()方法
public final void wait() throws InterruptedException {
wait(0); //调用wait(long timeout)方法
}
wait() 方法实现了使一个线程一直处于等待的状态,通过调用wait(0),即永远不取消等待。
wait(long timeout, int nanos)方法
public final void wait(long timeout, int nanos) throws InterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");//超时值是负数
}
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");//纳秒超时值超出范围
}
//这里就有意思了,只要纳秒值大于0,就给毫秒超时值加一
if (nanos > 0) {
timeout++;
}
//把毫秒超时值传给wait(long timeout)方法,暂停timeout毫秒
wait(timeout);
}
其实吧,这个方法我也没太懂设计者的意思,为什么要引入一个纳秒超时值,而且这个纳秒超时值也只是精确到毫秒级别而已,个人猜测可能是由于纳秒级时间太短处理起来比较麻烦,所以对参数 nanos 采取了近似处理。
而且这个方法JDK1.6和JDK1.8的还有所区别,下面是JDK1.6的源码:
public final void wait(long timeout, int nanos) throws nterruptedException {
if (timeout < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
//nanos 单位为纳秒, 1毫秒 = 1000 微秒 = 1000 000 纳秒
if (nanos < 0 || nanos > 999999) {
throw new IllegalArgumentException(
"nanosecond timeout value out of range");
}
// nanos 大于 500000 即半毫秒 就timout 加1毫秒
// 特殊情况下: 如果timeout为0且nanos大于0,则timout加1毫秒
if (nanos >= 500000 || (nanos != 0 && timeout == 0)) {
timeout++;
}
wait(timeout);
}
我们可以发现JDK1.8直接选择将 nanos > 0 默认为了原来JDK1.6的 nanos >= 500000 ,也就是说在JDK1.8及以后,nanos值为10、100还是500000都不再会影响 wait(long timeout, int nanos) 方法的执行结果了,只要 nanos > 0 都给你 timeout 加一。
wait状态的几种退出方式
- 其他某个线程调用该对象监视器的 notify 方法,并且在 wait 状态的目标线程碰巧被选为被唤醒的线程。
- 其他某个线程调用该对象监视器的 notifyAll 方法。
- 其他某个线程中断等待中的目标线程。
- 达到指定的等待时间。
wait 和 sleep 的主要区别
wait 在使用时会释放掉线程占用的锁,在wait状态结束后再收回释放掉的锁;而 sleep方法不会,而是继续占用着形成阻塞的状态。
finalize()
/**
* Called by the garbage collector on an object when garbage collection
* determines that there are no more references to the object.
* A subclass overrides the {@code finalize} method to dispose of
* system resources or to perform other cleanup.
* <p>
* The general contract of {@code finalize} is that it is invoked
* if and when the Java™ virtual
* machine has determined that there is no longer any
* means by which this object can be accessed by any thread that has
* not yet died, except as a result of an action taken by the
* finalization of some other object or class which is ready to be
* finalized. The {@code finalize} method may take any action, including
* making this object available again to other threads; the usual purpose
* of {@code finalize}, however, is to perform cleanup actions before
* the object is irrevocably discarded. For example, the finalize method
* for an object that represents an input/output connection might perform
* explicit I/O transactions to break the connection before the object is
* permanently discarded.
* <p>
* The {@code finalize} method of class {@code Object} performs no
* special action; it simply returns normally. Subclasses of
* {@code Object} may override this definition.
* <p>
* The Java programming language does not guarantee which thread will
* invoke the {@code finalize} method for any given object. It is
* guaranteed, however, that the thread that invokes finalize will not
* be holding any user-visible synchronization locks when finalize is
* invoked. If an uncaught exception is thrown by the finalize method,
* the exception is ignored and finalization of that object terminates.
* <p>
* After the {@code finalize} method has been invoked for an object, no
* further action is taken until the Java virtual machine has again
* determined that there is no longer any means by which this object can
* be accessed by any thread that has not yet died, including possible
* actions by other objects or classes which are ready to be finalized,
* at which point the object may be discarded.
* <p>
* The {@code finalize} method is never invoked more than once by a Java
* virtual machine for any given object.
* <p>
* Any exception thrown by the {@code finalize} method causes
* the finalization of this object to be halted, but is otherwise
* ignored.
*
* @throws Throwable the {@code Exception} raised by this method
* @see java.lang.ref.WeakReference
* @see java.lang.ref.PhantomReference
* @jls 12.6 Finalization of Class Instances
*/
protected void finalize() throws Throwable { }
翻译
当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。子类重写 finalize 方法,以配置系统资源或执行其他清除。
finalize 的常规协定是:当 JavaTM 虚拟机已确定尚未终止的任何线程无法再通过任何方法访问此对象时,将调用此方法,除非由于准备终止的其他某个对象或类的终结操作执行了某个操作。finalize 方法可以采取任何操作,其中包括再次使此对象对其他线程可用;不过,finalize 的主要目的是在不可撤消地丢弃对象之前执行清除操作。例如,表示输入/输出连接的对象的 finalize 方法可执行显式 I/O 事务,以便在永久丢弃对象之前中断连接。
Object 类的 finalize 方法执行非特殊性操作;它仅执行一些常规返回。Object 的子类可以重写此定义。
Java 编程语言不保证哪个线程将调用某个给定对象的 finalize 方法。但可以保证在调用 finalize 时,调用 finalize 的线程将不会持有任何用户可见的同步锁定。如果 finalize 方法抛出未捕获的异常,那么该异常将被忽略,并且该对象的终结操作将终止。
在启用某个对象的 finalize 方法后,将不会执行进一步操作,直到 Java 虚拟机再次确定尚未终止的任何线程无法再通过任何方法访问此对象,其中包括由准备终止的其他对象或类执行的可能操作,在执行该操作时,对象可能被丢弃。
对于任何给定对象,Java 虚拟机最多只调用一次 finalize 方法。
finalize 方法抛出的任何异常都会导致此对象的终结操作停止,但可以通过其他方法忽略它。
抛出:
Throwable - 此方法抛出的 Exception
总结
finalize() 方法什么时候会被调用
- 所有对象被GC时自动调用,比如运行System.gc()的时候.
- 程序退出时为每个对象调用一次 finalize() 方法。
- 显式的调用 finalize() 方法
当某个对象被系统收集为无用信息的时候,finalize()将被自动调用,但是 JVM 不保证 finalize() 一定被调用,也就是说,finalize()的调用是不确定的。
测试代码:
/**
* @author 小关同学
* @create 2021/8/16
*/
class Garbage
{
protected void finalize() throws Throwable{
System.out.println("垃圾被清除");
}
}
public class FinalizeTest {
public static void main(String[] args) {
for (int i = 0;i < 1100000;i++){
Garbage garbage = new Garbage();
garbage = null; //使garbage在堆中没有指向,变成垃圾以触发GC
}
}
}
执行结果:
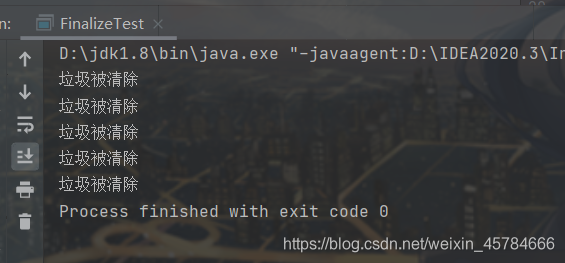
很神奇的是,你不多进行几次循环产生多一些垃圾,是很难触发GC来调用 finalize() 方法的。
registerNatives()
这个方法由 native 修饰,可以确定它是一个本地方法
private static native void registerNatives();
static {
registerNatives();
}
什么是本地方法?
Java中有两种方法:Java方法和本地方法。
Java方法是由Java语言编写,编译成字节码,存储在class文件中。
本地方法是由其他语言(比如C,C++,或者汇编)编写的,编译成和处理器相关的机器代码。本地方法保存在动态连接库中,格式是各个平台专有的。Java方法是平台无关的,本地方法却不是。运行中的Java程序调用本地方法时,虚拟机装载包含这个本地方法的动态库,并调用这个方法。本地方法是联系Java程序和底层主机操作系统的连接方法。
registerNatives()的作用
从名字中我们不难看出 registerNatives() 是用来注册本地方法的,通过加载在静态代码块中的 registerNatives() 方法来完成该类中其他本地方法的注册。
借鉴和引用:
Java finalize方法使用
java中finalize()方法
Object类中的registerNatives方法的作用深入介绍
Object类中的registerNatives本地方法的作用















 2238
2238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









