






Linux内核双向链表思想
Linux双向链表简介
Linux 内核双向链表其实是双向循环链表,它使用了面向对象的思想,内核提供一个基类,然后由我们来继承这个基类,进行内容的拓展。那么对于内核来说,只需要提供最简单地链表指向信息,并只用维护这个最简单的链表。
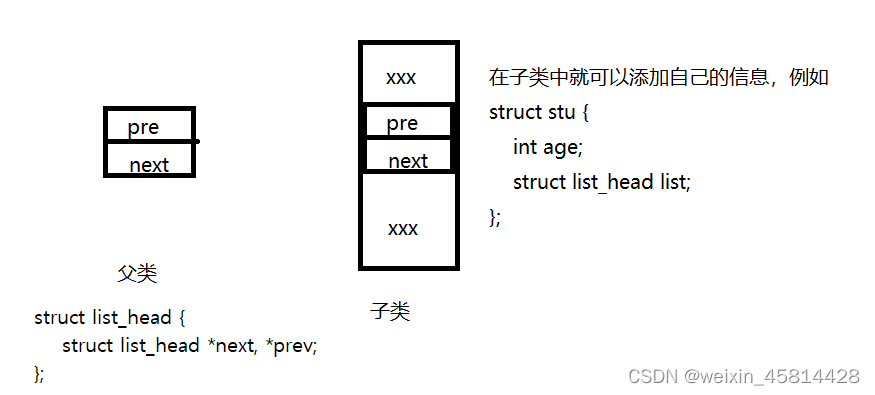 构建双向循环链表
构建双向循环链表
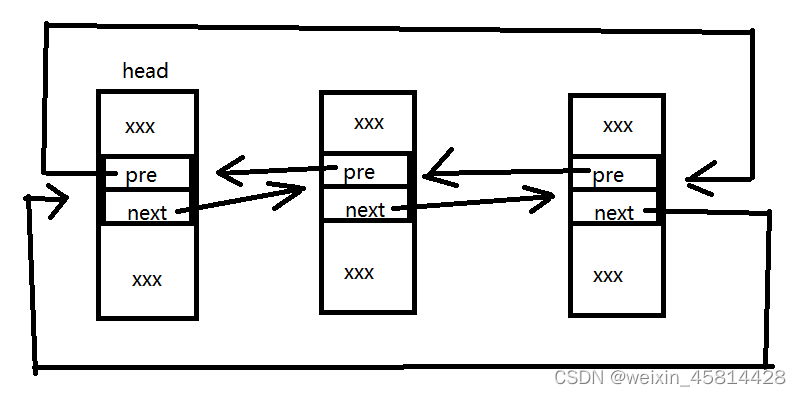
通过子类找父类
我们要操作链表,肯定需要知道我们定义的结构体的地址,但是内核只知道父类节点的地址,它是怎么通过父类节点的地址找到子类节点的呢?
这主要是通过内核中定义的两个宏。(内核双向链表源码在内核源码目录 include/linux/list.h 中)
#define offsetof(TYPE, MEMBER) ((size_t) & ((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
看起来很复杂,其实理解起来很简单,先说说 offsetof(TYPE, MEMBER)
- 第一个参数是我们自定义结构体的名字,如第一张图的 struct stu
- 第二个参数是我们自定义结构体中父类的变量名,如第一张图的 list
也很好理解,就是找到 MEMBER 在 TYPE 中的偏移量
- 首先,(TYPE *)0 把零地址转换成 TYPE 类型
- 然后 (TYPE *)0)->MEMBER 就是访问结构体下的 MEMBER 成员
- & 符号是取地址符号,就是取出 TYPE 结构体下 MEMBER 成员的地址,因为结构体的基地址是 0,所以 MEMBER 成员的地址就相当于是其在整个结构体中的偏移量
- size_t 就是转换类型
在第一张图的例子中
struct list_head {
struct list_head *next, *prev;
};
struct stu {
int age;
struct list_head list;
};
那么 offsetof(struct stu, list) 就应该等于 4,因为 list 成员相对于整个结构体偏移量是一个 int 类型,也就是 4 字节
接下来看看 container_of
先来看看参数
- ptr 就是父类的地址
- type 就是自定义结构体的类型
- member 是自定义结构体中父类成员的成员名
对于其内容
- const typeof( ((type *)0)->member ) *__mptr = (ptr); 就相当于定义一个父类类型的指针,并且指向 ptr
- (type *)( (char *)__mptr - offsetof(type,member) );}) offsetof 得到父类成员的偏移量,mptr 是某个子类节点中父类成员的地址,父类成员地址减去偏移量,就得到了子类节点的地址
总之,通过 container_of 宏,就能得到我们想要得到的自定义的结构体类型的地址
优点
通过这种双向链表的思想,我们对链表的增删改查的遍历操作,相当于在对父类节点进行操作,就不需要对子节点进行操作
当需要设计多个结构体时,就不需要对每一个结构体设计一套增删改查操作
例如,有学生结构体和老师结构体时,如果我们按照以往的思路,设计两个结构体,那么需要对每两个结构体的增删改查都要设计函数
但是,当使用面向对象的思想时,我们通过继承父类来创建学生和老师结构体,只需要一套增删改查的函数即可,因为,对整个链表的增删改查操作,实际上都是对父类节点的操作,并没有通过子类来指向
当有很多个结构体时,这种思想就可以大大减少工作量
实例
接下来,看一个实例
这里是把内核中的 list.h 文件拿出来,把内核相关的东西删除掉,就可以在应用层使用内核的双向链表了
list.h
#ifndef K_LIST_X_LIST_H
#define K_LIST_X_LIST_H
/**
* 双向循环链表的节点结构
*/
struct list_head {
struct list_head *next, *prev;
};
/**
* INIT_LIST_HEAD - 初始化双向循环链表头信息
* @list: 链表头节点
* 传递用户自定义结构中链表数据成员
* */
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = NULL;
entry->prev = NULL;
}
#define offsetof(TYPE, MEMBER) ((size_t) & ((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
&pos->member != (head); \
pos = list_next_entry(pos, member))
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#endif //K_LIST_X_LIST_H
这里再对头文件里的函数和宏进行一个说明。增删就不多说了,这里讲一下遍历。通常使用的变量方法有两个
- list_for_each 就相当于遍历的是父类成员,需要自己调用 container_of 获得子节点
- list_for_each_entry 就是直接遍历的子类节点,可以直接操作子节点
main.c
#include <stdio.h>
#include <stdlib.h>
#include "xlist.h"
struct stu {
int age;
struct list_head list;
};
struct stu stu_head; //头结点(不存储数据)
int main()
{
struct stu *p;
struct list_head *find; //父节点遍历指针
// 初始化头结点
INIT_LIST_HEAD(&stu_head.list);
stu_head.age = 0;
//插入5个数据,使用头插法,类似于栈
for (int i = 0; i < 5; i++) {
p = (struct stu *)malloc(sizeof(struct stu));
p->age = 10 + i;
list_add(&p->list, &stu_head.list);
}
//通过父节点遍历链表
list_for_each(find, &stu_head.list) {
p = container_of(find, struct stu, list); //通过父节点找到子节点
printf("age is : %d\n", p->age);
if (p->age == 13) { //遍历到第三个退出训循环
break;
}
}
// 删除第三个节点
list_del(&p->list);
//释放空间
free(p);
p = NULL;
printf("----------------\n");
//直接遍历子节点
list_for_each_entry(p, &stu_head.list, list) {
printf("the stu age is : %d\n", p->age);
}
return 0;
}
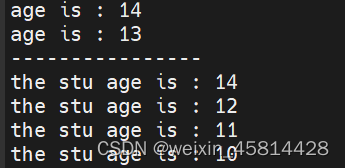
运行结果















 1068
1068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









