






单个热图内容太多了,全部放一章滑都滑不到底,所以先分成上下章,到时候再整合起来。
2. 单个热图
2.1 颜色
2.2 标题
2.3 聚类
2.3.1 距离方法
2.3.2 聚类方法
2.3.3 渲染树状图
2.3.4 重排树状图
2.4 设置行列顺序
2.5 维度名称
单个热图是最常用的数据可视化方法。尽管ComplexHeatmap包的“亮点”是它可以并行地可视化热图列表,但是,作为热图列表的基本单元,对单个热图进行良好配置仍然是非常重要的。
首先,让我们生成一个随机矩阵,其中有三组在列和三组在行:
set.seed(123)#设种子为了随机可重复
nr1 = 4; nr2 = 8; nr3 = 6; nr = nr1 + nr2 + nr3
nc1 = 6; nc2 = 8; nc3 = 10; nc = nc1 + nc2 + nc3
#cbind按行合并 rbind按列合并
mat = cbind(rbind(matrix(rnorm(nr1*nc1, mean = 1, sd = 0.5), nr = nr1),
matrix(rnorm(nr2*nc1, mean = 0, sd = 0.5), nr = nr2),
matrix(rnorm(nr3*nc1, mean = 0, sd = 0.5), nr = nr3)),
rbind(matrix(rnorm(nr1*nc2, mean = 0, sd = 0.5), nr = nr1),
matrix(rnorm(nr2*nc2, mean = 1, sd = 0.5), nr = nr2),
matrix(rnorm(nr3*nc2, mean = 0, sd = 0.5), nr = nr3)),
rbind(matrix(rnorm(nr1*nc3, mean = 0.5, sd = 0.5), nr = nr1),
matrix(rnorm(nr2*nc3, mean = 0.5, sd = 0.5), nr = nr2),
matrix(rnorm(nr3*nc3, mean = 1, sd = 0.5), nr = nr3))
)
mat = mat[sample(nr, nr), sample(nc, nc)] # 随机打乱行和列
rownames(mat) = paste0("row", seq_len(nr))
colnames(mat) = paste0("column", seq_len(nc))
head(mat)
> head(mat)
column1 column2 column3 column4 column5 column6 column7
row1 0.90474160 -0.35229823 0.5016096 1.26769942 0.8251229 0.16215217 -0.2869867
row2 0.90882972 0.79157121 1.0726316 0.01299521 0.1391978 0.46833693 1.2814948
row3 0.28074668 0.02987497 0.7052595 1.21514235 0.1747267 0.20949120 -0.6423579
row4 0.02729558 0.75810969 0.5333504 -0.49637424 -0.5261114 0.56724357 0.8127096
row5 -0.32552445 1.03264652 1.1249573 0.66695147 0.4490584 1.04236865 2.6205200
row6 0.58403269 -0.47373731 0.5452483 0.86824798 -0.1976372 -0.03565404 -0.3203530
下面的命令包含Heatmap()函数的最小参数,该函数将矩阵显示为带有默认设置的热图。默认的颜色模式是“蓝-白-红”,它被映射到矩阵中的最小-平均-最大值。
BiocManager::install("ComplexHeatmap")
library(ComplexHeatmap)
Heatmap(mat)
2.1 颜色
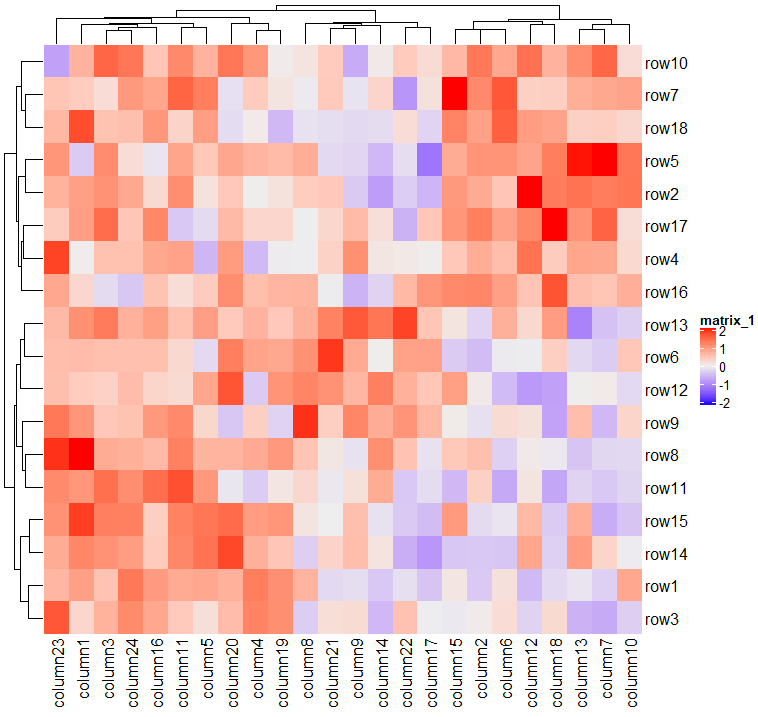
用户应该使用circle::colorRamp2()函数来生成Heatmap()中的颜色映射函数。
在下面的例子中,对-2到2之间的值进行线性插值得到相应的颜色,大于2的值都映射为红色,小于-2的值都映射为绿色。
library(circlize)
col_fun = colorRamp2(c(-2, 0, 2), c("green", "white", "red"))
Heatmap(mat, name = "mat", col = col_fun)
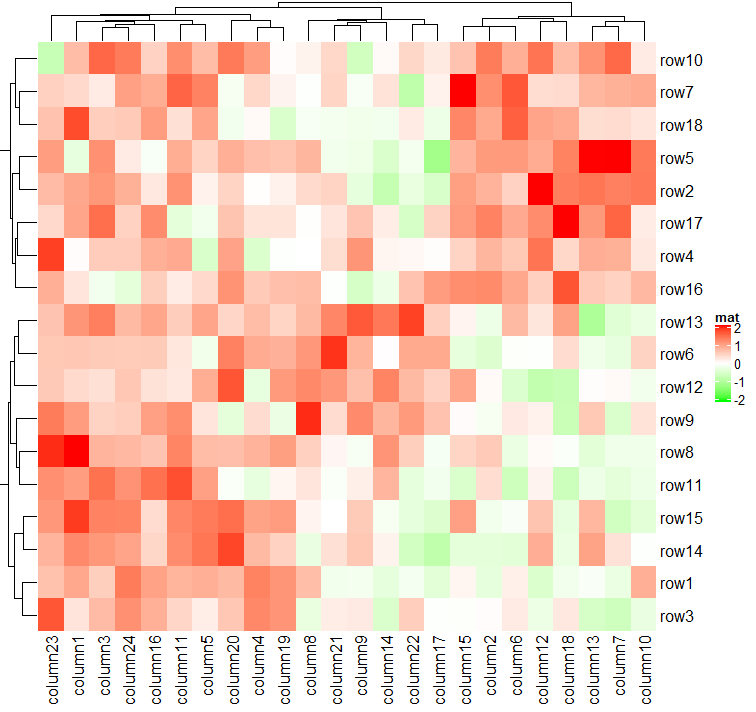
colorRamp2()使多个热图中的颜色具有可比性,如果它们是用同一个颜色映射函数设置的。在以下三个热图中,相同的颜色总是对应相同的值。
Heatmap(mat, name = "mat", col = col_fun, column_title = "mat")
Heatmap(mat/4, name = "mat", col = col_fun, column_title = "mat/4")
Heatmap(abs(mat), name = "mat", col = col_fun, column_title = "abs(mat)")

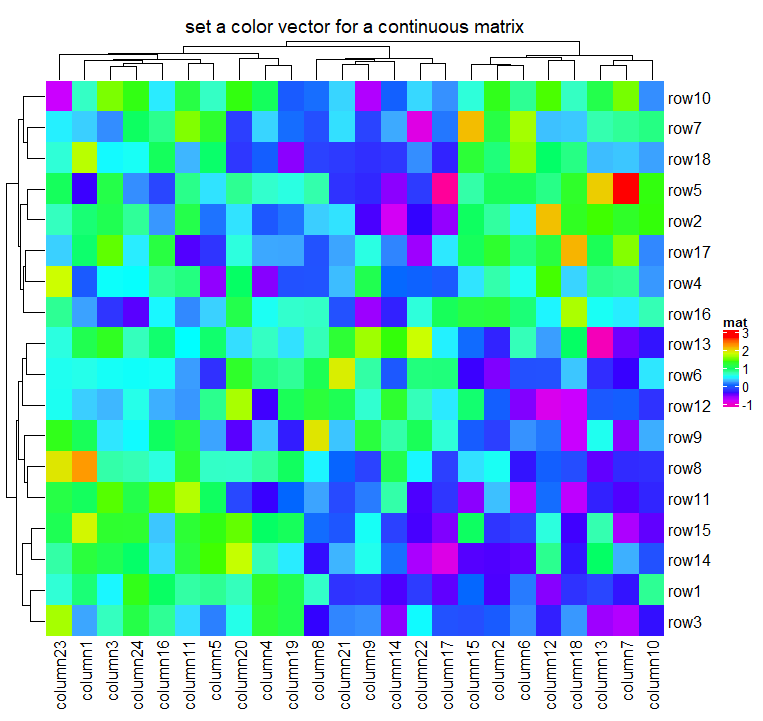
如果矩阵是连续的,你也可以简单地提供一个颜色向量。但是这种方法对离群值是不可靠的,因为映射从矩阵中的最小值开始,以最大值结束。以下颜色映射设置与colorRamp2(seq(min(mat), max(mat), length = 10), rev(rainbow(10))相同。
Heatmap(mat, name = "mat", col = rev(rainbow(10)),
column_title = "set a color vector for a continuous matrix")
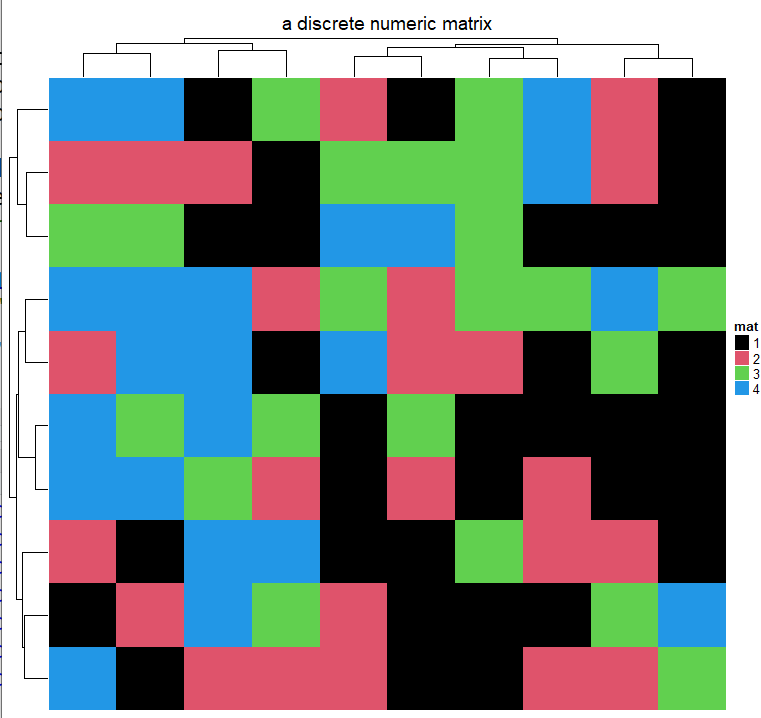
如果矩阵包含离散值(数字或字符),颜色应指定为命名向量,使离散值映射到颜色成为可能。注意现在图例是由颜色映射向量生成的。
下面为离散数字矩阵设置颜色(不需要将其转换为字符矩阵)。
discrete_mat = matrix(sample(1:4, 100, replace = TRUE), 10, 10)
colors = structure(1:4, names = c("1", "2", "3", "4")) # black, red, green, blue
Heatmap(discrete_mat, name = "mat", col = colors,
column_title = "a discrete numeric matrix")
或者字符矩阵:
discrete_mat = matrix(sample(letters[1:4], 100, replace = TRUE), 10, 10)
colors = structure(1:4, names = letters[1:4])
Heatmap(discrete_mat, name = "mat", col = colors,
column_title = "a discrete character matrix")

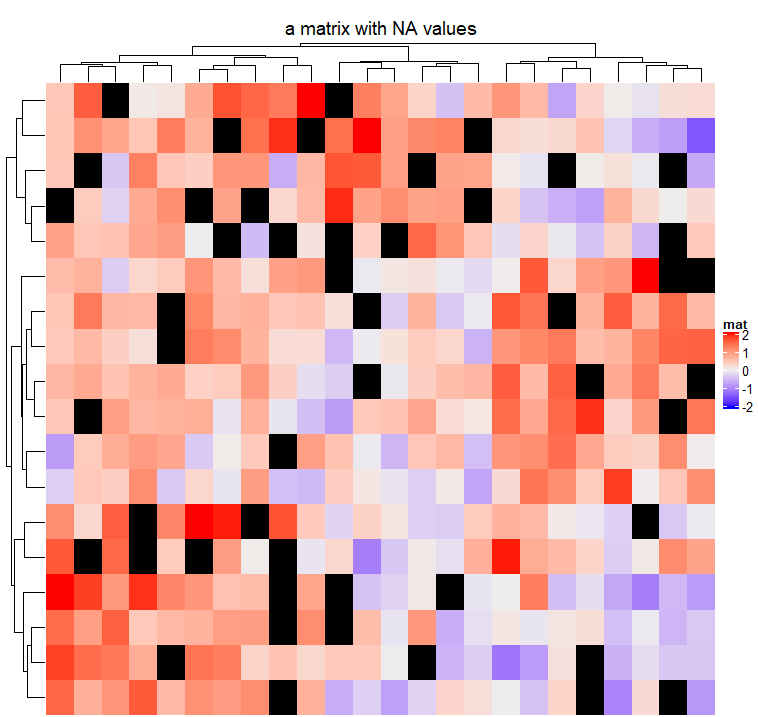
矩阵中允许有NA。可以通过na_col参数来控制NA的颜色(默认为灰色)。包含NA的矩阵可以通过Heatmap()进行聚类。注意图例中没有NA的值。
mat_with_na = mat
na_index = sample(c(TRUE, FALSE), nrow(mat)*ncol(mat), replace = TRUE, prob = c(1, 9))
mat_with_na[na_index] = NA #构建含NA的矩阵
Heatmap(mat_with_na, name = "mat", na_col = "black",
column_title = "a matrix with NA values")
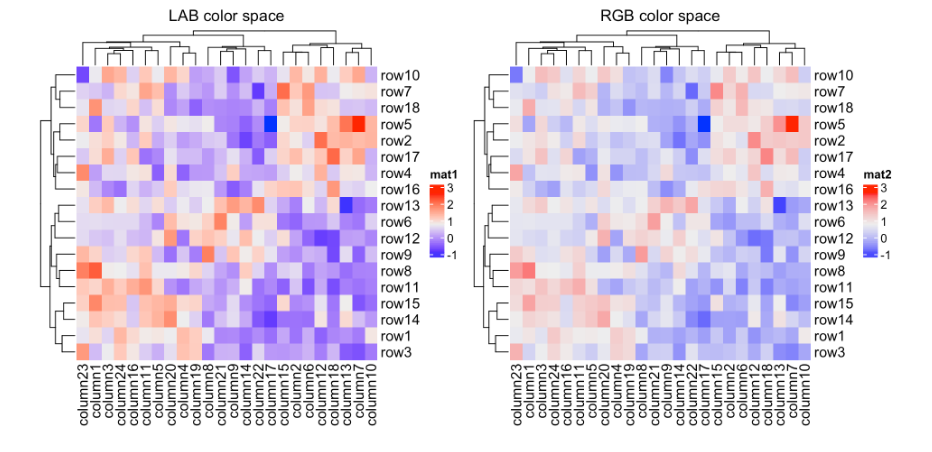
颜色空间对于插值颜色非常重要。默认情况下,颜色是在LAB color space中线性插值的,但是可以在colorRamp2()函数中选择颜色空间。
f1 = colorRamp2(seq(min(mat), max(mat), length = 3), c("blue", "#EEEEEE", "red"))
f2 = colorRamp2(seq(min(mat), max(mat), length = 3), c("blue", "#EEEEEE", "red"), space = "RGB")
Heatmap(mat, name = "mat1", col = f1, column_title = "LAB color space")
Heatmap(mat, name = "mat2", col = f2, column_title = "RGB color space")
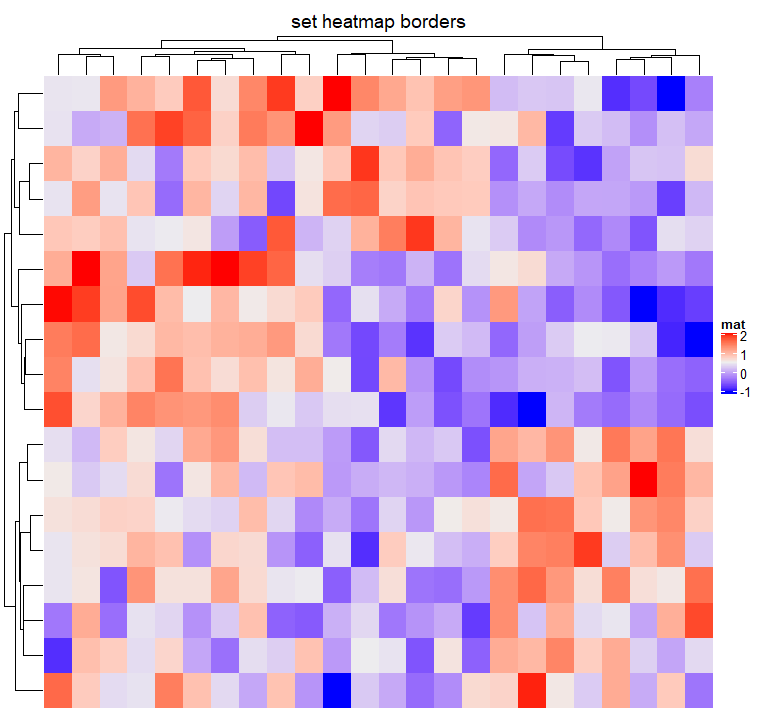
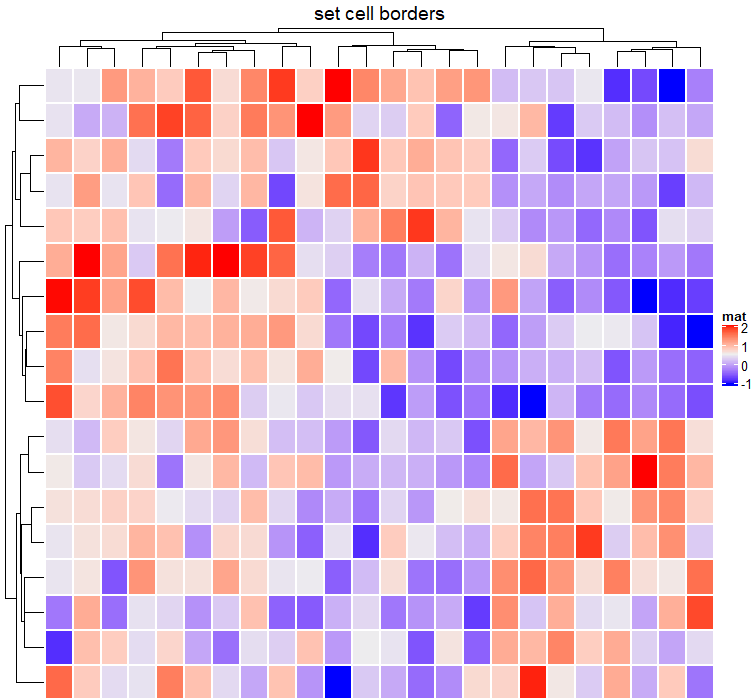
热图边界的颜色可以通过border/border_gp和rect_gp参数设置。border/border_gp控制热图主体的全局边界,rect_gp控制热图中的网格/单元格的边界。
border的值可以是逻辑的(TRUE对应黑色)或一个颜色字符(例如红色)。这
rect_gp是一个gpar对象,这意味着你只能通过grid::gpar()来设置它。由于填充的颜色已经由热图颜色映射控制,所以您只能在gpar()中设置col参数来控制热图网格的边界。
Heatmap(mat, name = "mat", border = FALSE,
column_title = "set heatmap borders")
Heatmap(mat, name = "mat", rect_gp = gpar(col = "white", lwd = 2),
column_title = "set cell borders")#lty线型, lwd线宽
Heatmap(mat, name = "mat", rect_gp = gpar(type = "none"),
column_title = "nothing is drawn in the heatmap body")

2.2 标题
Heatmap(mat, name = "mat", column_title = "I am a column title",
row_title = "I am a row title")
Heatmap(mat, name = "mat", column_title = "I am a column title at the bottom",
column_title_side = "bottom")
Heatmap(mat, name = "mat", column_title = "I am a big column title",
column_title_gp = gpar(fontsize = 20, fontface = "bold"))
 标题的旋转可以通过
标题的旋转可以通过row_title_rot和column_title_rot设置,但只允许水平和垂直旋转。
Heatmap(mat, name = "mat", row_title = "row title", row_title_rot = 0)
可以通过设置row_title_gp和column_title_gp中的填充参数来设置标题的背景颜色。如row_title_gp控制文本的颜色,所以border用来控制背景边框的颜色。
Heatmap(mat, name = "mat", column_title = "I am a column title",
column_title_gp = gpar(fill = "red", col = "white", border = "blue"))
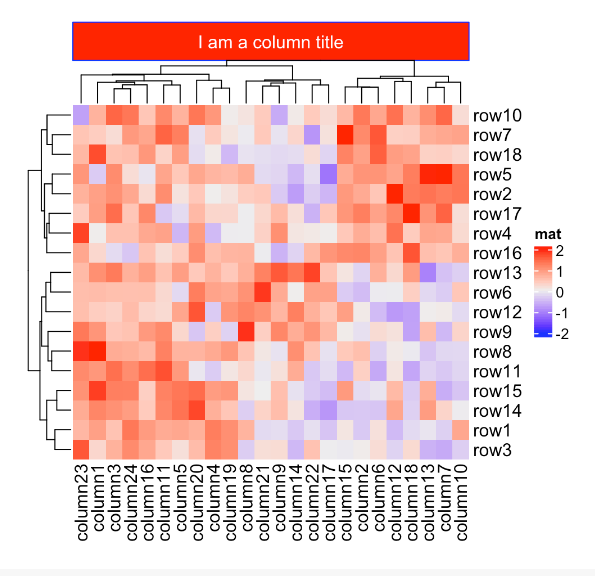
2.3 聚类
聚类是热图可视化的关键组成部分。在ComplexHeatmap包中,分层聚类具有极大的灵活性。你可以通过以下方式来指定聚类:
一种预先定义的距离方法(例如:
"euclidean"or"pearson")一个距离函数
已经包含聚类的对象(
hclust或dendrogram对象)一个聚类函数
首先,对于聚类有一般的设置,例如是应用聚类还是显示树状图,树状图的侧面和树状图的高度。
Heatmap(mat, name = "mat", cluster_rows = FALSE) # 不进行行聚类
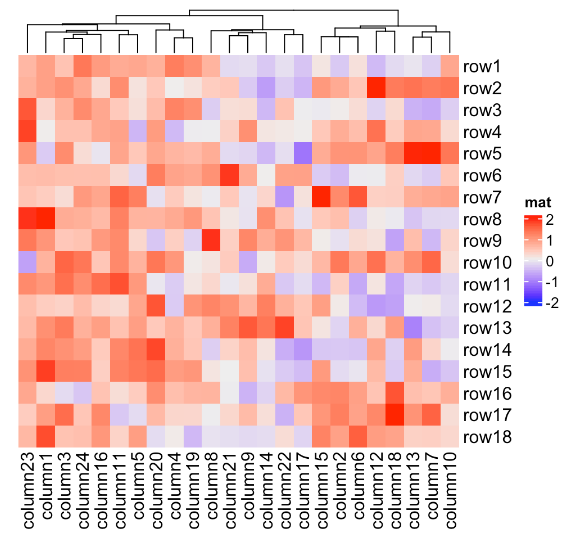
Heatmap(mat, name = "mat", show_column_dend = FALSE) # 不显示列树状图
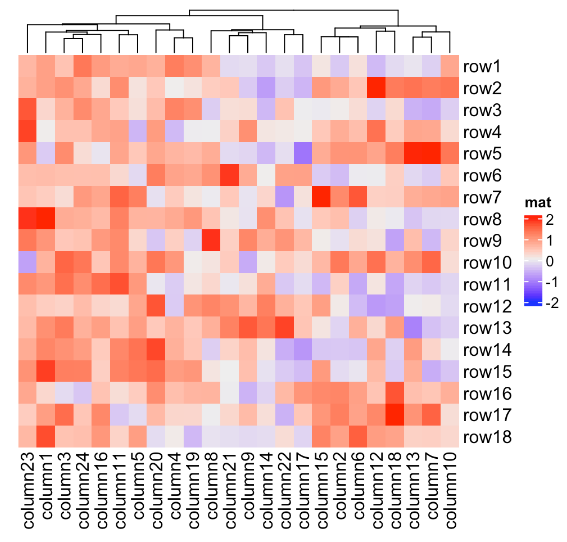
Heatmap(mat, name = "mat", row_dend_side = "right", column_dend_side = "bottom") #树状图位置
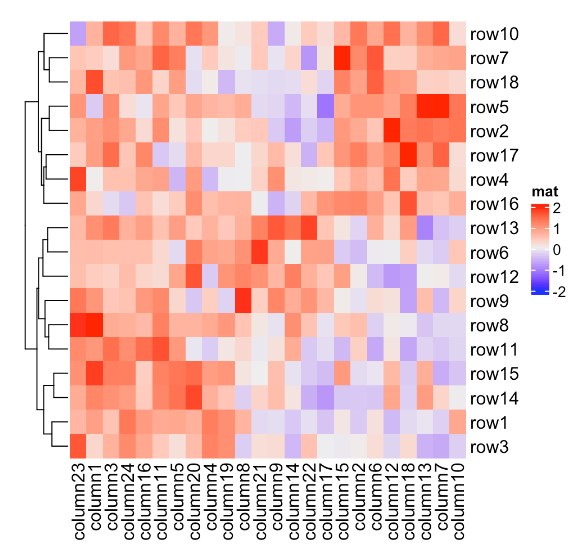
Heatmap(mat, name = "mat", column_dend_height = unit(4, "cm"),
row_dend_width = unit(4, "cm")) #树状图高、宽
2.3.1 距离方法
层次聚类分为两步:计算距离矩阵和应用聚类。有三种方法来指定聚类的距离度量:
指定距离作为一个预定义的选项。有效值是
dist()函数和“pearson”、“spearman”和“kendall”中支持的方法。相关距离定义为1 - cor(x, y, method)。所有这些内置的距离方法都允许NA值。自定义函数,计算与矩阵的距离。这个函数应该只包含一个参数。请注意在列上的聚类,矩阵会自动转置。
一个自定义的函数,计算到两个向量的距离。
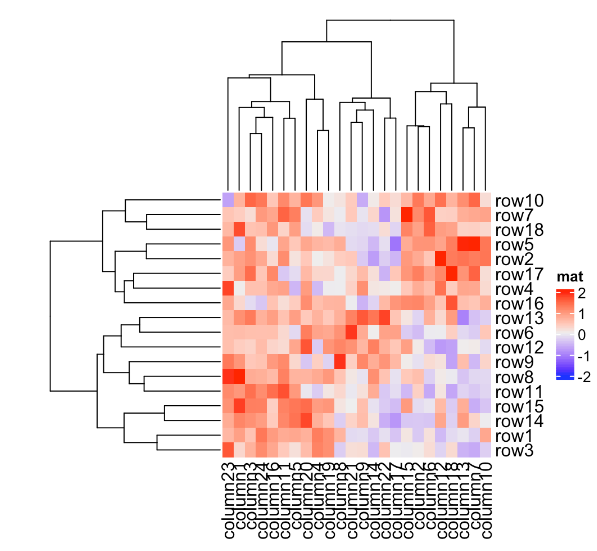
Heatmap(mat, name = "mat", clustering_distance_rows = "pearson",
column_title = "pre-defined distance method (1 - pearson)")
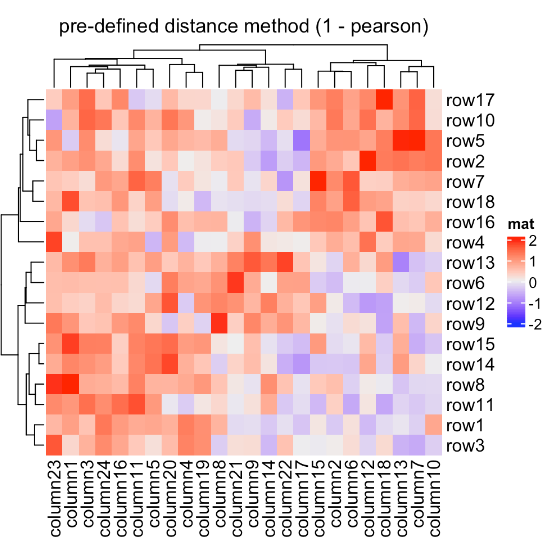
Heatmap(mat, name = "mat", clustering_distance_rows = function(m) dist(m),
column_title = "a function that calculates distance matrix")
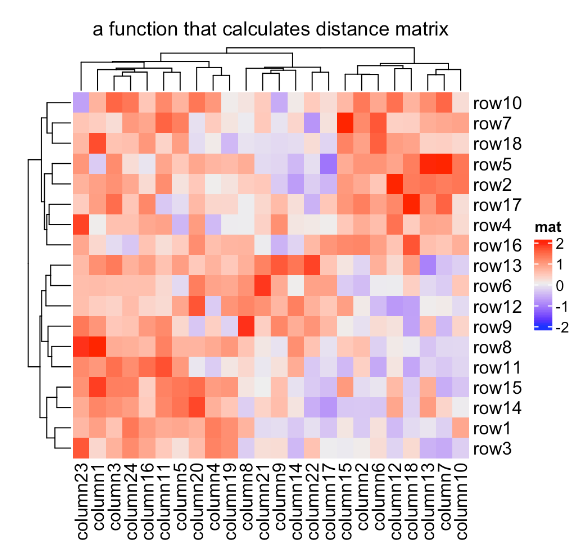
Heatmap(mat, name = "mat", clustering_distance_rows = function(x, y) 1 - cor(x, y),
column_title = "a function that calculates pairwise distance")
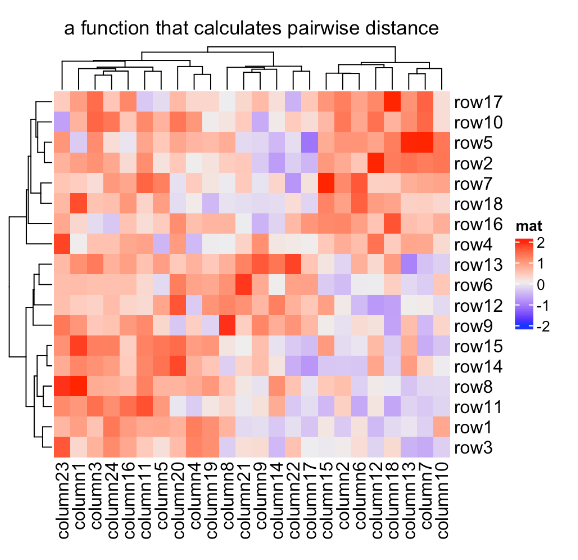
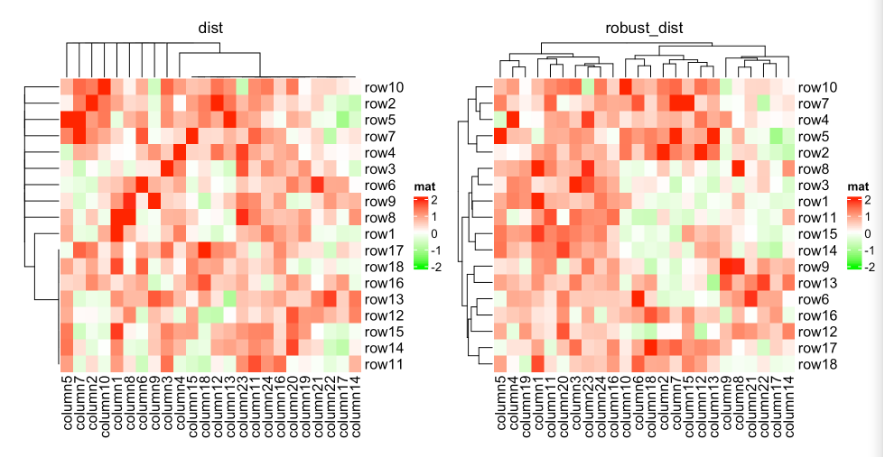
基于这些特征,我们可以利用两两距离对离群点进行鲁棒聚类。这里我们设置了颜色映射函数,因为我们不想让离群值影响颜色。
mat_with_outliers = mat
for(i in 1:10) mat_with_outliers[i, i] = 1000
robust_dist = function(x, y) {
qx = quantile(x, c(0.1, 0.9))
qy = quantile(y, c(0.1, 0.9))
l = x > qx[1] & x < qx[2] & y > qy[1] & y < qy[2]
x = x[l]
y = y[l]
sqrt(sum((x - y)^2))
}
我们可以比较使用和不使用鲁棒距离方法两个热图:
Heatmap(mat_with_outliers, name = "mat",
col = colorRamp2(c(-2, 0, 2), c("green", "white", "red")),
column_title = "dist")
Heatmap(mat_with_outliers, name = "mat",
col = colorRamp2(c(-2, 0, 2), c("green", "white", "red")),
clustering_distance_rows = robust_dist,
clustering_distance_columns = robust_dist,
column_title = "robust_dist")
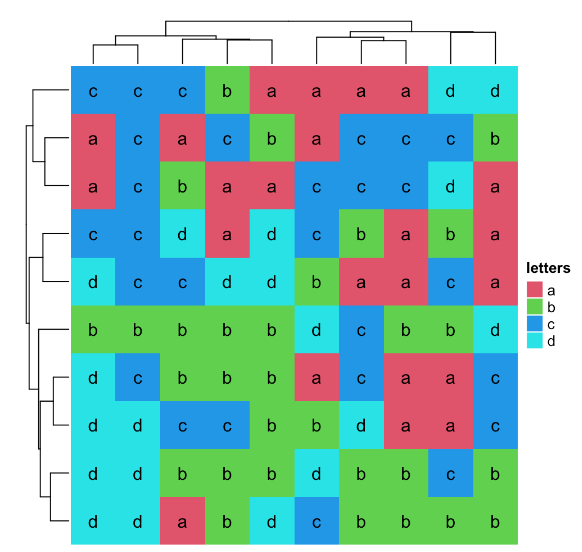
如果有合适的距离方法(如stringdist包中的方法),也可以对字符矩阵进行聚类。
mat_letters = matrix(sample(letters[1:4], 100, replace = TRUE), 10)
# distance in the ASCII table
dist_letters = function(x, y) {
x = strtoi(charToRaw(paste(x, collapse = "")), base = 16)
y = strtoi(charToRaw(paste(y, collapse = "")), base = 16)
sqrt(sum((x - y)^2))
}
Heatmap(mat_letters, name = "letters", col = structure(2:5, names = letters[1:4]),
clustering_distance_rows = dist_letters, clustering_distance_columns = dist_letters,
cell_fun = function(j, i, x, y, w, h, col) { # add text to each grid
grid.text(mat_letters[i, j], x, y)
})
2.3.2 聚类方法
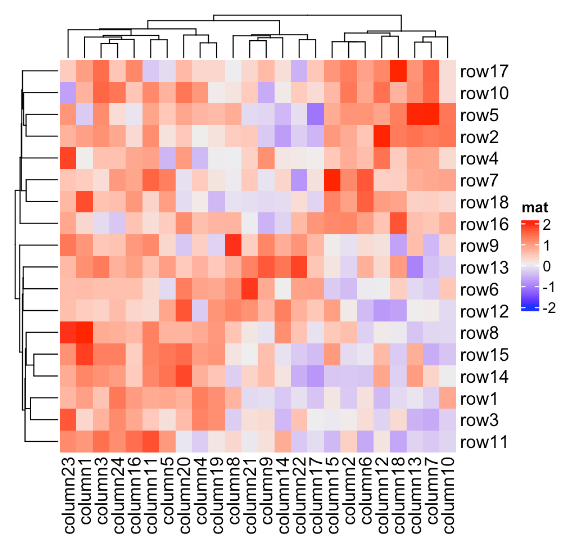
执行分层聚类的方法,可以通过clustering_method_rows和clustering_method_columns指定。可能的方法是hclust()函数中支持的方法。
Heatmap(mat, name = "mat", clustering_method_rows = "single")
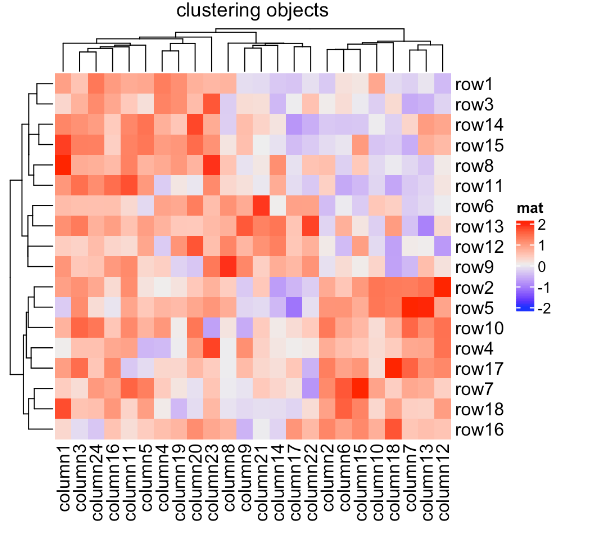
如果已经有一个聚类对象,则可以忽略距离设置,并将cluster_rows或cluster_columns设置为聚类对象或聚类函数。如果它是一个聚类函数,唯一的参数应该是矩阵,它应该返回一个hclust或dendrogram对象,或者一个可以转换为dendrogram类的对象。
在下面的例子中,我们通过预先计算的聚类对象或聚类函数来使用聚类包中的方法来执行聚类:
library(cluster)
Heatmap(mat, name = "mat", cluster_rows = diana(mat),
cluster_columns = agnes(t(mat)), column_title = "clustering objects")
# 如果将cluster_columns设置为一个函数,则不需要转置矩阵
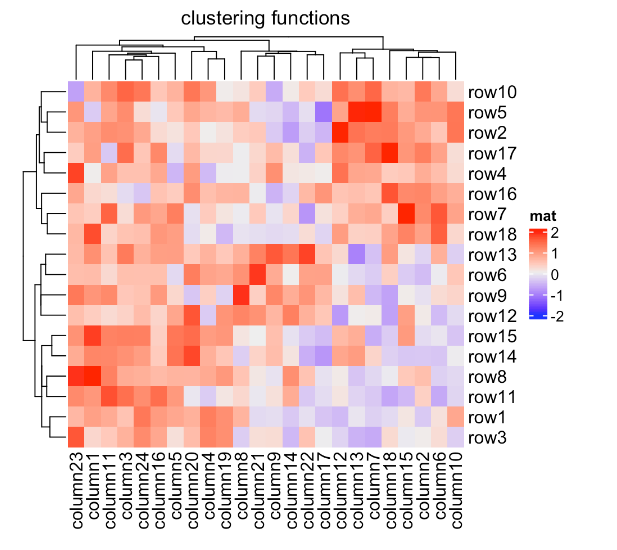
Heatmap(mat, name = "mat", cluster_rows = diana,
cluster_columns = agnes, column_title = "clustering functions")
使用下面的命令也是一样的:
# code only for demonstration
Heatmap(mat, name = "mat", cluster_rows = function(m) as.dendrogram(diana(m)),
cluster_columns = function(m) as.dendrogram(agnes(m)),
column_title = "clutering functions")
2.3.3 渲染树状图
可以通过dendextend包来呈现树形图对象,使树形图更具个性化。
library(dendextend)
row_dend = as.dendrogram(hclust(dist(mat)))
row_dend = color_branches(row_dend, k = 2) # `color_branches()` returns a dendrogram object
Heatmap(mat, name = "mat", cluster_rows = row_dend)
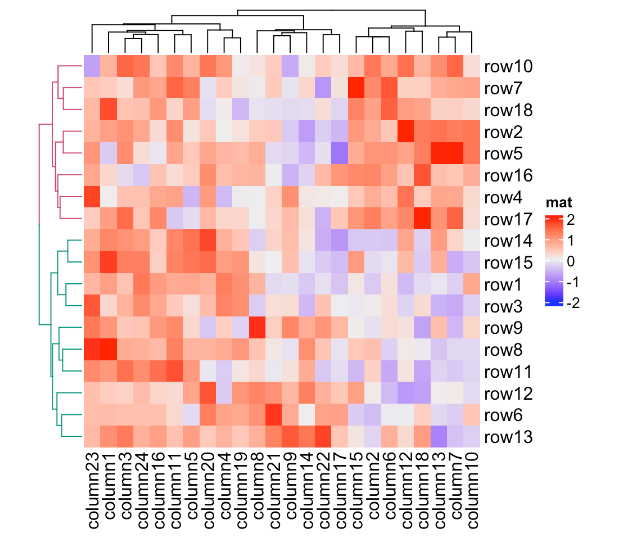
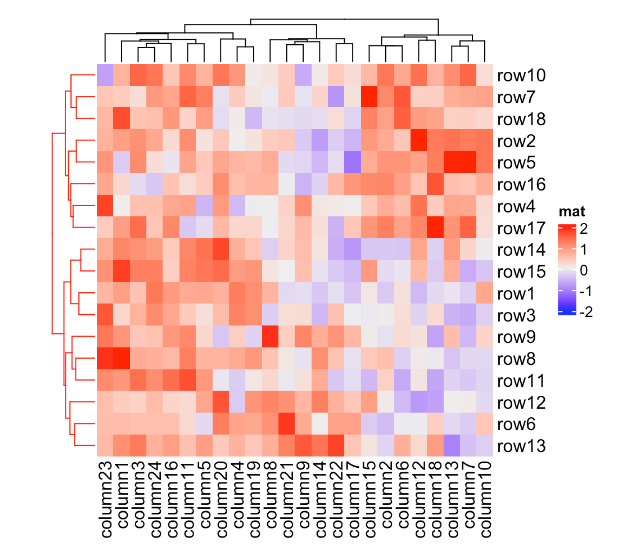
Heatmap(mat, name = "mat", cluster_rows = row_dend, row_dend_gp = gpar(col = "red"))
2.3.4 重排树状图
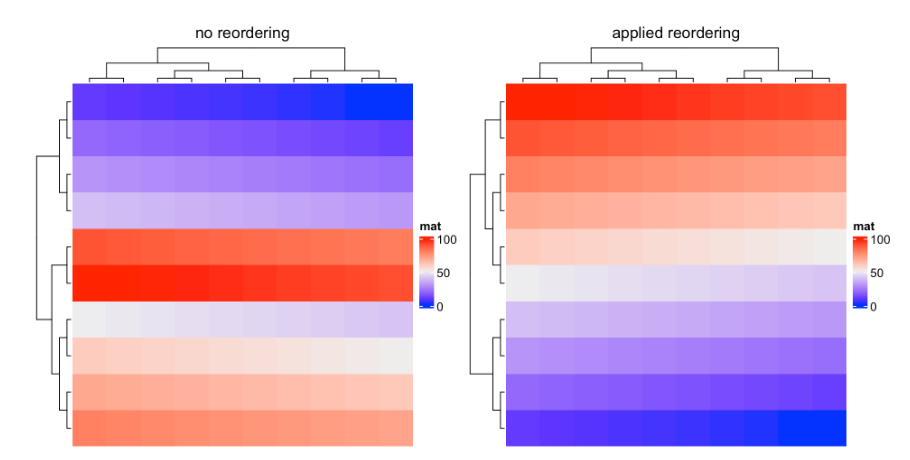
在Heatmap()函数中,树状图被重新排序,使差异较大的特征更加分离(参阅reorder. dendergram()的文档)。这里的差值(或者称为权重)是通过行来度量的,行表示是行树状图,列表示是列树状图。row_dend_reorder和column_dend_reorder控制是否应用树状图重新排序。重新排序可以通过设置row_dend_reorder = FALSE来关闭。
默认情况下,如果将cluster_rows/cluster_columns设置为逻辑值或聚类函数,则会打开树状图重新排序。如果将cluster_rows/cluster_columns设置为聚类对象,则关闭此选项。
比较下面两个热图:
m2 = matrix(1:100, nr = 10, byrow = TRUE)
Heatmap(m2, name = "mat", row_dend_reorder = FALSE, column_title = "no reordering")
Heatmap(m2, name = "mat", row_dend_reorder = TRUE, column_title = "apply reordering")
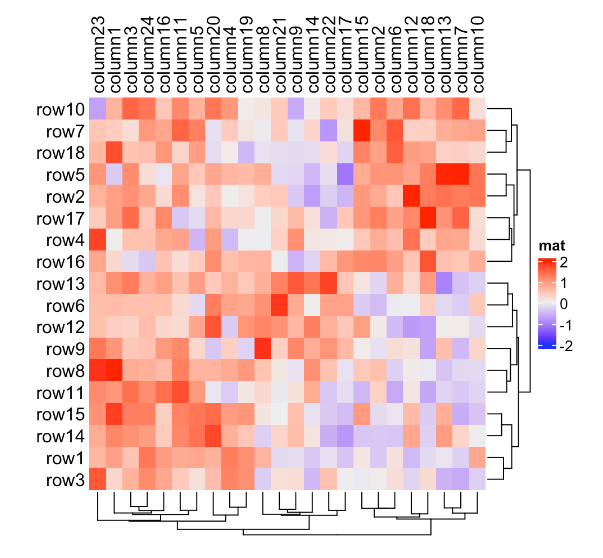
还有许多其他方法可以对树状图进行重新排序,例如dendsort包。也可以根据数据矩阵生成行或列树状图,通过某些方法重新排序它,并将它分配回cluster_rows或cluster_columns。
比较下面两个重排树状图后的热图:
Heatmap(mat, name = "mat", column_title = "default reordering")
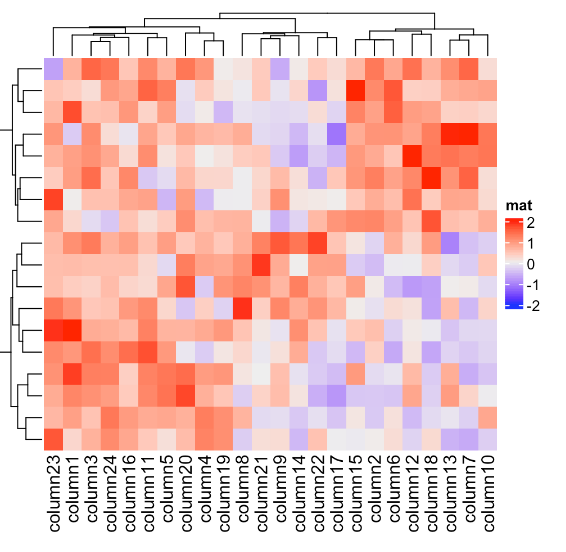
library(dendsort)
row_dend = dendsort(hclust(dist(mat)))
col_dend = dendsort(hclust(dist(t(mat))))
Heatmap(mat, name = "mat", cluster_rows = row_dend, cluster_columns = col_dend,
column_title = "reorder by dendsort")
2.4 设置行列顺序
聚类用于调整热图的行顺序和列顺序,但仍然可以通过row_order和column_order手动设置顺序。
#如果出错了,重新创建mat数据矩阵
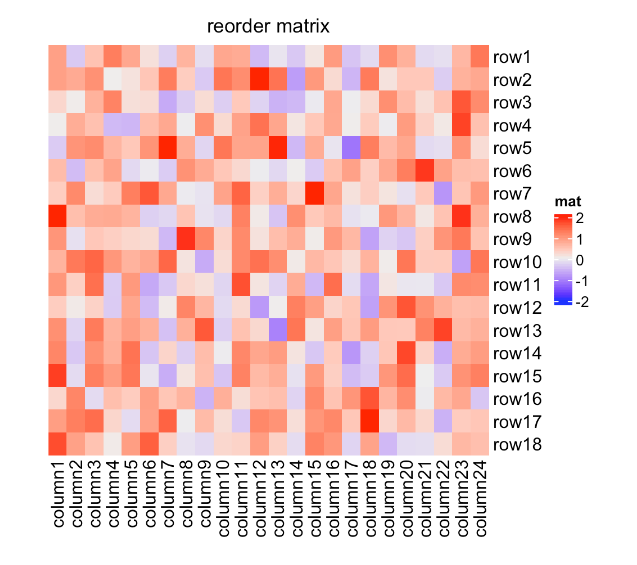
Heatmap(mat, name = "mat", row_order = order(as.numeric(gsub("row", "", rownames(mat)))),
column_order = order(as.numeric(gsub("column", "", colnames(mat)))),
column_title = "reorder matrix")
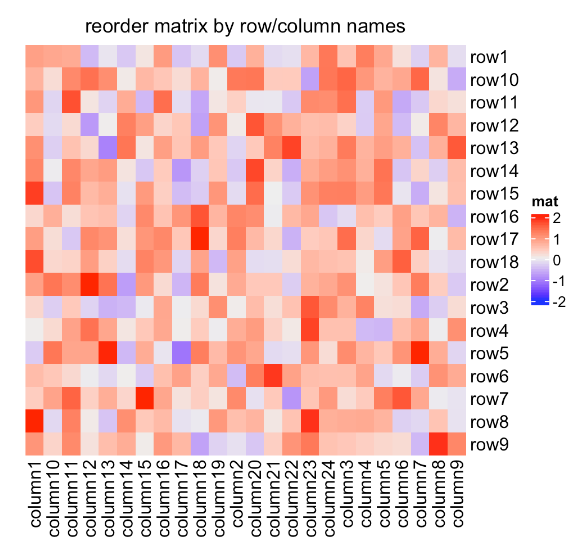
顺序可以是字符向量如果它们只是变换矩阵的行名或列名:
Heatmap(mat, name = "mat", row_order = sort(rownames(mat)),
column_order = sort(colnames(mat)),
column_title = "reorder matrix by row/column names")
2.5 维度名称
默认情况下,行名和列名绘制在热图的右侧和底部。维度名称的侧面、可见性和图形参数设置如下:
Heatmap(mat, name = "mat", row_names_side = "left", row_dend_side = "right",
column_names_side = "top", column_dend_side = "bottom")
Heatmap(mat, name = "mat", show_row_names = FALSE)
Heatmap(mat, name = "mat", row_names_gp = gpar(fontsize = 20))
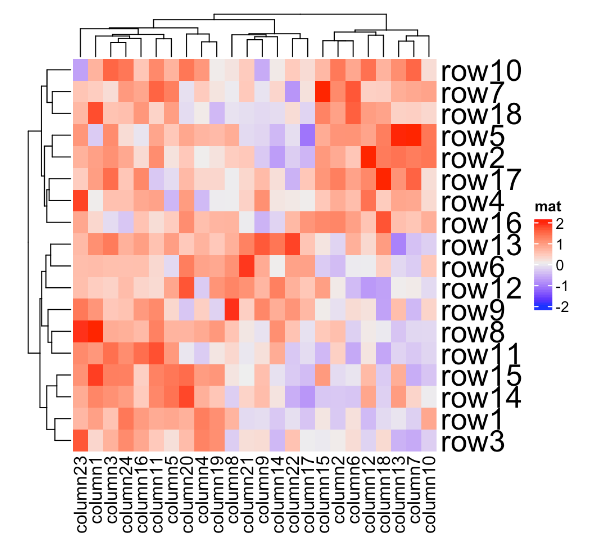
Heatmap(mat, name = "mat", row_names_gp = gpar(col = c(rep("red", 10), rep("blue", 8))))
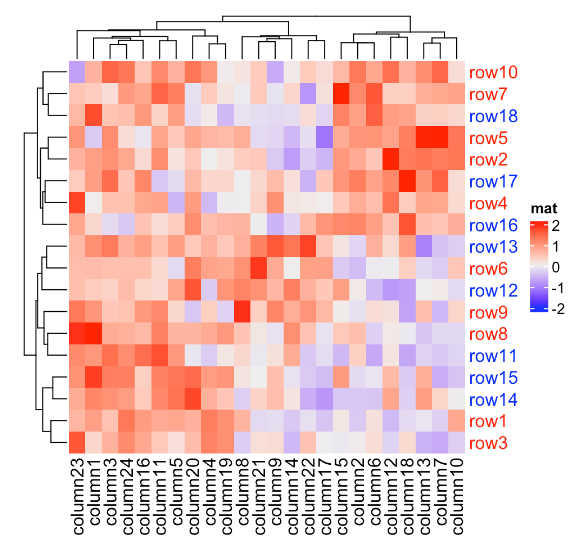
Heatmap(mat, name = "mat", row_names_centered = TRUE, column_names_centered = TRUE)
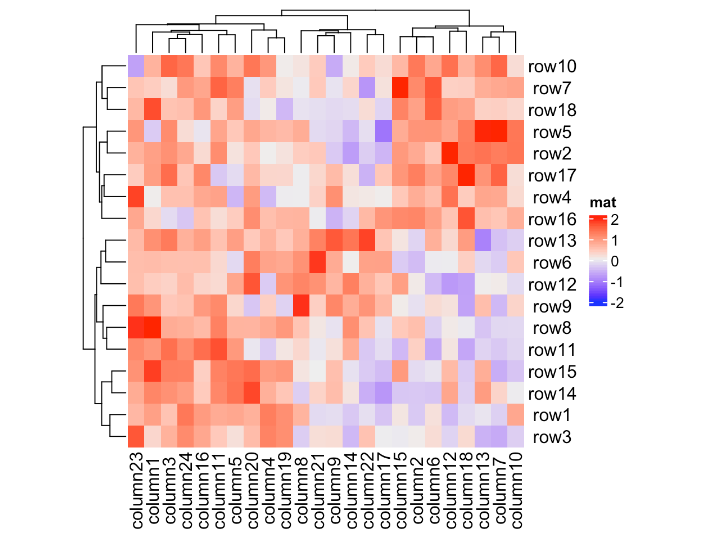
可以通过column_names_rot设置列名的旋转:
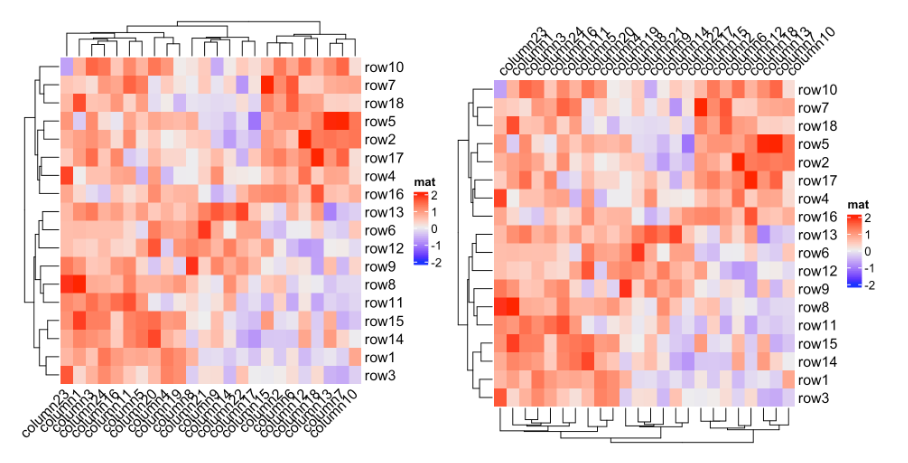
Heatmap(mat, name = "mat", column_names_rot = 45)
Heatmap(mat, name = "mat", column_names_rot = 45, column_names_side = "top",
column_dend_side = "bottom")
如果行名或列名太长,可以使用row_names_max_width或column_names_max_height为它们设置最大空间。行名和列名的默认最大空间都是6厘米。在下面的代码中,max_text_width()是一个帮助函数,用于快速计算文本向量的最大宽度。
mat2 = mat
rownames(mat2)[1] = paste(c(letters, LETTERS), collapse = "")
Heatmap(mat2, name = "mat", row_title = "default row_names_max_width")
Heatmap(mat2, name = "mat", row_title = "row_names_max_width as length of a*",
row_names_max_width = max_text_width(
rownames(mat2),
gp = gpar(fontsize = 12)
))
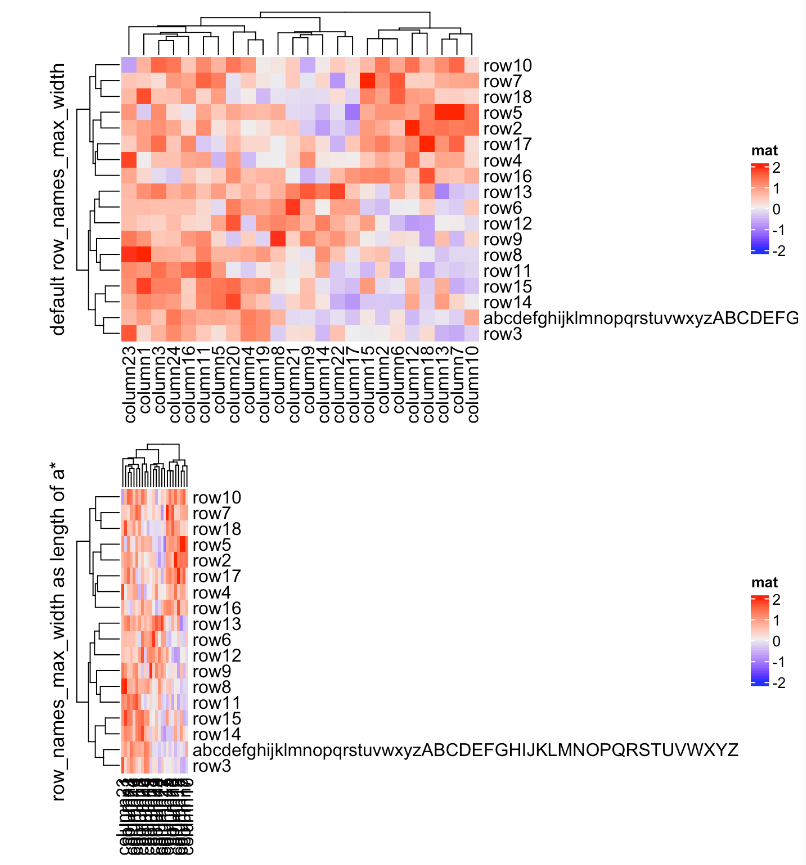
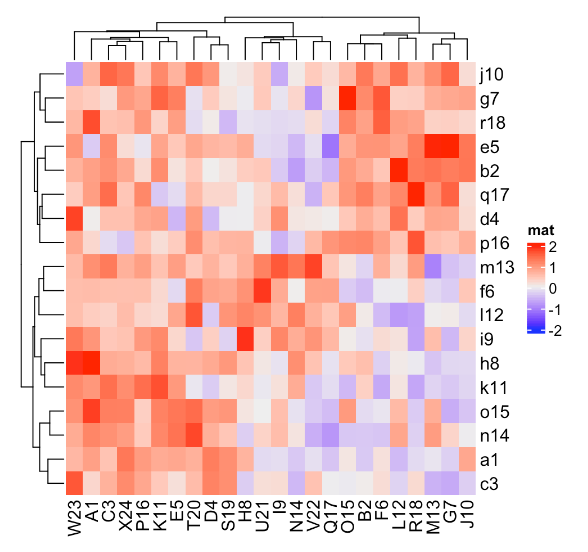
除了直接使用矩阵中的行/列名,还可以提供另一个对应于行或列的字符向量,并通过row_labels或column_labels设置。
对于基因表达分析,我们可以使用Ensembl ID作为基因ID,作为基因表达矩阵的行名。但是,Ensembl ID用于编制Ensembl数据库的索引,而不是用于人类阅读。相反,我们更愿意将gene symbols作为行名放在热图上,这样更容易阅读。为此,我们只需要将相应的gene symbols分配给row_labels,而不需要修改原始矩阵。
第二个优点是row_labels或column_labels允许重复标签,而矩阵中不允许重复的行名或列名。
下面给出了一个简单的例子,我们把字母作为行标签和列标签:
#使用一个命名向量来确保两者之间的对应关系
row_labels = structure(paste0(letters[1:24], 1:24), names = paste0("row", 1:24))
column_labels = structure(paste0(LETTERS[1:24], 1:24), names = paste0("column", 1:24))
row_labels
> row_labels
row1 row2 row3 row4 row5 row6 row7 row8
"a1" "b2" "c3" "d4" "e5" "f6" "g7" "h8"
row9 row10 row11 row12 row13 row14 row15 row16
"i9" "j10" "k11" "l12" "m13" "n14" "o15" "p16"
row17 row18 row19 row20 row21 row22 row23 row24
"q17" "r18" "s19" "t20" "u21" "v22" "w23" "x24"
Heatmap(mat, name = "mat", row_labels = row_labels[rownames(mat)],
column_labels = column_labels[colnames(mat)])
第三个优点是可以在热图中使用数学表达式作为行名。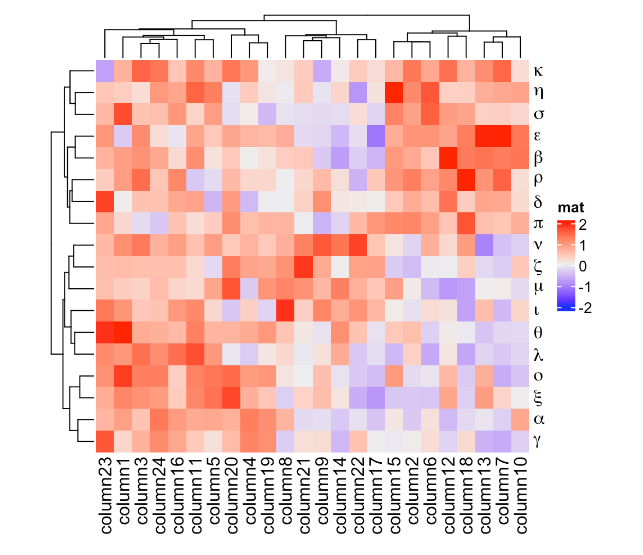
参考资料
https://github.com/jokergoo/ComplexHeatmap
https://jokergoo.github.io/ComplexHeatmap-reference/book/index.html
往期内容:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









