







跟着Cherno学习C++(三)——基础语法2
文章目录
前言
平台:Visual Studio 2022
Cherno主页地址:youtube.com/@TheCherno
B站视频搬运up主:@神经元猫
个人微信:SWPUZHH 欢迎进群交流,一起学习~~
Hello~ every guys,从现在开始,让我们跟着Cherno的教程一步一步的开始学习C++
本期我们来看一下C++中的类相关的概念,由此进入面向对象的编程范式
C++中的类
类是一种用户定义的数据类型,它允许将数据和操作这些数据的函数捆绑在一起。类是面向对象编程(OOP)的核心概念之一,它提供了一种封装数据和相关操作的方式,支持数据抽象、继承和多态等特性。
简单来说,我们有一堆变量和一堆方法,我们定义一个类来包含他们,使得编程更加容易。不用类能解决的问题,用类也无法解决。
举个例子,在游戏中我们会有很多对象,我们有玩家Player这一种对象,他有x,y坐标属性,我们可能像下面一样定义
int main()
{
// 定义player1的位置
int x1 = 2;
int y1 = 4;
//定义player2的位置
int x2 = 4;
int y2 = 5;
}
对于每一个player我们都会去单独创建表示它们属性的变量,当player多的时候,代码就会非常杂乱,所以我们就可以利用类来简化这一切
class player()
{
public:
int x,y;
}
int main()
{
player A;
A.x = 2;
A.y = 4
player B;
B.x = 4
B.y = 5
}
类中的变量和方法默认是private,我们可以指定为public
类class和结构体Struct的区别
在C++中,class和struct其实并没有本质的区别,唯一的区别是class的成员默认是private,而struct里面默认是public
之所以还有struct是为了和C兼容,C中并没有class,当然我们也有其他的方式来兼容,比如#define struct class等
每个人对于struct和class的使用场景,比如什么时候使用struct,什么时候使用class,这取决于编程风格。
比如我的编程风格,当讨论(plain old data)时(普通旧数据)(可以理解与C兼容,我一般使用struct,而当创建特定属性(成员变量)和行为(成员函数)的实体时,我通常会选择使用类(class),即class表示的对象和它的成员变量或者成员函数具有实际意义,比如运动员这个对象有国际,年龄,特长,荣誉等等有实际意义的时候,我往往会使用class。
当然,以上都只是编程风格,Class和Struct从技术上讲并没有本质区别,只在默认可见度上存在一点小区别,我们在选择使用class或者struce并不会因为可见度的区别而选择某种,我们一般是根据各自的编程风格来决定。
POD类型的定义
- 只包含标量类型(如整数、浮点数、指针等)或者其他 POD 类型的成员。
- 没有用户自定义的构造函数、析构函数或拷贝控制成员
- 没有虚函数或虚继承
- 可以通过
memset和memcpy进行内存的简单复制和初始化。这些标准在 C++03 标准中被定义。根据这个定义,POD 类型可以被视为简单的、平凡的数据类型,可以进行一些底层的操作,如内存复制、比较和序列化等。POD 类型通常用于与 C 语言进行交互、进行低级别的内存操作或进行数据序列化和传输。
C++ 中的static
static 关键字有多种用途,它用在不同的上下文中,具有不同的含义。可以分为三种情况,class和struct中的static;class和struct外的static;Local Static局部静态
Class和Struct外的Static
在一个.cpp文件中,我们可以声明一个static变量或者static函数,这表示将它们局限在这一个翻译单元中,
//main.cpp
#include <iostream>
int s_variable = 10;
int main()
{
std::cout << s_variable << std::endl;
std::cin.get();
}
//static.cpp
int s_variable = 5;
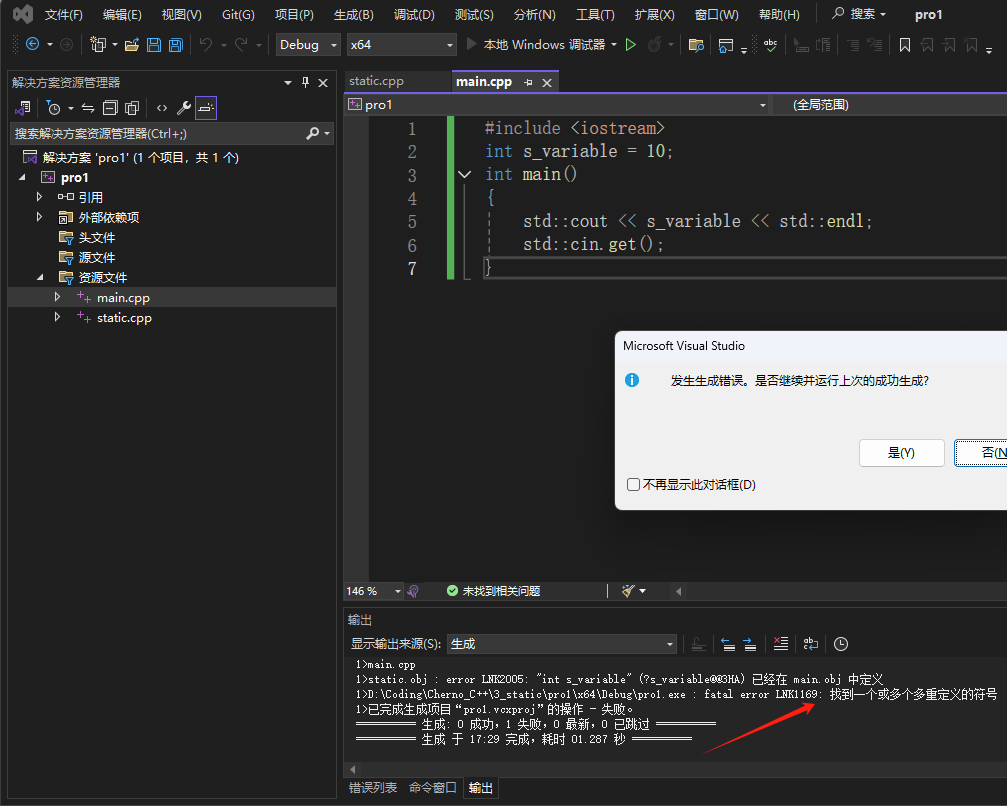
运行上述代码,会在链接阶段出错,s_variable出现多重定义,main.cpp和static.cpp两个翻译单元都有s_variable的定义,当使用s_variable的时候链接器就不知道要使用哪个而报错,此时我们在为main.cpp中的s_variable添加static关键词,便可编译通过。
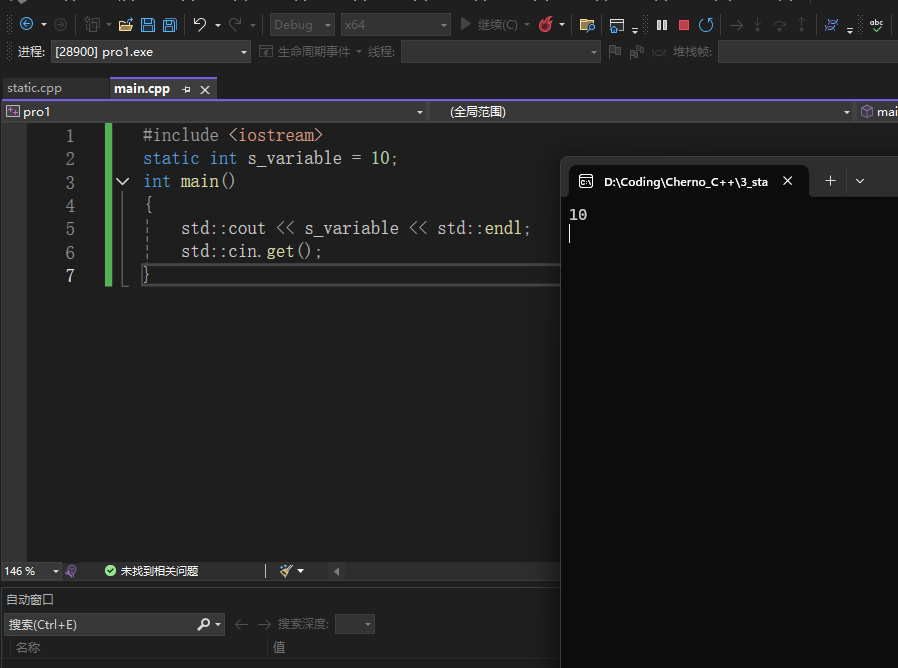
此时static的含义是将s_variuabel只限定在main.cpp一个翻译单元里面,当使用它时,只会在main.cpp这一个翻译单元中去寻找链接
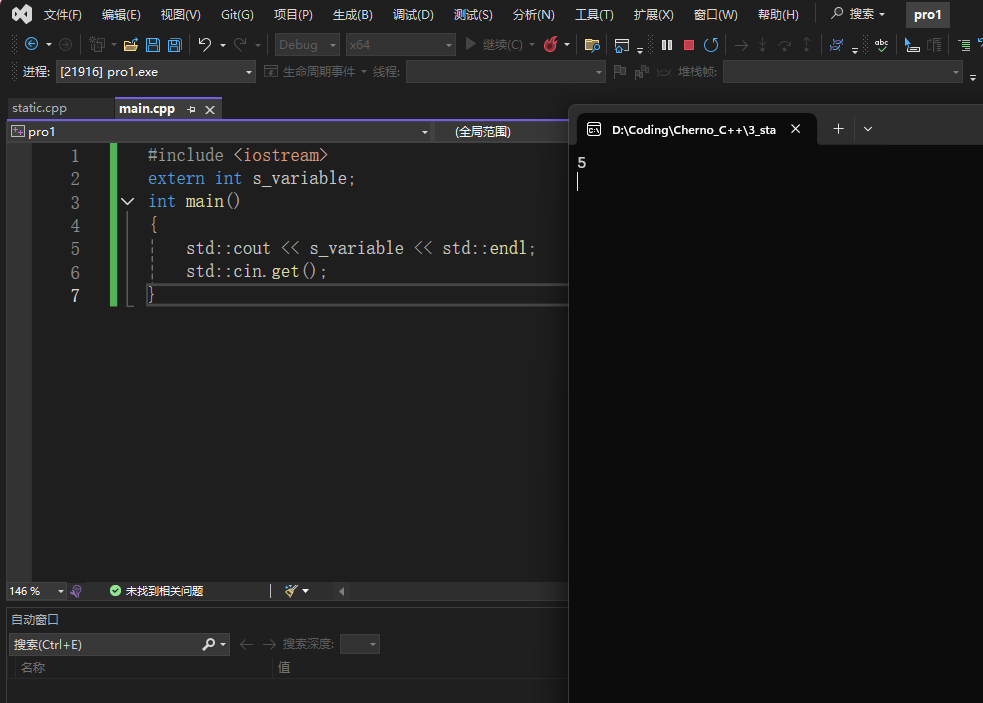
或者我们也可以使用extern关键词,意思是我们从外部翻译单元中去寻找s_variable,可以看到此时的输出为static中定义的5
对于函数也是同样的道理。
总结一下:在类或者结构体外使用static,它的作用是将该变量或者函数限定在这一个翻译单元中,确保链接的时候不会出现多重定义错误。
Class和Struct中的Static
Class和Struct中的static
如果和变量一起使用,意味着在类的所有实例中,这个变量只有一个实例
如果和函数一起使用,不用通过类的实例便可以调用该静态方法,静态方法只能操作静态变量,但是可以利用指针操纵实例的变量
当我们在class或者stuct前添加static,意味着我们定义了一个静态类或者静态结构体
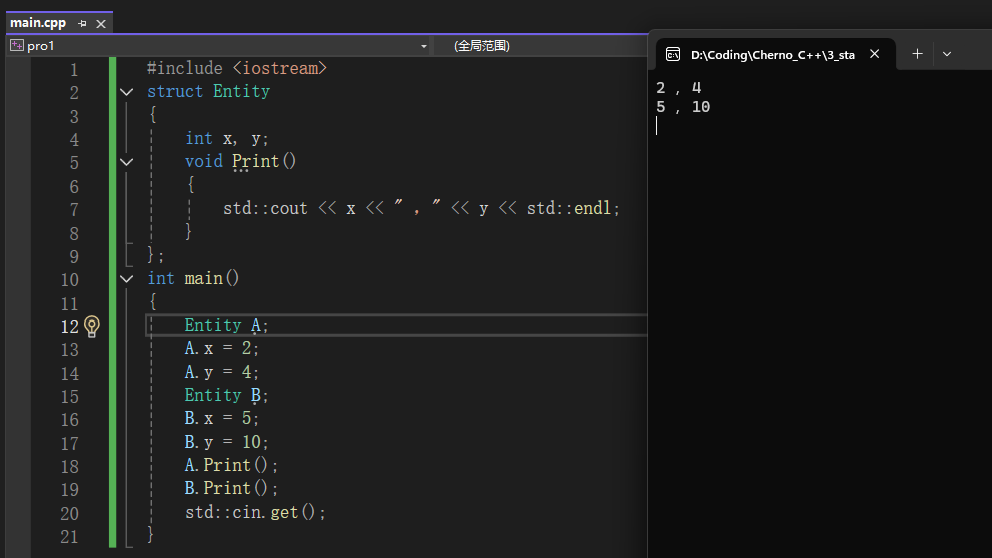
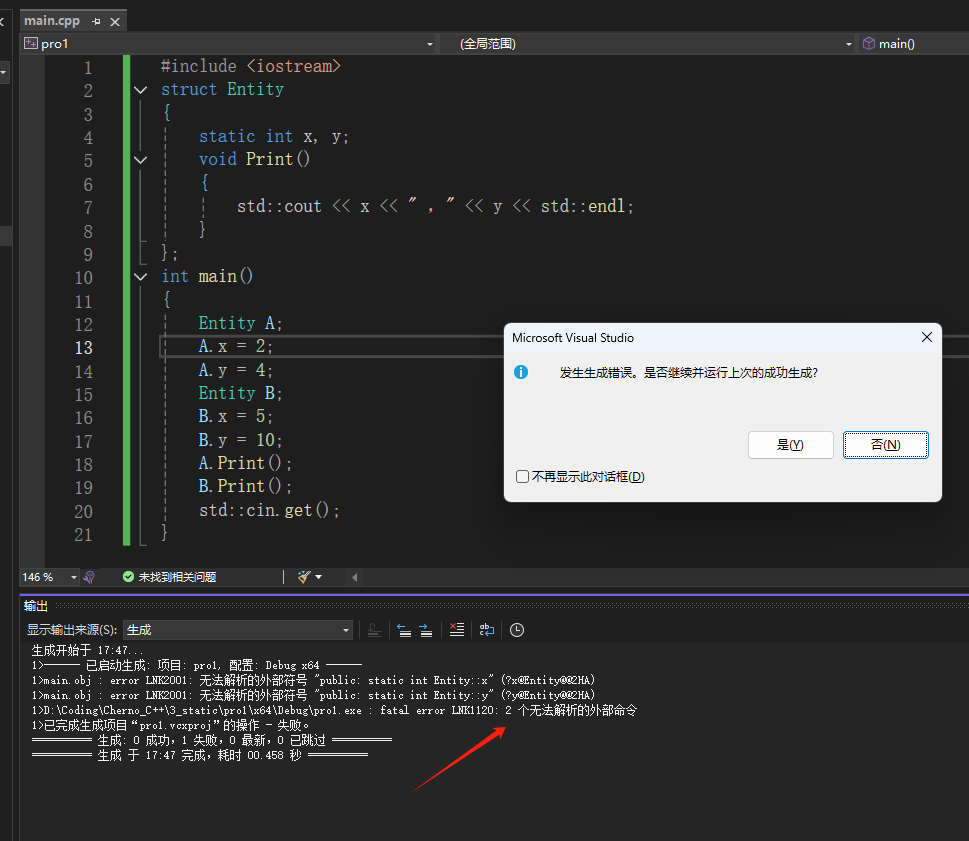
当我们将x,y设置为静态的时候,我们也需要单独声明这些静态变量,不然就会像上图一样报错
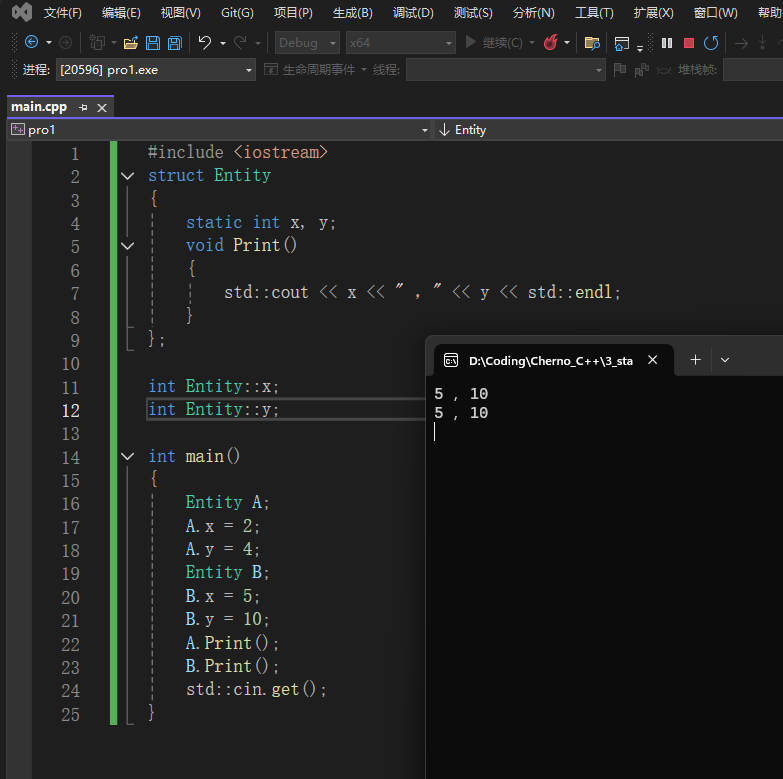
在这个时刻,我们观察到 A.Print() 和 B.Print() 都返回了相同的结果:5 和 10。这一现象证实了静态成员变量是被所有实例共同继承的,它们存储在共享内存区域中。
虽然我们可以通过使用传统的全局变量来实现类似的效果,但我们选择使用“实例级全局变量”,这是因为将 x 和 y 封装在 Entity 类中更具有实际意义,它们与 Entity 类的属性紧密相关,而不是与全局上下文相关。这样的封装不仅增强了代码的可读性和维护性,还有助于保持数据的封装性和逻辑的一致性。
下面让我们来看一看静态成员函数
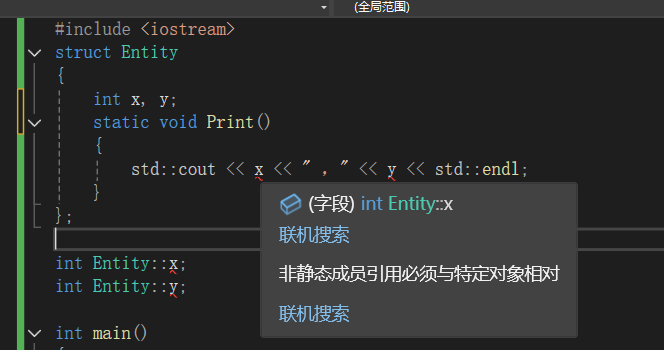
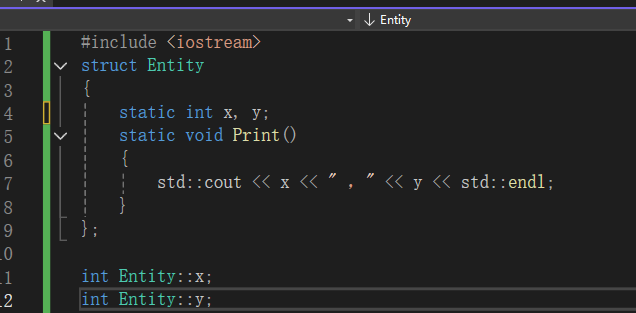
静态成员函数不属于某个实例,所以它不知道要找那个实例对应的x,y便会报错,(但是我们可以给他传入实例的引用,从而利用指针来操作实例对应的变量,比如this指针等)它只能操纵静态成员变量
总结一下:static对于静态数据非常有用,它来保证这些数据在不同实例之间保持一致(共享)
局部静态Local Static
声明一个变量,我们需要考虑两种情况,一个生命周期,二是作用域,生命周期是变量存在的时间,在它被删除之前,它会在内存中存在多久,变量的作用域指的是我们可以访问变量的范围。
如果在一个函数内部声明一个变量,我们不能在其他的函数中访问它,这些变量对于我们声明的函数是局部的。
静态局部(local static)变量允许我们声明一个变量,它的生命周期相当于整个程序的生存期,但是它的作用域会被限制在这个函数内。
//在这个例子中,我们只会输出1
#include <iostream>
void Function()
{
int i = 0;
i++;
std::cout << i << std::endl;
}
int main()
{
Function();
Function();
Function();
Function();
Function();
std::cin.get();
}

//这个例子中,我们给i加上static,输出便会编程1,2,3,4,5
#include <iostream>
void Function()
{
static int i = 0;
i++;
std::cout << i << std::endl;
}
int main()
{
Function();
Function();
Function();
Function();
Function();
std::cin.get();
}
局部静态可以简化我们的代码,即使很多人并不愿意使用它,下面是单例函数的例子
// 不使用local static
#include <iostream>
class Singleton
{
private:
static Singleton* s_Instance;
public:
static Singleton& Get() { return *s_Instance };
void Hello() {};
};
Singleton* Singleton::s_Instance = nullptr;
int main()
{
Singleton::Get().Hello();
std::cin.get();
}
// 使用local static 效果一样 代码更加简洁
#include <iostream>
class Singleton
{
public:
static Singleton& Get()
{
static Singleton* s_Instance;
return *s_Instance;
};
void Hello() {};
};
int main()
{
Singleton::Get().Hello();
std::cin.get();
}
C++中的枚举
在 C++ 中,枚举(Enumeration)是一种用户定义的数据类型,它允许为一组相关的值定义一个名字。枚举提供了一种更加清晰和安全的方式来处理一组常量,相比于直接使用整数或字符串,枚举使得代码更加易于理解和维护。
枚举中默认第一个值为0,后续递增,当然我们也可以自己指定每个值
枚举的值只能是整数,如果我们觉得使用int 4个字节比较浪费空间,我们也可以使指定为char,
enum Color:unsigned char
{
RED=0, GREEN, BLUE
}
枚举的两种类型
- 普通枚举(Unscoped Enumeration): 普通枚举是 C++ 中较早的形式,它在定义时不指定枚举的类型名。cpp
enum Color { RED, GREEN, BLUE };
int main() {
Color c = RED;
// ...
}
在这种形式中,枚举的成员(如 RED, GREEN, BLUE)是全局可见的,这意味着它们可以在枚举类型外部直接访问。
- 强类型枚举(Scoped Enumeration): C++11 引入了强类型枚举,它使用
enum class或enum struct关键字定义。这种枚举的成员不是全局可见的,而是被封装在枚举类型内部。cpp
enum class Color { RED, GREEN, BLUE };
int main() {
Color c = Color::RED;
// ...
}
在这种形式中,要访问枚举成员,必须使用枚举类型名作为限定符(如 Color::RED)
构造函数
构造函数用于在创建对象时初始化对象,每当我们实例化对象的时候,它会自动调用构造函数。
C++不想java等语言会帮助我们初始化基本变量(int,float等),C++中的所有变量都需要我们手动去初始化,,否则它们将被设置为留在该内存的其他值。
构造函数保证了我们在实例化对象的时候,对所有内存进行了初始化。
默认构造函数为空,类似下面
class Entity()
{
public:
Entity(){}
}
当然我们也可以隐藏构造函数,通过设置为private或者删除
- 防止对象的默认创建:如果不希望类有任何默认构造的行为,可以删除默认构造函数。
- 实现设计意图:如果类的设计意图是只能通过特定方式创建对象(例如,只能通过工厂方法或单例模式),则可以删除构造函数以防止直接实例化
class Entity()
{
private:
Entity(){}
}
or
class Entity()
{
Entity() = delete;
}
其他的还有拷贝构造函数和移动构造函数,我们将在后续讨论,感兴趣的小伙伴可以搜索一下。
析构函数
当实例被销毁时会自动调用析构函数
析构函数通常是为了释放内存(通常是堆上的内存,栈中的内存会在实例销毁时自动退栈释放)
class Entity()
{
public:
~ Entity(){}
}
C++的继承
继承是一种面向对象编程的核心概念,它允许一个类(称为派生类或子类)继承另一个类(称为基类或父类)的属性和方法。继承支持代码重用,并提供了一种组织代码的层次结构。
C++ 支持多重继承,即一个派生类可以继承多个基类
class Base1 {
public:
Base1() { std::cout << "Base1 constructor\n"; }
~Base1() { std::cout << "Base1 destructor\n"; }
};
class Base2 {
public:
Base2() { std::cout << "Base2 constructor\n"; }
~Base2() { std::cout << "Base2 destructor\n"; }
};
class Derived : public Base1, public Base2 {
public:
Derived() { std::cout << "Derived constructor\n"; }
~Derived() { std::cout << "Derived destructor\n"; }
};
int main() {
Derived d;
// 构造输出顺序:Base1 constructor, Base2 constructor, Derived constructor
// 析构顺序:Derived destructor, Base2 destructor, Base1 destructor
return 0;
}
C++中的多态
多态允许我们以一种统一的方式处理不同类型的对象。多态性使得同一个操作可以作用于不同的对象,而具体执行哪个操作则取决于对象的实际类型。
C++ 中的多态主要有两种形式:
- 编译时多态(静态多态):
- 函数重载:同一个作用域内,相同函数名但参数类型或数量不同的函数可以共存。
- 运算符重载:为已有的运算符提供新的操作数类型,从而改变其行为。
- 运行时多态(动态多态):
- 虚函数:基类中声明为
virtual的函数可以在派生类中被重写,通过基类指针或引用调用时,会根据对象的实际类型动态绑定到相应的函数。
- 虚函数:基类中声明为
C++中的虚函数
class Base {
public:
virtual void func() {
std::cout << "Base::func()" << std::endl;
}
virtual ~Base() {}
};
class Derived : public Base {
public:
void func() override { // 使用 override 关键字
std::cout << "Derived::func()" << std::endl;
}
};
int main() {
Base* b = new Derived();
b->func(); // 输出 "Derived::func()"
delete b;
return 0;
}
在这个例子中,Derived 类重写了 Base 类的 func() 虚函数,并使用了 override 关键字。通过基类指针 b 调用 func() 时,将调用 Derived 类中的版本。
override关键字用于明确指出一个函数是重写基类中的虚函数。这不是必须的,但它提高了代码的可读性,并且编译器可以利用它来检查重写是否正确,如果一个函数被错误地标记为override,但并没有重写任何基类中的虚函数,编译器将会报错。这有助于预防因拼写错误或其他原因导致的意外行为。C++11之后有的override- 每个具有虚函数的类都需要一个虚函数表,并且每个对象都包含一个指向该表的指针,调用虚函数时,需要通过虚函数表进行间接调用,这比直接调用非虚函数稍微慢一些。(实际影响很小,可能低级嵌入式中会有影响)
C++中的纯虚函数(接口 interfence)
纯虚函数允许我们在基类中定义一个没有实现的函数,然后强制子类去实现该函数,此时基类不再有实例化的能力。
这在其他语言中可能叫做接口,但是C++中没有interfence这个关键字
class Shape {
public:
virtual void draw() = 0; // 纯虚函数
virtual ~Shape() {} // 虚析构函数
};
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









