







1.纯文字
from docx import Document
document=Document('d:/python_test/word/长恨歌.docx') #路径
all_paragraph=document.paragraphs
for paragraph in all_paragraph:
print(paragraph.text) #直接打印text即可
# for run in paragraph.runs: #这种方式有莫名其妙的换行
# print(run.text)运行结果:
2.读表格
from docx import Document
document=Document('d:/python_test/word/长恨歌2.0.docx')
all_table=document.tables
for table in all_table:
for row in table.rows:
for cell in row.cells:
print(cell.text) 3.文字加表格
import zipfile
word=zipfile.ZipFile('d:/python_test/word/长恨歌3.0.docx') #先压缩
xml=word.read('word/document.xml').decode('utf-8') #document.xml中有我们需要的文字
#print(xml)
xml_list=xml.split('<w:t>') #生成的结果是:汉字在,和</w:t>之间
#print(xml_list) #这里面没有<w:t>,只有</w:t>
text_list=[]
for i in xml_list:
if i.find('</w:t>')+ 1: #find函数,找到返回第一个位置,否则返回-1
text_list.append(i[:i.find('</w:t>')]) #找到</w:t>将前面你的汉字加入
else:
pass
#print(text_list)
text="".join(text_list)
print(text)长恨歌3.0中的内容如下:
我们先来看一下zip中的document.xml中的内容:直接修改后缀为zip即可
我们需要的汉字都在document.xml中,因此要对它进行操作
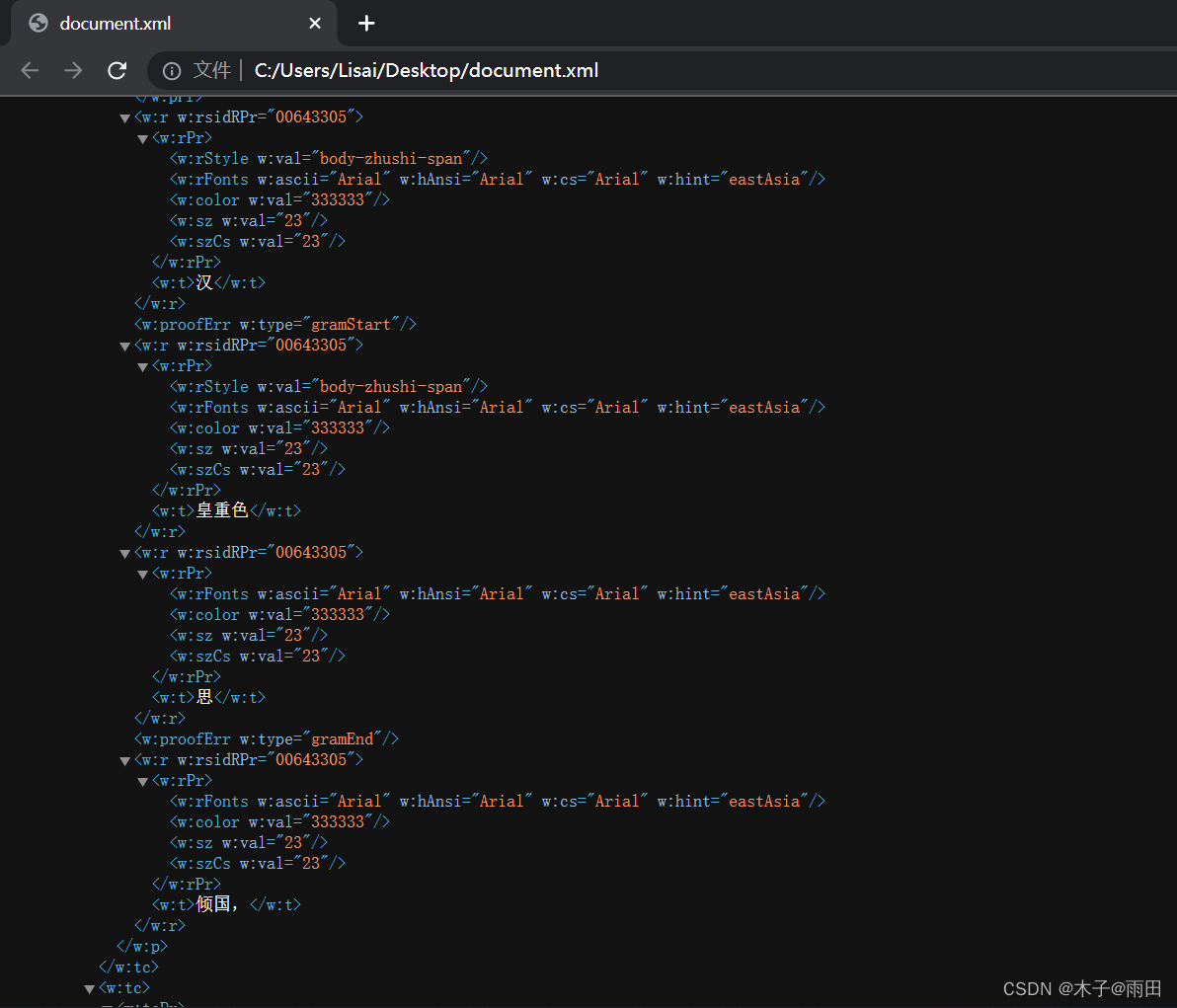
下图是xml中的内容

下图是test_list中的内容: 
下图是text中的内容: 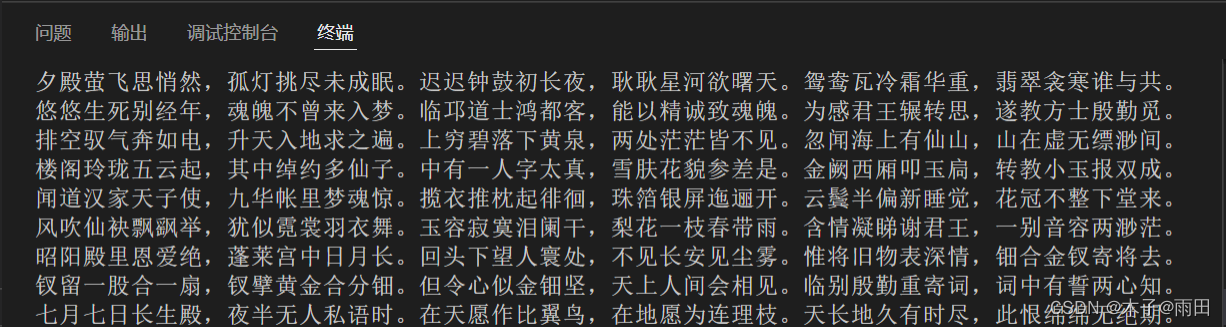
4.创造模板函数
#库引入
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt #磅数
from docx.oxml.ns import qn #中文格式
document=Document()
document.styles['Normal'].font.name=u'黑体' #设置基础字体
#设置中文字体
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'),u'黑体')
def add_content(content):
p=document.add_paragraph()
p.alignment=WD_ALIGN_PARAGRAPH.LEFT
r=p.add_run(str(content))
r.font.size=Pt(16)
p.space_after=Pt(5)
p.space_before=Pt(5)
names=["哈士奇","大傻狗","小犊崽子"]
for name in names:
add_content("你好你好你好你安好%s" %name)
document.save('d:/python_test/word/%s.docx' %names[0])运行结果: 
5.套用模板
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Pt #磅数
from docx.oxml.ns import qn #中文格式
document=Document('d:/python_test/word/长恨歌3.0.docx')
document.styles['Normal'].font.name=u'宋体' #设置基础字体
#设置中文字体
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'),u'宋体')
document.styles['Normal'].font.size=Pt(11.5)
def change_text(old_text,new_text):
all_paragraph=document.paragraphs
for para in all_paragraph:
for run in para.runs:
run_text=run.text.replace(old_text,new_text) #内容代替
run.text=run_text
all_table=document.tables
for table in all_table:
for row in table.rows:
for cell in row.cells:
cell_text=cell.text.replace(old_text,new_text)
cell.text=cell_text
change_text('不' ,'ok')
change_text('女','孬')
document.save('d:/python_test/word/长恨歌4.0.docx') 运行结果: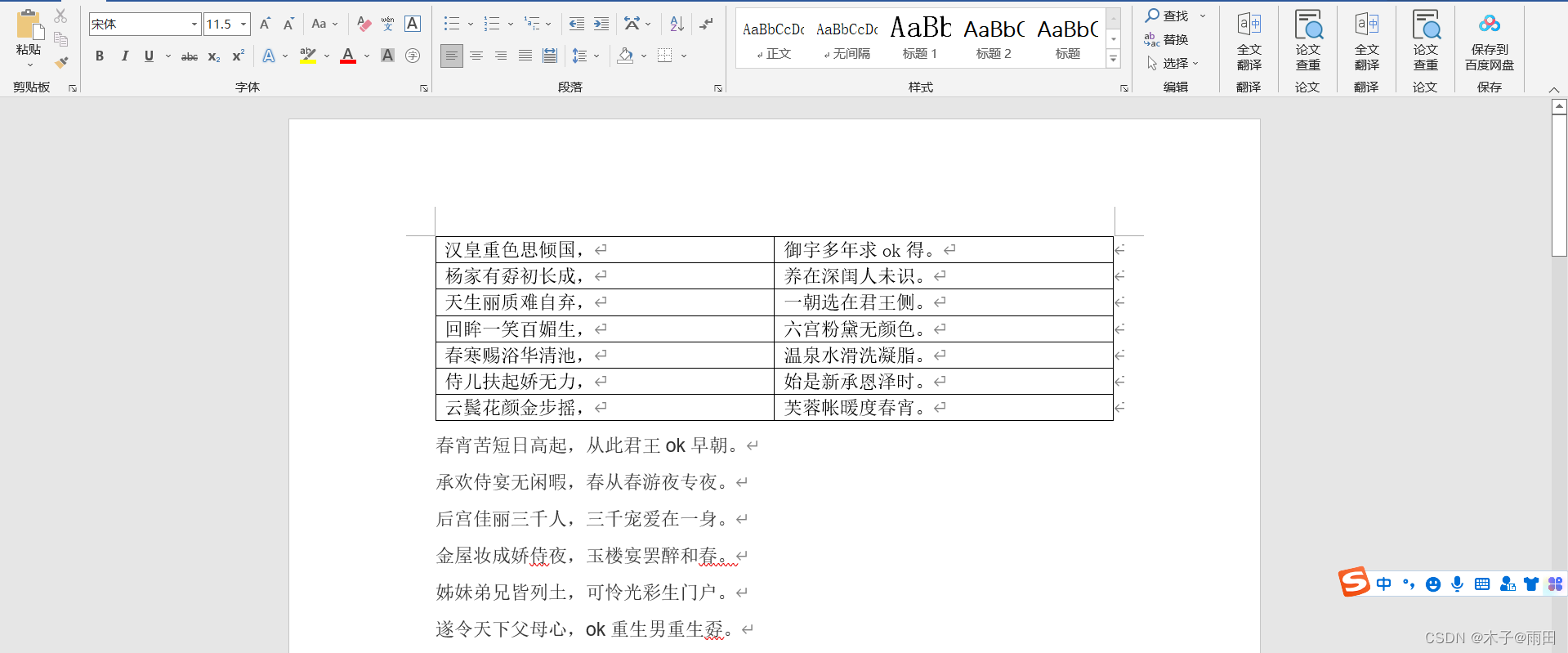














 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









