






1. 前言
MySQL 的分页查询在我们的开发过程中还是很常见的,比如一些后台管理系统,我们一般会有查询订单列表页、商品列表页等。
示例:
SELECT * FROM `goods` order by create_time limit 0, 10;在了解order by和limit的工作原理之前,我们首先回顾下 MySQL 的执行流程和索引结构。
注:下面没有特别说明默认 MySQL 的引擎为 InnoDB
为讲述方便使用 select * ,生产环境不建议使用
1.1. 执行流程
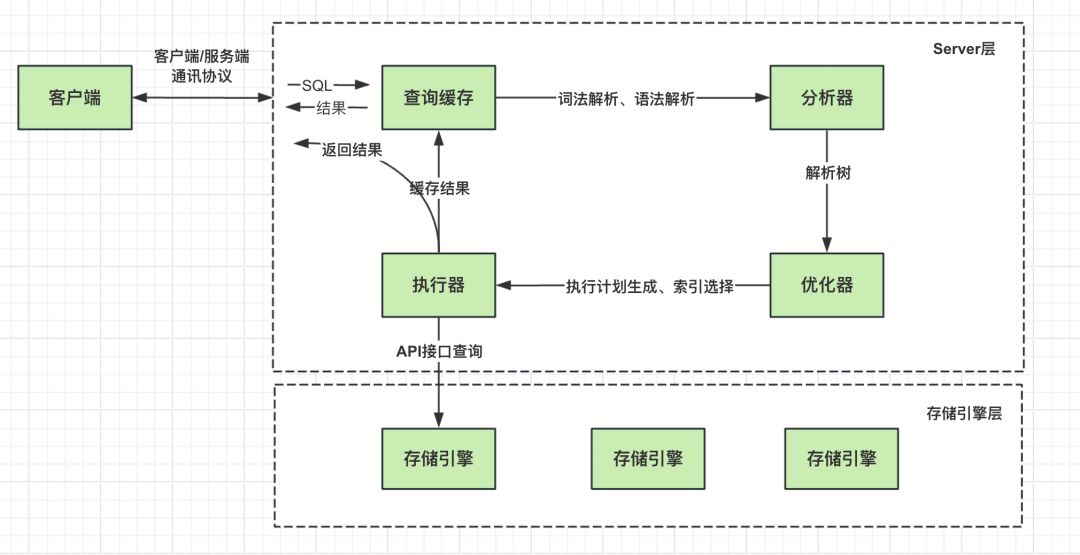
MySQL 可以分为 Server 层和存储引擎层两部分,对于这个就不展开讲了。只需要知道一条 SQL 语句是从客户端发起请求到 Server 层,Server 层处理之后选出成本最低的执行计划去存储引擎层进行数据查询,查询出来的数据返回给 Server 层处理,最后返回给客户端。(存储引擎层根据扫描区间定位拿到数据给到 Server 层,剩下的过滤、排序、分页等操作是在 Server 层载进行处理的)。
1.2 索引结构

InnoDB 存储引擎的索引是一颗 B+ 树,只有主键索引树会存储全部的行记录数据,二级索引只会存储该记录对应的主键 id。所以我们使用二级索引查询数据时,如果查询的字段在二级索引没办法完全覆盖,则需要回表。
2. order by 工作原理
准备工作
创建一张商品表,并且给价格字段设置索引
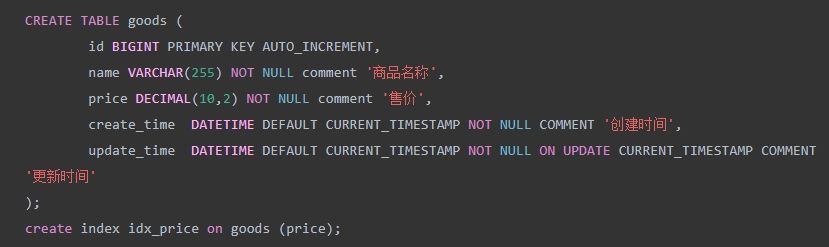
插入测试数据
2.1 索引扫描排序
EXPLAIN SELECT * FROM goods where price > 10 and price < 13 ORDER BY price;
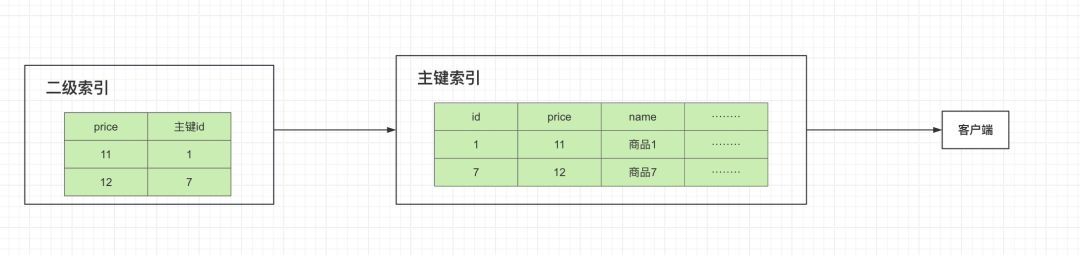
我们发现这条 sql 使用了索引 idx_price,索引结构如下:
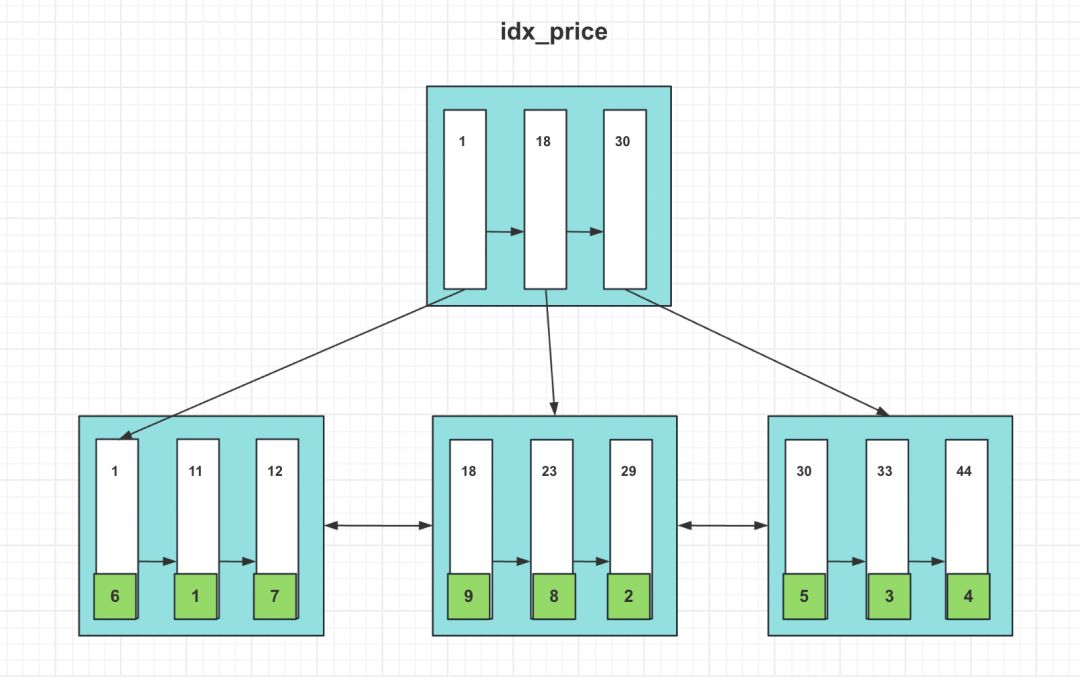
首先会根据二级索引idx_price进行查询找到满足price > 10 and price < 13区间的主键值,因为我们的查询条件是SELECT *,所以需要回表查询到对应的行记录。由于ORDER BY price,我们是需要对查询出来的结果按照价格从小到大进行排序。我们刚刚的数据就是从二级索引idx_price查询出来的,本就是根据price字段排序的,所以无需再排序,直接把查询的数据返回给客户端就行了。
2.2 文件排序(filesort)
以下 3条 sql 语句都会使用文件排序
-- Using where; Using filesortEXPLAIN SELECT * FROM goods where price > 10 and price < 30 ORDER BY price;
-- Using where; Using filesort
EXPLAIN SELECT * FROM goods where name like '商品 1%' ORDER BY price;
-- Using index condition; Using filesort
EXPLAIN SELECT * FROM goods where price > 10 and price < 13 ORDER BY name;
对于第二条 sql ,我们很容易判断出来,使用不了二级索引idx_price,只能全表扫描查询出符合条件的行记录再去进行文件排序。
那么第一条 sql 只是查询范围比之前的更大了,为什么就不走二级索引了呢?
我们前面介绍执行流程时说道:MySQL 会选择执行成本最低的执行计划。这条 sql 的查询范围是price > 10 and price < 30,满足这个条件的数据是很多的,每一条数据都需要进行回表查询。这样大量的回表查询,MySQL 认为是很慢的,所以没有使用二级索引。
第三条 sql 虽然可以使用到二级索引idx_price,但是需要排序的字段是name,那么二级索引的作用就只是帮助我们加快查询,而排序操作还是需要使用文件排序。
什么是文件排序呢?
文件排序分成两种:全字段排序、rowid 排序。接下来,我们分别讲解这两种排序工作原理。
2.2.1 全字段排序
MySQL 会给每个线程分配一块内存用于排序 sort_buffer。sort_buffer_size,就是 MySQL 为排序开辟内存(sort_buffer)的大小。
如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件来辅助排序。
EXPLAIN SELECT * FROM goods where price > 10 and price < 13 ORDER BY name;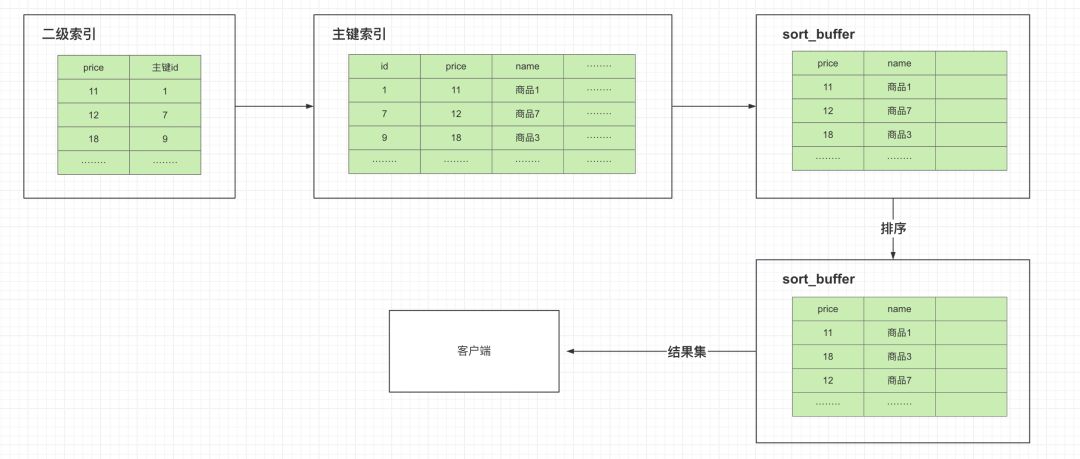
我们根据这条 sql 来分析查询过程:
先根据二级索引idx_price查询出满足过滤条件的数据
根据主键 id 进行回表操作查询出对应的行记录
数据汇总到 sort_buffer 按照name进行排序
将排序好的结果集返回给客户端
2.2.2 rowid 排序
我们发现全字段排序会存在一个问题:如果表中的字段非常多,我们把整个行记录放入 sort_buffer 里面进行排序时,能够放入的行记录就会很少,排序性能差。
max_length_for_sort_data ,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。使用 rowid 排序:需要排序的字段 + 主键 id 放入 sort_buffer 进行排序。
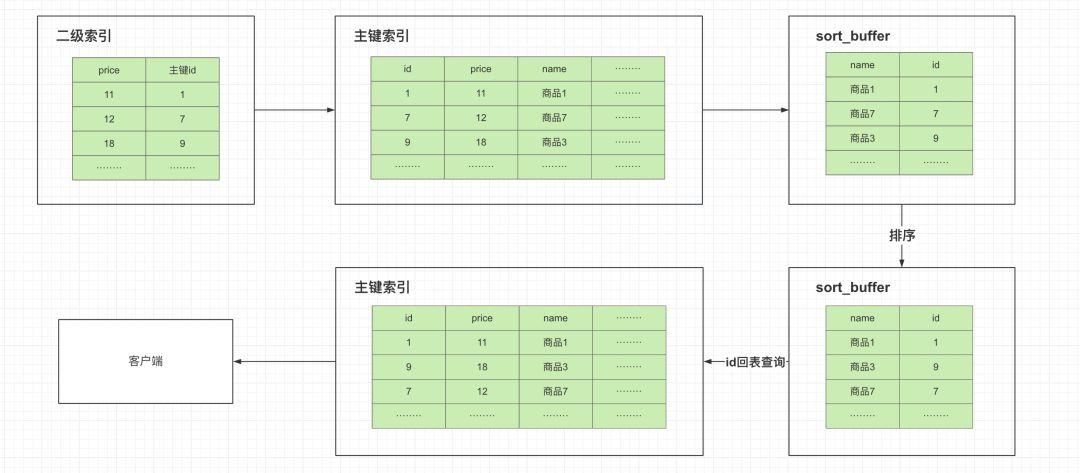
还是使用上述 sql 分析:
- 可以使用二级索引,所以先根据二级索引idx_price查询出满足过滤条件的数据
- 根据主键 id 进行回表操作查询出对应的行记录
- 将排序字段name和主键 id 一起放入 sort_buffer 进行排序
- 根据主键 id 再去主键索引查询全部字段返回给客户端
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
对于 InnoDB 表来说,rowid 排序要求回表多造成磁盘读,因此不会被优先选择。
2.2.3 排序算法
我们前面说在 sort_buffer 进行排序,但是没有说明具体是什么排序算法,其实我们这个排序算法是需要分情况的,具体如下:
- 若排序内容能全部放入内存,则仅在内存中使用快速排序;
- 若排序内容不能全部放入内存,则分批次将排好序的内容放入文件,然后将多个文件进行归并排序
- 若排序中包含 limit 语句,则使用堆排序优化排序过程
3. limit 工作原理
Server 层维护了一个称作 limit_count 的变量用于统计已经跳过了多少条记录。limit m , n 工作原理就是先读取前面 m+n 条记录,然后抛弃前 m条,读后面 n条想要的,所以 m越大,偏移量越大,性能就越差。
EXPLAIN SELECT * FROM goods where price > 10 and price < 13 ORDER BY name limit 500, 10;如上述 sql 语句,MySQL 先查询 510 条数据,按照ORDER BY的工作原理进行条件查询和排序,最后汇总的结果在返回给客户端之前,MySQL 会截取第 501 到 510 条数据,最后把这 10 行记录返回给前端。
4. 常见问题分析
4.1 排序字段使用非唯一字段导致乱序问题
我们平常使用的分页查询,如果没有用到索引排序底层的排序算法是堆排序,由于是堆排序是不稳定排序,会产生乱序问题。
SELECT * FROM `goods` order by create_time limit 0, 10;分页查询商品表,根据创建时间进行排序
但是如果此时数据库的商品数据都是通过 Excel 导入进去的,那么它们的创建时间都是一样的,那就会乱序。


5 个商品的顺序是不一定的(堆排序:不稳定排序),当我们从第一页到第二页时,商品 3又到了第一页。
那么我们就一直找不到商品 3。对于这个问题,我们可以改成按照主键 id 排序。
4.2 深度分页问题
SELECT * FROM goods ORDER BY price LIMIT 80000, 10
这样的 sql 就是深度分页了,我们之前讲到,MySQL 的底层会查询出 80010 条数据进行文件排序(因为查询数量太多,回表次数过多,MySQL 便不使用二级索引),然后再截取第 80001 到 第80010 条数据返回给客户端。
要解决这种深度分页问题首先应该在产品的设计方面避免这种情况,还有就是我们在查询分页数据时应该需要根据时间做好限制,减少数据,以及对前端传进来的 start、limit 字段进行判断限制。如果还是需要深度分页,就需要利用子查询来实现。
SELECT * FROM goods gINNER JOIN
( SELECT id FROM goods ORDER BY price LIMIT 80000, 10) AS d
ON g.id=d.id;

子查询使用二级索引查出满足条件的主键,然后进行分页过滤出我们需要主键 id,再去主键索引查询数据(因为排序字段就是我们的二级索引字段,所以查询出来的数据直接就是有序的,无需再进行文件排序)。















 1395
1395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









