






文章目录
集合框架2
03 关系与区别
3.1 Arraylist vs HashSet
(1)是否有顺序
- ArrayList: 有顺序
- HashSet: 无顺序
(2)能否重复
- List中的数据可以重复
- Set中的数据不能够重复
重复判断标准是:
首先看hashcode是否相同
如果hashcode不同,则认为是不同数据
如果hashcode相同,再比较equals,如果equals相同,则是相同数据,否则是不同数据
(3)练习-不重复的随机数
生成50个 0-9999之间的随机数,要求不能有重复的。
package collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
public class TestCollection {
public static void main(String[] args) {
HashSet<Integer> hs=new HashSet<>();
while(hs.size()<50) {
hs.add((int)(Math.random()*10000));
}
System.out.printf("用HashSet得到%d个不重复的随机数%n",hs.size());
Object[] number=new Object[50];
number=hs.toArray();
for(int i=0;i<number.length;i++) {
System.out.print(number[i]+"\t");
if(9==i%10)
System.out.println();
}
List<Integer> numbers=new ArrayList<>();
getnum:
while(numbers.size()<50) {
int random=(int)(Math.random()*10000);
for(int i=0;i<numbers.size();i++) {
if(numbers.get(i)==random) {
continue getnum;
}
}
numbers.add(random);
}
System.out.printf("用ArrayList得到%d个不重复的随机数%n",numbers.size());
//System.out.println(numbers);
for(int i=0;i<numbers.size();i++) {
System.out.print(numbers.get(i)+"\t");
if(9==i%10)
System.out.println();
}
}
}

3.2 Arraylist vs LinkedList
ArrayList是顺序结构,定位很快。
LinkedList 是链表结构,插入、删除数据快。

(1)插入数据
- 在首位插入数据
package collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/*
*分别用ArrayList和LinkedList,在最前面插入1,000,000条数据,比较快慢
*/
public class TestArrayList {
public static void main(String[] args) {
// TODO Auto-generated method stub
//声明Integer类型容器integerGroup
List<Integer> integerGroup;
//初始化ArrayList,并调用insertFirst方法
integerGroup = new ArrayList<>();
insertFirst(integerGroup, "ArrayList");
//初始化LinkedList,并调用insertFirst方法
integerGroup = new LinkedList<>();
insertFirst(integerGroup, "LinkedList");
}
private static void insertFirst(List<Integer> iG, String type) {
int countInsert = 1000 * 100;
final int numberInsert = 5;
long timeStart = System.currentTimeMillis();
for (int i = 0; i < countInsert; i++) {
//调用List的方法:add(int index,Integer element),首位插入数据
iG.add(0, numberInsert);
}
long timeEnd = System.currentTimeMillis();
System.out.printf("在%s 最前面插入%d条数据,总共耗时 %d 毫秒 %n", type, countInsert, timeEnd - timeStart);
}
}
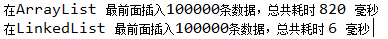
2. 在末位插入数据
package collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/*
*分别用ArrayList和LinkedList,在最后面插入1,000,000条数据,比较快慢
*/
public class TestArrayList {
public static void main(String[] args) {
// TODO Auto-generated method stub
//声明Integer类型容器integerGroup
List<Integer> integerGroup;
//初始化ArrayList,并调用insertFirst方法
integerGroup = new ArrayList<>();
insertFirst(integerGroup, "ArrayList");
//初始化LinkedList,并调用insertFirst方法
integerGroup = new LinkedList<>();
insertFirst(integerGroup, "LinkedList");
}
private static void insertFirst(List<Integer> iG, String type) {
int countInsert = 1000 * 100;
final int numberInsert = 5;
long timeStart = System.currentTimeMillis();
for (int i = 0; i < countInsert; i++) {
//调用List的方法:add(Integer element),末位插入数据
iG.add(numberInsert);
}
long timeEnd = System.currentTimeMillis();
System.out.printf("在%s 最后面插入%d条数据,总共耗时 %d 毫秒 %n", type, countInsert, timeEnd - timeStart);
}
}
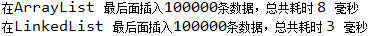
3. 在中间插入数据
package collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/*
*分别用ArrayList和LinkedList,在中间插入1,000,000条数据,比较快慢
*/
public class TestArrayList {
public static void main(String[] args) {
// TODO Auto-generated method stub
//声明Integer类型容器integerGroup
List<Integer> integerGroup;
//初始化ArrayList,并调用insertFirst方法
integerGroup = new ArrayList<>();
insertFirst(integerGroup, "ArrayList");
//初始化LinkedList,并调用insertFirst方法
integerGroup = new LinkedList<>();
insertFirst(integerGroup, "LinkedList");
}
private static void insertFirst(List<Integer> iG, String type) {
int countInsert = 1000 * 100;
final int numberInsert = 5;
long timeStart = System.currentTimeMillis();
for (int i = 0; i < countInsert; i++) {
//调用List的方法:add(int index,Integer element),中间插入数据
iG.add(iG.size()/2,numberInsert);
}
long timeEnd = System.currentTimeMillis();
System.out.printf("在%s 中间插入%d条数据,总共耗时 %d 毫秒 %n", type, countInsert, timeEnd - timeStart);
}
}
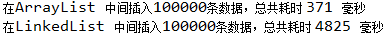
4. 定位数据
package collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/*
*分别用ArrayList和LinkedList,在最后面中间插入100,000条数据,并定位处理数据
*/
public class TestArrayList {
public static void main(String[] args) {
// TODO Auto-generated method stub
//声明Integer类型容器integerGroup
List<Integer> integerGroup;
//初始化ArrayList,并调用insertFirst方法获得size=100,000的容器,再调用locateData定位处理数据
integerGroup = new ArrayList<>();
insertFirst(integerGroup, "ArrayList");
locateData(integerGroup,50000, "ArrayList");
//初始化LinkedList,并调用insertFirst方法获得size=100,000的容器,再调用locateData定位处理数据
integerGroup = new LinkedList<>();
insertFirst(integerGroup, "LinkedList");
locateData(integerGroup,50000, "LinkedList");
}
private static void locateData(List<Integer>iG ,int indexOfLocation,String type) {
final int repeatTimes=100*1000;
long timeStart = System.currentTimeMillis();
for(int i=0;i<repeatTimes;i++) {
//remove和add方法
int temp=iG.remove(indexOfLocation);
iG.add(indexOfLocation, ++temp);
//get和set方法(输出结果是第二张图)ArrayList速度提升明显
//int temp=iG.get(indexOfLocation);
//iG.set(indexOfLocation, ++temp);
}
long timeEnd = System.currentTimeMillis();
System.out.printf("%s总长度是%d,定位到第%d个数据,取出来,加1,再放回去重复%d遍,总共耗时%d毫秒%n",
type,iG.size(),indexOfLocation,repeatTimes,timeEnd - timeStart);
}
private static void insertFirst(List<Integer> iG, String type) {
int countInsert = 1000 * 100;
final int numberInsert = 5;
long timeStart = System.currentTimeMillis();
for (int i = 0; i < countInsert; i++) {
//调用List的方法:add(Integer element),中间插入数据
iG.add(numberInsert);
}
long timeEnd = System.currentTimeMillis();
System.out.printf("在%s 最后面插入%d条数据,总共耗时 %d 毫秒,初始化完毕! %n", type, countInsert, timeEnd - timeStart);
}
}


3.3 HashMap vs HashTable
都实现了Map接口,都是键值对保存数据的方式。
- HashMap:可存放null,不是线程安全的类;
- HashTable:不可存放null,是线程安全的类。
package collection;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
//反转HashMap的key和value
public class TestCollection {
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
HashMap<String,String> temp = new HashMap<>();
map.put("adc", "物理英雄");
map.put("apc", "魔法英雄");
map.put("t", "坦克");
System.out.println("初始化后的Map:");
System.out.println(map);
Set<String> keys = map.keySet();
for (String key : keys) {
String value = map.get(key);
temp.put(value, key);
}
map.clear();
map.putAll(temp);
System.out.println("反转后的Map:");
System.out.println(map);
}
}
3.4 几种Set
HashSet、LinkedHashSet和 TreeSet
- HashSet 无序;
- LinkedHashSet 按照插入顺序;
- TreeSet 从小到大顺序。
package collection;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
/**
* @Title
* @description
* @author hmg
* @version 创建时间:2019年12月16日 上午11:07:36
* @version 1.0
*/
public class TestCollection {
public static void main(String[] args) {
// TODO Auto-generated method stub
Set<Integer> someSet;
someSet=new HashSet<Integer>();
inputAndPrint(someSet,"HashSet");
someSet=new LinkedHashSet<Integer>();
inputAndPrint(someSet,"LinkedHashSet");
someSet=new TreeSet<Integer>();
inputAndPrint(someSet,"TreeSet");
}
public static void inputAndPrint(Set<Integer> ss,String type) {
ss.add(2);
ss.add(1);
ss.add(56);
ss.add(3);
ss.add(9);
System.out.println(type+ss);
}
}

练习之既不重复,又有顺序
package collection;
import java.util.LinkedHashSet;
import java.util.Set;
public class TestCollection {
public static void main(String[] args) {
Set<Integer> result = new LinkedHashSet<>();
String str = String.valueOf(Math.PI);
// 去掉点号
str = str.replace(".", "");
char[] cs = str.toCharArray();
for (char c : cs) {
int num = Integer.parseInt(String.valueOf(c));
result.add(num);
}
System.out.printf("%s中的无重复数字是:%n",String.valueOf(Math.PI));
System.out.println(result);
}
}
04 其他
4.1 hashcode原理
(1)List查找的低效率
List<Hero> heros = new ArrayList<Hero>();
测试逻辑:
- 初始化2000000个对象到ArrayList中
- 打乱容器中的数据顺序
Collections.shuffle(heros); - 进行10次查询,统计每一次消耗的时间
(2)HashMap查找的高效性
- 初始化2000000个对象到HashMap中。
- 进行10次查询
- 统计每一次的查询消耗的时间
可以观察到,几乎不花时间,花费的时间在1毫秒以内
(3)HashMap原理与字典
在展开HashMap原理的讲解之前,首先回忆一下大家初中和高中使用的汉英字典。
比如要找一个单词对应的中文意思,假设单词是Lengendary,首先在目录找到Lengendary在第 555页。
然后,翻到第555页,这页不只一个单词,但是量已经很少了,逐一比较,很快就定位目标单词Lengendary。
555相当于就是Lengendary对应的hashcode。
(4)HashMap性能卓越的原因
空间换时间
练习之自定义一个hashcode
计算100个,2-10随机长度的字符串的hashcode
package collection;
import java.util.List;
import java.util.ArrayList;
/*
*自定义一个hashcode,计算100个,2-10随机长度的字符串的hashcode
*/
public class TestArrayList {
public static void main(String[] args) {
List<String> stringGroup=new ArrayList<String>();;
stringGroup=randomString(100);
for(String st:stringGroup) {
int hashcodeString=hashcode(st);
System.out.printf("字符串为%s,hashcode为%d%n",st,hashcodeString);
}
}
//随机生成pools中的某一个字符
public static String randomChar() {
String pools="zxcvbnmasdfghjklqwertyuiopZXCVBNMASDFGHJKLQWERTYUIOP0123456789";
char c=pools.charAt((int)(Math.random()*(pools.length())));
return Character.toString(c);
}
//随机生成数量为100个,2-10随机长度的字符串
public static List<String> randomString(int sumOfString){
List<String> strGroup=new ArrayList<String>();;
for(int i=0;i<sumOfString;i++) {
int lengthOfString=(int)(Math.random()*9+2);
String str="";
for(int j=0;j<lengthOfString;j++) {
str+=randomChar();
}
strGroup.add(str);
}
return strGroup;
}
//对字符串求取hashcode
public static int hashcode(String str) {
if(str=="")
return 0;
char[] cs=new char[str.length()];
cs=str.toCharArray();
int sum=0;
for(char c:cs) {
sum+=(int)c;
}
sum=sum<-sum?-sum:sum;
return sum*23%2000;
}
}
练习之自定义MyHashMap
package collection;
public interface IHashMap {
public void put(String key,Object object);
public Object get(String key);
}
package collection;
//键值对
package collection;
//键值对
public class Entry {
public Entry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
public Object key;
public Object value;
@Override
public String toString() {
return "[key=" + key + ", value=" + value + "]";
}
}
package collection;
import java.util.LinkedList;
/*
*@Author 胡敏干
*@Description
*@Time 2019年12月16日下午11:15:36
*@Version1.0
*/
public class MyHashMap implements IHashMap{
LinkedList<Entry>[] values=new LinkedList[2000];
public static void main(String[] args) {
// TODO Auto-generated method stub
MyHashMap mhp=new MyHashMap();
mhp.put("luban", 45);
Object ob=mhp.get("luban");
System.out.println(ob);
}
@Override
public void put(String key, Object object) {
// TODO Auto-generated method stub
// 拿到hashcode
int hashCode=keyToHashCode(key);
// 找到对应的LinkedList
LinkedList<Entry> list=values[hashCode];
// 如果LinkedList是null,则创建一个LinkedList
if(list==null) {
list=new LinkedList<Entry>();
values[hashCode]=list;
}
// 判断该key是否已经有对应的键值对
boolean found=false;
for(Entry entry:list) {
// 如果已经有了,则替换掉
if(key.equals(entry.key)) {
entry.value=object;
found=true;
break;
}
}
// 如果没有已经存在的键值对,则创建新的键值对
if(!found) {
Entry entry=new Entry(key,object);
list.add(entry);
}
}
@Override
public Object get(String key) {
// TODO Auto-generated method stub
// 获取hashcode
int hashCode=keyToHashCode(key);
String str="";
// 找到hashcode对应的LinkedList
LinkedList<Entry> list=values[hashCode];
if(list==null) {
str="没有";
return str;
}
boolean found=false;
for(Entry entry:list) {
if(key.equals(entry.key)) {
// 挨个比较每个键值对的key,找到匹配的,返回其value
str=String.valueOf(entry.value);
found=true;
break;
}
}
if(!found)
str="没有";
return str;
}
public int keyToHashCode(String key) {
if(key.length()==0)
return 0;
char[] cs=key.toCharArray();
int sum=0;
for(char c:cs) {
sum+=(int)c;
}
// 取绝对值
sum=sum<0?-sum:sum;
return sum*23%2000;
}
public String toString() {
LinkedList<Entry> result = new LinkedList();
for (LinkedList<Entry> linkedList : values) {
if (null == linkedList)
continue;
result.addAll(linkedList);
}
return result.toString();
}
}
练习之内容查找性能比较
有待补充
4.2 比较器
(1)Comparator
多类型集合,按其中某一项大小排序,需要Comparator指定。
假设Hero有三个属性 name,hp,damage
一个集合中放存放10个Hero,通过Collections.sort对这10个进行排序
那么到底是hp小的放前面?还是damage小的放前面?Collections.sort也无法确定
所以要指定到底按照哪种属性进行排序
这里就需要提供一个Comparator给定如何进行两个对象之间的大小比较
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
Random r =new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 10; i++) {
//通过随机值实例化hero的hp和damage
heros.add(new Hero("hero "+ i, r.nextInt(100), r.nextInt(100)));
}
System.out.println("初始化后的集合:");
System.out.println(heros);
//直接调用sort会出现编译错误,因为Hero有各种属性
//到底按照哪种属性进行比较,Collections也不知道,不确定,所以没法排
//Collections.sort(heros);
//引入Comparator,指定比较的算法
Comparator<Hero> c = new Comparator<Hero>() {
@Override
public int compare(Hero h1, Hero h2) {
//按照hp进行排序
if(h1.hp>=h2.hp)
return 1; //正数表示h1比h2要大
else
return -1;
}
};
Collections.sort(heros,c);
System.out.println("按照血量排序后的集合:");
System.out.println(heros);
}
}
package charactor;
public class Hero {
public String name;
public float hp;
public int damage;
public Hero() {
}
public Hero(String name) {
this.name = name;
}
public String toString() {
return "Hero [name=" + name + ", hp=" + hp + ", damage=" + damage + "]\r\n";
}
public Hero(String name, int hp, int damage) {
this.name = name;
this.hp = hp;
this.damage = damage;
}
}
(2)Comparable
使Hero类实现Comparable接口
在类里面提供比较算法
Collections.sort就有足够的信息进行排序了,也无需额外提供比较器Comparator
注: 如果返回-1, 就表示当前的更小,否则就是更大
package charactor;
public class Hero implements Comparable<Hero>{
public String name;
public float hp;
public int damage;
public Hero(){
}
public Hero(String name) {
this.name =name;
}
//初始化name,hp,damage的构造方法
public Hero(String name,float hp, int damage) {
this.name =name;
this.hp = hp;
this.damage = damage;
}
@Override
public int compareTo(Hero anotherHero) {
if(damage<anotherHero.damage)
return 1;
else
return -1;
}
@Override
public String toString() {
return "Hero [name=" + name + ", hp=" + hp + ", damage=" + damage + "]\r\n";
}
}
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.Random;
import charactor.Hero;
public class TestCollection {
public static void main(String[] args) {
Random r =new Random();
List<Hero> heros = new ArrayList<Hero>();
for (int i = 0; i < 10; i++) {
//通过随机值实例化hero的hp和damage
heros.add(new Hero("hero "+ i, r.nextInt(100), r.nextInt(100)));
}
System.out.println("初始化后的集合");
System.out.println(heros);
//Hero类实现了接口Comparable,即自带比较信息。
//Collections直接进行排序,无需额外的Comparator
Collections.sort(heros);
System.out.println("按照伤害高低排序后的集合");
System.out.println(heros);
}
}
练习之自定义顺序的TreeSet
默认情况下,TreeSet中的数据是从小到大排序的,不过TreeSet的构造方法支持传入一个Comparator
public TreeSet(Comparator comparator)
通过这个构造方法创建一个TreeSet,使得其中的的数字是倒排序的
package collection;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class TestCollection {
public static void main(String[] args) {
Comparator<Integer> c =new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
};
Set<Integer> treeSet = new TreeSet<>(c);
for (int i = 0; i < 10; i++) {
treeSet.add(i);
}
System.out.println(treeSet);
}
}
练习之Comparable
借助Comparable接口,使Item具备按照价格从高到低排序。
初始化10个Item,并且用Collections.sort进行排序,查看排序结果
package collection;
/*
*@Author hmg
*@Description
*@Time 2019年12月16日下午10:39:22
*@Version1.0
*/
public class Item implements Comparable<Item>{
public String name;
public int price;
@Override
public int compareTo(Item o) {
// TODO Auto-generated method stub
return o.price-price;
}
public Item() {
this.name="";
this.price=0;
}
public Item(String name,int price) {
this.name=name;
this.price=price;
}
public String toString() {
String str=name+"\t"+price;
return str;
}
}
package collection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
//分别用Hashset和ArrayList获取50个不同的随机数
public class TestCollection {
public static void main(String[] args) {
List<Item> listItem=new ArrayList<>();
System.out.println("排序前:");
for(int i=0;i<10;i++) {
int random=(int)(Math.random()*100+50);
listItem.add(new Item("Item "+i,random));
System.out.println(listItem.get(i));;
}
Collections.sort(listItem);
System.out.println("排序后:");
for(Item i:listItem) {
System.out.println(i);
}
}
}
4.3 聚合操作
JDK8之后,引入了对集合的聚合操作,可以非常容易的遍历,筛选,比较集合中的元素。
像这样:
String name =heros
.stream()
.sorted((h1,h2)->h1.hp>h2.hp?-1:1)
.skip(2)
.map(h->h.getName())
.findFirst()
.get();
但是要用好聚合,必须先掌握Lambda表达式,聚合的章节讲放在Lambda与聚合操作部分详细讲解。
本文学习内容均来自how2j.cn,用于个人笔记和总结,想学习的可以到该网站学习哦,侵删。















 917
917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









