







文章目录
一、字符串及正则表达式
1.1字符串处理的相关方法
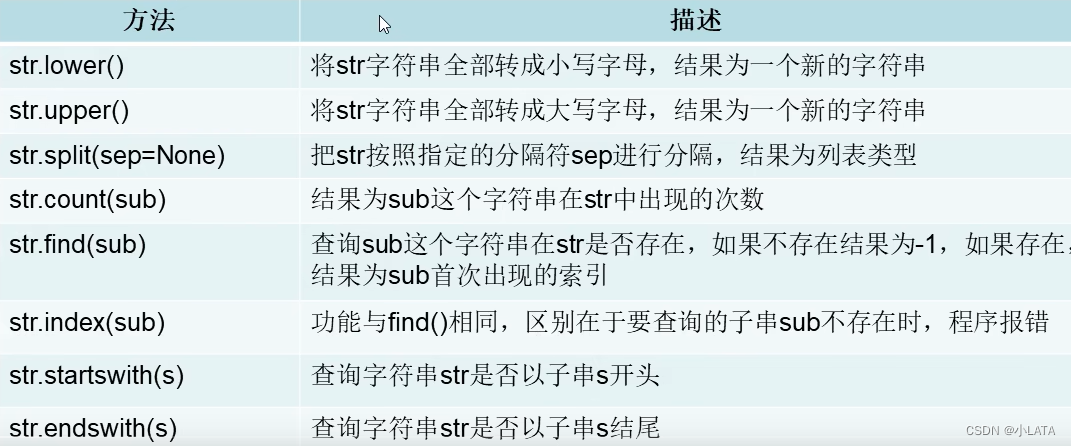
s_email = 'fwq@126.com'
lst = s_email.split('@')
print('邮箱名', lst[0], '邮件服务器域名', lst[1])

print(s.center(20))
print(s.center(20, '*'))
#去除字符串左右的空格
s = ' Hello World '
print(s.strip())
print(s.lstrip())
print(s.rstrip())
#去除指定字符
s = 'dl-HelloWorld'
print(s.strip('ld'))#输出 -HelloWor dl还是ld,与顺序无关,只要左右包含ld,就去掉
print(s.lstrip('ld'))
print(s.rstrip('ld'))
1.2格式化字符串
- 使用占位符格式化字符串
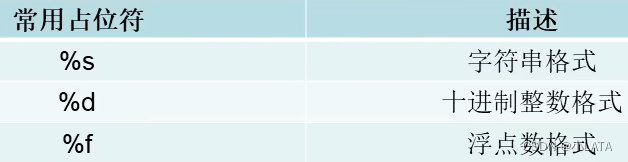
- f-string格式化字符串
以{}标明被替换的字段
- 字符串的format()方法

#1
name = '马冬梅'
age = 18
score = 98.5
print('姓名:%s, 年龄:%d, 成绩:%.1f' % (name,age,score))
#2
print(f'姓名:{name}, 年龄:{age}, 成绩:{score}')
#3 模板字符串.format(逗号分隔的参数)
print('姓名:{0},年龄:{1},成绩:{2}'.format(name,age,score))
print('姓名:{2},年龄:{0},成绩:{1}'.format(age,score,name))
s = 'helloworld'
print('{0:*<20}'.format(s))#字符串显示宽度20,左对齐,空白部分使用*填充
print('{0:*>20}'.format(s))#字符串显示宽度20,右对齐,空白部分使用*填充
print('{0:*^20}'.format(s))#字符串显示宽度20,居中对齐,空白部分使用*填充
print(s.center(20, '*'))#也可以实现居中的效果
#千位分隔符(只适用于整数和浮点数)
print('{0:,}'.format(9876542456))
print('{0:,}'.format(9876542456.976))
#浮点数小数部分的精度
print('{0:.2f}'.format(3.1415926))
#或者是字符串类型的最大显示长度
print('{0:.5}'.format('helloworld'))
#整数类型
a = 425
print('{0:b},{0:c},{0:d},{0:o},{0:x},{0:x},{0:X}'.format(a))
#浮点数类型
b = 3.1415926
print('{0:.2f},{0:.2E},{0:.2e},{0:.2%}'.format(b))
二、字符串的编码与解码
- 最早字符串编码是美国标准信息交换码,ASCII,最多可以表示256个符号,一个字符占一个字节
- 中文编码
-GBK:我国制定的编码标准,英文占一个字节,中文占两个字节
-GB2312:我国制定的编码标准,英文占一个字节,中文占两个字节
-UTF-8:国际通用的编码,英文占一个字节,中文占三个字节
Python中常用的两种字符串类型:
-str类型:表示Unicode字符(ASCII和其他字符)
-bytes类型:表示二进制数据(包括编码的文本)
- 字符串的编码:str–>bytes
str.encode(encoding='utf-8',errors='strict/ignore/replace')#默认utf-8
- 字符串的解码:bytes–>str
bytes.decode(encoding='utf-8',errors='strict/ignore/replace')
s = '开心'
scode_gbk = s.encode('gbk', errors='ignore')
print(bytes.decode(scode_gbk, 'gbk'))
三、数据的验证和处理
3.1数据的验证
对用户输入的数据进行“合法”性验证
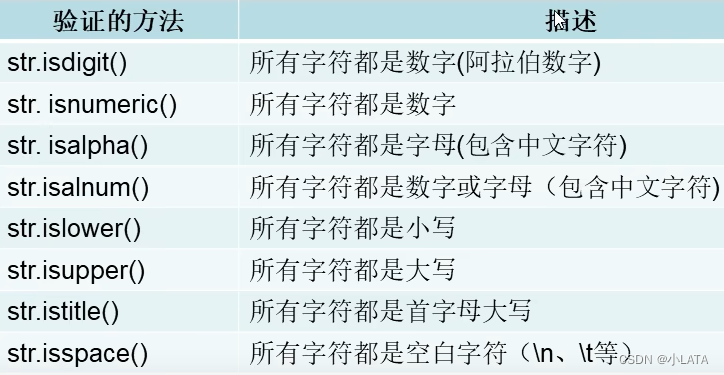
str.isnumeric()#所有字符都是数字:阿拉伯数字、罗马数字、中文数字
print('1234'.isnumeric())#True
print('一二三四'.isnumeric())#True
print('|||||'.isnumeric())#True
print('壹贰叁'.isnumeric())#True
print('0b1001'.isnumeric())#False
str.istitle()#每个单词只有首字母大写,返回True
3.2数据的处理
- 字符串的拼接
使用“+”进行拼接字符串
使用str.join()方法进行拼接字符串
直接拼接
使用格式化字符串进行拼接
s1 = 'hello'
s2 = 'world'
#1.使用+进行哦拼接
print(s1+s2)
#2.使用join方法
print(''.join(['hello','world']))#输出helloworld
print('*'.join(['hello','world','java']))#输出hello*world*java
#3.直接拼接
print('hello''world')
#4.使用格式化字符串拼接
print('%s%s' % (s1,s2))
print(f'{s1}{s2}')
print('{0}{1}'.format(s1,s2))
- 字符串去重
#1.字符串拼接+not in
new_s = ''
for item in s:
if item not in new_s:
new_s += item
print(new_s)
#2.使用索引+not in
new_s2 = ''
for i in range(len(s)):
if s[i] not in new_s2:
new_s2 +=s[i]
print(new_s2)
#3.通过集合去重+列表排序
new_s3 = set(s)
lst = list(new_s3)
lst.sort(key=s.index)#排序的关键字
print(''.join(lst))
- 列表元素去重
lst = ['金星','木星','火星','水星','金星','木星','火星','水星','金星','木星','火星','水星','金星','木星','火星','水星']
new_lst = []
#1.for循环+not in
for item in lst:
if item not in new_lst:
new_lst.append(item)
print(new_lst)
#2.索引+not in
new_lst2 = []
for item in range(len(lst)):
if lst[i] not in new_lst2:
new_lst2.append(item)
print(new_lst2)
#3.集合去重
s_lst = set(lst)
new_lst3 = list(s_lst)
new_lst3.sort(key=lst.index)
print(new_lst3)
四、正则表达式
正则表达式是一个特殊的字符序列,它能够帮助用户便捷地检查一个字符串是否符合某种规则(模式)
-
元字符:
·具有特殊意义地专用字符
·用来描述字符串地边界的元字符
·开始“^”
·结尾“$”

-
限定符:用于限定匹配的次数
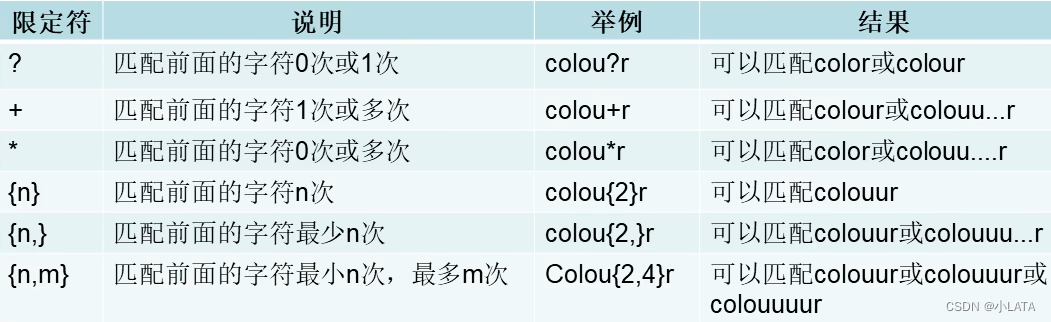
-
其他字符
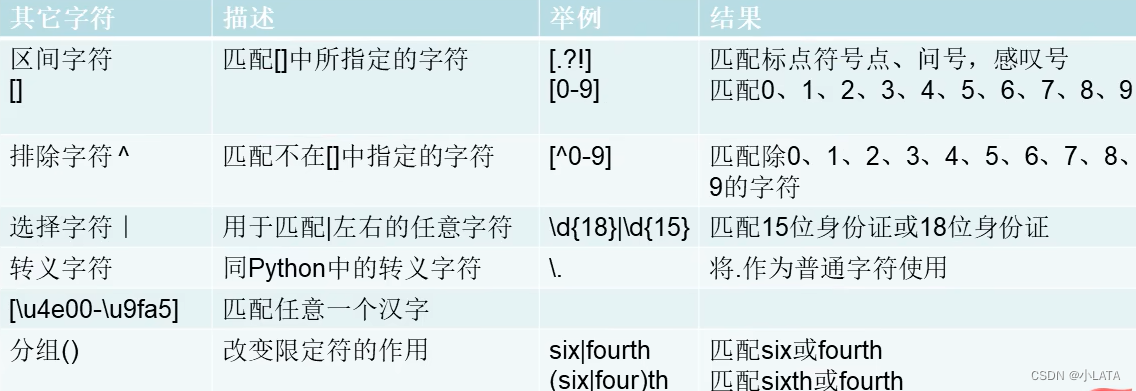
4.1、内置模块re
re模块:用于实现Python中的正则表达式的操作,是Python中的内置模块,导入即可使用
- re.match()方法:用于从字符串的开始位置进行匹配,如果起始位置匹配成功,结果为Match对象,否则结果为None
re.match(pattern,string,flags=0)
import re
pattern = r'\d\.\d+'
s = 'I study Python3.10 every day'
match = re.match(pattern,s,re.I)#I表示不区分大小写
print(match)#None
s2 = '3.10Python I study every day'
match2 = re.match(pattern,s2,re.I)#I表示不区分大小写
print(match2)#<re.Match object; span=(0,4),match='3.10'>
print('匹配值的起始位置:',match2.start())
print('匹配值的结束位置:',match2.end())
print('匹配值区间的位置元组:',match2.span())
print('待匹配的字符串:',match2.string)
print('匹配数据:',match2.group())
- re.search()方法:用于在整个字符串中搜索第一个匹配的值,如果匹配成功,如果为match对象,否则结果为None
re.search(pattern,string,flags=0)
import re
pattern = r'\d\.\d+'
s = 'I study Python3.10 every day Python2.10 I love you'
s2 = '4.10Python I study every day'
s3 = 'I study Python every day'
match = re.search(pattern,s)
match2 = re.search(pattern,s2)
match3 = re.search(pattern,s3)
print(match)#
print(match2)#
print(match3)#None
- re.findcall()方法:用于在整个字符串中搜索所有符合正则表达式的值,结果为列表
re.findcall(pattern,string,flags=0)
import re
pattern = r'\d\.\d+'
s = 'I study Python3.10 every day Python2.10 I love you'
s2 = '4.10Python I study every day'
s3 = 'I study Python every day'
lst= re.search(pattern,s)
lst2 = re.search(pattern,s2)
lst3 = re.search(pattern,s3)
print(lst)#['3.10','2.10']
print(lst2)#['4.10']
print(lst3)#[]
- re.sub()方法:用于实现字符串的替换
re.sub(pattern,repl,string,count,flags=0)
import re
pattern = '黑客|破解|反爬'
s = '我想学习Python,想破解一些VIP视频,Python可以实现无底线反爬吗?'
new_s = re.sub(pattern,'XXX',s)
print(new_s)
- re.split()方法:功能与字符串的split方法相同
re.split(pattern,string,maxsplit,flags=0)
import re
s2 = 'https://www.bilibili.com/video/BV1qt4y1T7M2?p=107&vd_source=c86bbed57675b3806c0f3c8a28ef7697'
pattern2 = '[?|&]'
lst = re.split(pattern2,s2)
print(lst)
五、实战——车牌归属地
lst = ['京A8888', '津B66666', '吉A77766']
for item in lst:
area = item[0:1]
print(item, '归属地', area)
六、实战——统计字符串指定字符出现次数
s = 'HelloPython,HelloJava,hellophp'
word = input('请输入要统计的字符:')
print('{0}在{1}中一个出现了{2}次'.format(word, s, s.upper().count(word)))
七、实战——格式化输出商品的名称和单价
lst = [
['01', '电风扇', '美的', 500],
['02', '洗衣机', 'TCL', 1000],
['03', '微波炉', '老板', 400]
]
print('编号\t\t名称\t\t品牌\t\t单价')
for item in lst:
for i in item:
print(i, end='\t\t')
print()
for item in lst:
item[0] = '0000' + item[0]
item[3] = '¥{:.2f}'.format(item[3])
print('-------------------------------------------')
print('编号\t\t\t名称\t\t\t品牌\t\t单价')
for item in lst:
for i in item:
print(i, end='\t\t')
print()














 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









