







正则表达式
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、 sed
等命令可以支持正则表达式。
通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp 这些命令不 支持
正则表达式,所以只能使用 shell 自己的通配符来进行匹配。
基础的正则表达式

grep 命令的使用
-c :表示打印符合要求的行数
-i:忽略大小写
-n:表示输出符合要求的行号
-v:打印不符合要求的行
-A:后跟一个数字表示打印符合要求的行及下面两行
-B:后跟一个数字表示打印符合要求的行及上面两行
-C :后跟一个数字表示打印符合要求的行及上下两行

过滤出带有某个关键词的行,并输出行号

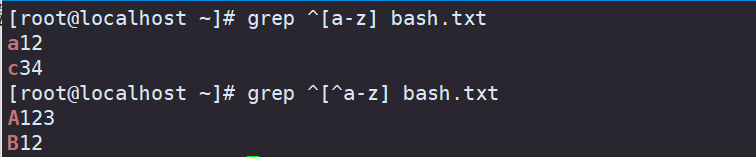
在正则表达式中^表示行首,$表示行尾,那么空行可以用^$表示
^[a-z] 表示匹配不用小写字母开头的行
 \{n\} 表示其前面的字符恰好出现n次
\{n\} 表示其前面的字符恰好出现n次

\{2,\} 表示其前面的字符出现不小于2次

\{1,2\} 表示其前面的字符 最少出现一个,最多出现2个

awk命令
截取文档的某个段
-F :指定分割符 如果不加-F选项,则以空格或者tab为分割符号
print为打印动作,用于打印某个字段,$1为第一个字段,$2为第二个字段。$0表示整行
注意awk的格式,-F后跟单引号,单引号里面为分隔符。print的动作要用括号括起来
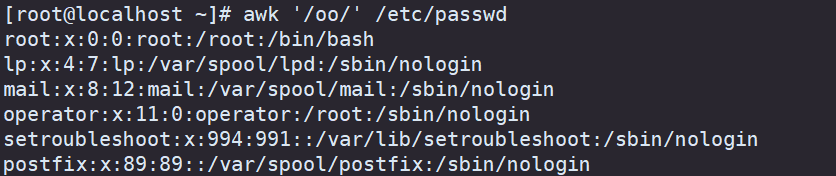
它可以让某个段去匹配 awk -F ‘:’ ‘$1 ~/oo/’ /etc/passwd 。 ~就是匹配的意思

awk 的内置变量
awk常用的变量有OFS 、NF和NR,NFOFS和-F选项有类似的功能,也就是来定义分隔符的,但是他是在输出的时候定义,NF表示用分隔符分割后一共有多少段,NR 表示行号

NF表示用分隔符分割后一共有多少段

sed 命令
sed 是一种几乎包括在所有 UNIX 平台( 包括 Linux)的轻量级流编辑器。sed 主要 是用
来将数据进行选取、替换、删除、新增的命令。
-n :显示要打印的行
-p:打印

打印包含某个字符串的行

-e :加上该选项可以实现多个行为

-d:删除某行 也可也‘1,2’

替换字符或者字符串 -s 选项 加上-g表示本行进行全局替换
当然除了使用/作为分隔符还可以使用其他的特殊字符

删除文档中的所有数字

删除文档中的英文
















 5031
5031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









