







文章目录
事务
MyISAM和InnoDB区别
1.是否支持行级锁
MyISAM只有表级锁,InnoDB有行级锁和表级锁
MyISAM一锁就锁住了整个表,InnoDB并发性能更好
2.是否支持事务
MyISAM不支持
InnoDB支持,有commit和rollback的功能
3.是否支持外键
MyISAM不支持
InnoDB支持
- MySQL InnoDB 引擎使用 redo log(重做日志) 保证事务的持久性,使用 undo log(回滚日志) 来保证事务的原子性。
- MySQL InnoDB 引擎通过 锁机制、MVCC 等手段来保证事务的隔离性( 默认支持的隔离级别是
REPEATABLE-READ)。 - 保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
锁机制和InnoDB锁算法
MyISAM和InnoDB存储引擎的锁
- **表级锁:**MySQL中锁定 粒度最大的一种锁,实现简单,加锁快,不会形成死锁,冲突概率高,并发度低
- 行级锁:粒度最小的一种锁,只对当前操作行加锁
InnoDB 存储引擎的锁的算法有三种
- Record lock:记录锁,单个行记录上的锁
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
- Next-key lock:record+gap 临键锁,锁定一个范围,包含记录本身
并发事务带来哪些问题
- 脏读(Dirty Read): A写 B读
- 丢失修改(Lost to modify): A 读 B读 A写 B写 ,这样A就会丢失修改
- 不可重复读(Unrepeatable read): 一个事务内多次读同一数据,A读 B读 B写 A读 这就出现了不可重复读
- 幻读(Phantom read): A 读取几组数据 然后B插入几组数据,就会出现原本不存在的记录
不可重复读和幻读区别:
都是多次读取一条数据,但是不可重复的是发现某些列被修改,幻读是新增或删除一条记录发现记录增加或减少
事务隔离级别
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可串行化): 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
在RR隔离级别(REPEATABLE-READ级别下)
Innodb使用MVCC和next-key locks 解决幻读,
MVCC解决是普通读的幻读,next-keylocks解决当前读情况下的幻读
幻读:
事务A做A的操作,查询A的事务,但是发现出现了其他的记录
怎么解决的?
当前读
在RR的情况下,假设使用的是当前读,加锁了的读
select * from table where id>3 锁住的就是id=3这条记录以及id>3这个区间范围,锁住索引记录之间的范围,避免范围间插入记录,以避免产生幻影行记录。
普通读
默认的隔离级别(REPEATABLE READ)下,增删查改变成了这样:
SELECT
读取创建版本小于或等于当前事务版本号,并且删除版本为空或大于当前事务版本号的记录。这样可以保证在读取之前记录是存在的
INSERT
将当前事务的版本号保存至行的创建版本号
UPDATE
新插入一行,并以当前事务的版本号作为新行的创建版本号,同时将原记录行的删除版本号设置为当前事务版本号
DELETE
将当前事务的版本号保存至行的删除版本号
SQL优化
SQL优化
MySQL的赋值原理和流程
主从复制的作用:
1.主数据库出问题,可以切换到从数据库
2.从数据库层面实现读写分离
3.数据库日常备份
主从复制解决的问题:
- 数据分布:随意开始和停止复制
- **负载均衡:**降低单个服务器压力
- 高可用和故障切换: 帮助应用程序避免单点失败
- 升级测试: 可以用更高版本MySQL作为从库
主从复制原理:
- 主库数据更新到二进制日志中
- 从库从主库的日志复制到从库的日志中
- 从库读取中断日志的事件
基本原理流程,3个线程以及之间的关联
主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中;
从:sql执行线程——执行relay log中的语句;
复制过程
方案一
使用mysql-proxy代理
优点:直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号,mysql官方不建议实际生产中使用
缺点:降低性能, 不支持事务
方案二
使用AbstractRoutingDataSource+aop+annotation在dao层决定数据源。
方案三
使用AbstractRoutingDataSource+aop+annotation在service层决定数据源,可以支持事务.
缺点:类内部方法通过this.xx()方式相互调用时,aop不会进行拦截,需进行特殊处理。
索引
索引的底层数据结构
Hash表&B+树
通过哈希表+哈希算法我们可以通过key来找到index进而找到value
问题:
哈希表有Hash冲突问题,多个不同的key得到的index相同,我们解决办法是链地址法,JDK1.8之后采用的是红黑树的方法
Hash表这么快,为什么MySQL没有采用其作为索引的数据结构
1.Hash冲突问题
2.Hash索引不支持顺序和范围查询
B树和B+树
B树也叫B-树,全称是多路平衡查找树,B树和B+树是**Balance(平衡)**的意思
B 树& B+树两者有何异同呢?
- B树的所有节点即存放key,也存放data,B+只有叶子节点存放key和data,其他节点只存放key
- B树叶子节点独立,B+树叶子节点有一条引用链向与他相邻节点
- B树采用二分查找,可能到不了叶子节点检索就结束,B+树都是从根->叶子节点
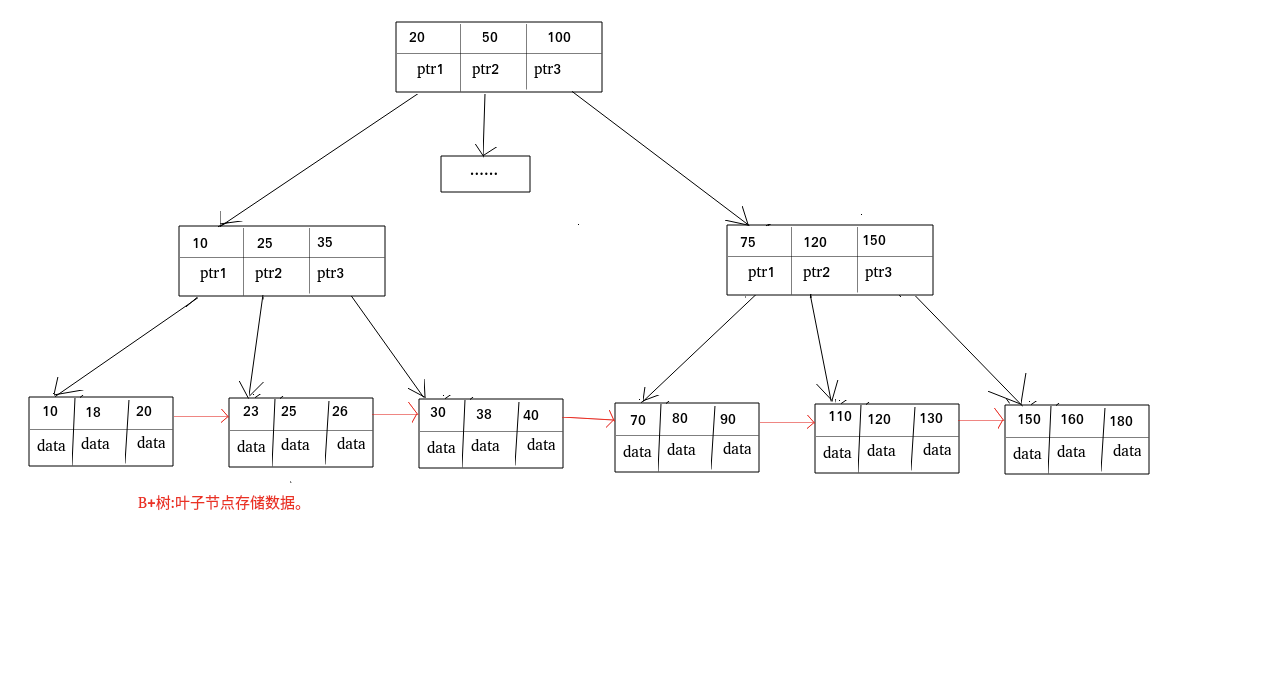
索引类型
主键索引
数据表的主键列用的是主键索引
没有表明主键时,InnoDB会自动检查是否唯一索引的字段,有则此字段为默认主键,没有则InnoDB会创建6Byte的自增主键
二级索引(辅助索引)
二级索引也被称为辅助索引,二级索引的叶子节点储存的是主键,所以可以通过二级索引找到主键的位置
- 唯一索引:唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引
- 普通索引:普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 前缀索引: 取字符串数据类型的前几个字符
- 全文索引:全文索引是为了检测大文本数据中关键字的信息
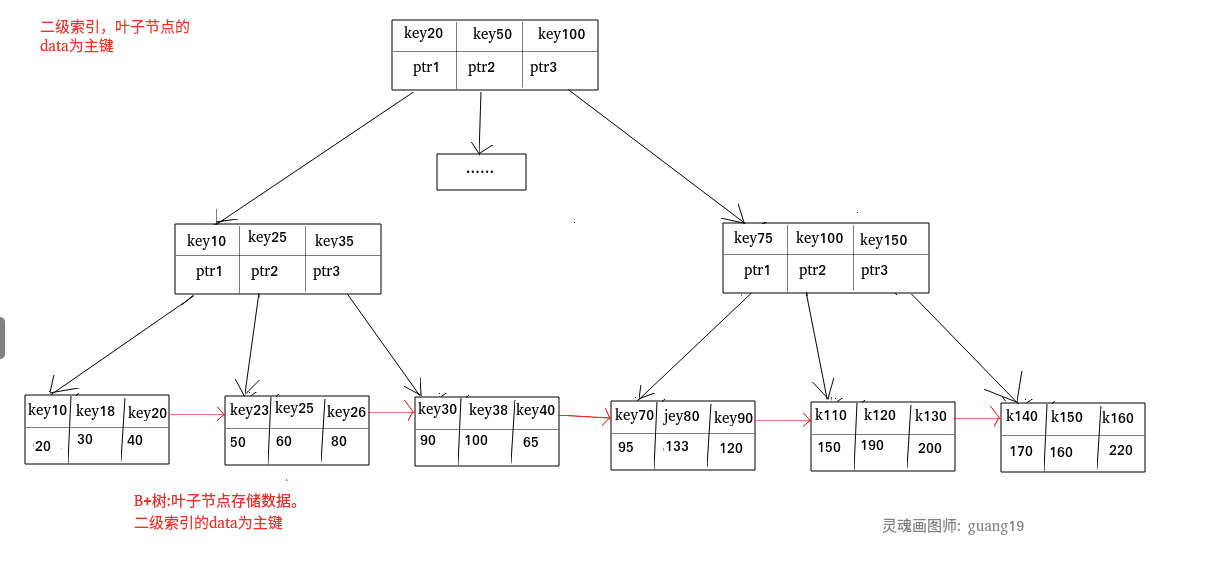
聚集索引与非聚集索引
聚集索引
聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引
优点:
查询速度快,因为B+是平衡树,叶子有序,所以容易定位
缺点:
1.依赖有序的数据:需要在插入时排序,对于字符串或者UUID型数据非常麻烦
2.更新代价大: 更新数据时,索引也会被更新
非聚集索引
二级索引属于非聚集索引。
MyISAM引擎的表.MYI文件包括表的索引, 该表的索引(B+树)的每个叶子非叶子节点存储索引, 叶子节点存储索引和索引对应数据的指针,指向.MYD 文件的数据。
优点:
更新代价小
缺点:
- 依赖有序数据
- 可能会二次查询
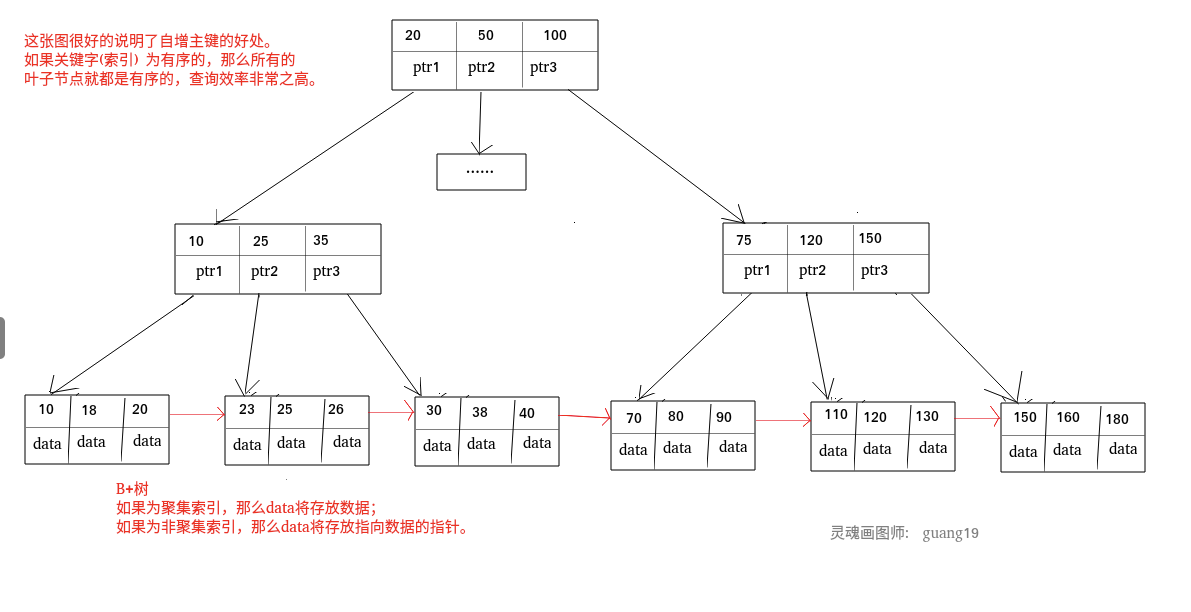
创建索引的注意事项
1.选择合适字段创建索引
- 不为 NULL 的字段
- 被频繁查询的字段
- 被作为条件查询的字段
- 频繁需要排序的字段
- 被经常用于连接的字段
2.被频繁更新的字段应该慎重建立索引
3.尽可能的考虑建立联合索引而不是单列索引
4.注意避免冗余索引
5.考虑在字符串类型的字段上使用前缀索引代替普通索引















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









