







OS:吐槽一下,我的破电脑,昨天对于github上下载的那个jieba命名用不了,现在,一晚上,我今天能用了!!千年虫是不是依靠重启和等待就可以解决了!关键是,我的电脑他自己一晚上把这个程序自己解决了!真实我的贴心小电脑!喵喵喵~~~
1.下载jieba-analysis
这个是gitee码云上的资源:
https://gitee.com/langhu/jieba-analysis-mend/
博客园:https://www.cnblogs.com/yifeiyu/p/10991001.html
这个是github上的网址:https://github.com/huaban/jieba-analysis
有一个原版的,有一个huaban上的!我使用的是花瓣上的!

2.打开代码包
首先,它是这样的!
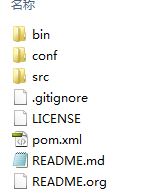
它是一个maven项目!但是,我使用的是单纯的IDE,所以,现在,我们把它改成IDE可以初级使用的程序!
1)从图中的路径com开始复制到你新建的java project的src中去!

2)resources文件夹下面的通通复制到src中去!不要从main开始复制,也不要从java开始复制,从java子目录com开始复制!

3)最后,你会得到这样的文件夹目录:


PS:其他的,因为不是maven项目,所以复不复制估计都没啥用!
4)在IDE打开后,如下图所示:

3.开始调试程序!
补充一个中文乱码问题的解决博客:
https://blog.csdn.net/lzc2644481789/article/details/97244261
window->Proferences->在搜索框输入"enc"->选择Workpalce->UTF-8
右击那个项目,选择Porperties->Resource->UTF-8
1)问题一:引用包路径错误!
解决方案:按照引用的方式,重新引用!
2)问题二:com.huaban.analysis.jieba里面的JiebaSegmenter类缺少一个引用
解决方案:import java.nio.file.Path;(昨天我写这个的时候,其实,运行还总是出错!但是,今天就能用了!)
3)在com.huaban.analysis.jieba里面添加一个testDemo类,程序如下:
package com.huaban.analysis.jieba;
import com.huaban.analysis.jieba.JiebaSegmenter.SegMode;
public class testDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
JiebaSegmenter segmenter = new JiebaSegmenter();
String[] sentences =
new String[] {"这是一个伸手不见五指的黑夜。我叫孙悟空,我爱北京,我爱Python和C++。", "我不喜欢日本和服。", "雷猴回归人间。",
"工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作", "结果婚的和尚未结过婚的"};
for (String sentence : sentences) {
System.out.println(segmenter.process(sentence, SegMode.INDEX).toString());
}
}
}
import com.huaban.analysis.jieba.JiebaSegmenter.SegMode;这个引用明明理论上是不需要的,但是它必须得引用!否则今天这个时刻,它就是用不了的!
我运行了这个程序:
结果:
main dict load finished, time elapsed 4070 ms
model load finished, time elapsed 1000 ms.
[[这是, 0, 2], [一个, 2, 4], [伸手, 4, 6], [不见, 6, 8], [五指, 8, 10], [伸手不见五指, 4, 10], [的, 10, 11], [黑夜, 11, 13], [。, 13, 14], [我, 14, 15], [叫, 15, 16], [悟空, 17, 19], [孙悟空, 16, 19], [,, 19, 20], [我, 20, 21], [爱, 21, 22], [北京, 22, 24], [,, 24, 25], [我, 25, 26], [爱, 26, 27], [python, 27, 33], [和, 33, 34], [c++, 34, 37], [。, 37, 38]]
[[我, 0, 1], [不, 1, 2], [喜欢, 2, 4], [日本, 4, 6], [和服, 6, 8], [。, 8, 9]]
[[雷猴, 0, 2], [回归, 2, 4], [人间, 4, 6], [。, 6, 7]]
[[工信处, 0, 3], [干事, 4, 6], [女干事, 3, 6], [每月, 6, 8], [经过, 8, 10], [下属, 10, 12], [科室, 12, 14], [都, 14, 15], [要, 15, 16], [亲口, 16, 18], [交代, 18, 20], [24, 20, 22], [口, 22, 23], [交换, 23, 25], [换机, 24, 26], [交换机, 23, 26], [等, 26, 27], [技术, 27, 29], [技术性, 27, 30], [器件, 30, 32], [的, 32, 33], [安装, 33, 35], [工作, 35, 37]]
[[结果, 0, 2], [婚, 2, 3], [的, 3, 4], [和, 4, 5], [尚未, 5, 7], [结过, 7, 9], [结过婚, 7, 10], [的, 10, 11]]
4)分析:
此程序先new了一个JiebaSegmenter,并调用了segmenter.process(sentence, SegMode.INDEX).toString()。
回溯法找到原函数process:
public List<SegToken> process(String paragraph, SegMode mode) {
List<SegToken> tokens = new ArrayList<SegToken>();
StringBuilder sb = new StringBuilder();
int offset = 0;
for (int i = 0; i < paragraph.length(); ++i) {
char ch = CharacterUtil.regularize(paragraph.charAt(i));
if (CharacterUtil.ccFind(ch))
sb.append(ch);
else {
if (sb.length() > 0) {
// process
if (mode == SegMode.SEARCH) {
for (String word : sentenceProcess(sb.toString())) {
tokens.add(new SegToken(word, offset, offset += word.length()));
}
}
else {
for (String token : sentenceProcess(sb.toString())) {
if (token.length() > 2) {
String gram2;
int j = 0;
for (; j < token.length() - 1; ++j) {
gram2 = token.substring(j, j + 2);
if (wordDict.containsWord(gram2))
tokens.add(new SegToken(gram2, offset + j, offset + j + 2));
}
}
if (token.length() > 3) {
String gram3;
int j = 0;
for (; j < token.length() - 2; ++j) {
gram3 = token.substring(j, j + 3);
if (wordDict.containsWord(gram3))
tokens.add(new SegToken(gram3, offset + j, offset + j + 3));
}
}
tokens.add(new SegToken(token, offset, offset += token.length()));
}
}
sb = new StringBuilder();
offset = i;
}
if (wordDict.containsWord(paragraph.substring(i, i + 1)))
tokens.add(new SegToken(paragraph.substring(i, i + 1), offset, ++offset));
else
tokens.add(new SegToken(paragraph.substring(i, i + 1), offset, ++offset));
}
}
if (sb.length() > 0)
if (mode == SegMode.SEARCH) {
for (String token : sentenceProcess(sb.toString())) {
tokens.add(new SegToken(token, offset, offset += token.length()));
}
}
else {
for (String token : sentenceProcess(sb.toString())) {
if (token.length() > 2) {
String gram2;
int j = 0;
for (; j < token.length() - 1; ++j) {
gram2 = token.substring(j, j + 2);
if (wordDict.containsWord(gram2))
tokens.add(new SegToken(gram2, offset + j, offset + j + 2));
}
}
if (token.length() > 3) {
String gram3;
int j = 0;
for (; j < token.length() - 2; ++j) {
gram3 = token.substring(j, j + 3);
if (wordDict.containsWord(gram3))
tokens.add(new SegToken(gram3, offset + j, offset + j + 3));
}
}
tokens.add(new SegToken(token, offset, offset += token.length()));
}
}
return tokens;
}
由于原函数没有注释,所以看不懂!打算把源代码重新看一遍!
吐槽: 这个全是红叉的程序,是一个测试程序!由于本人完全没有学过测试,所以完全不会!
下面的这个junit是测试用的!其实,这个程序要好用许多,但是,我不会这个东西!所以放弃了!!
















 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









