







一.定义
1.串:由0个或多个字符组成的有限序列
2.空串:由零个字符组成的串,长度为0
3.空格串:由一个或多个空格组成的串,长度为空格字符的个数
4.子串:字符串中任意个连续的字符构成的序列。空串是所有串的子串。
5.两串相等:长度和每个对应字符都相等
6.长度/位置:空格也是字符,也占一个长度/位置,注意计算
7.字符位置:某个字符在串中的序号
8.子串在主串的位置:按子串的第一个字符计
二.基本操作
StrAssign(&T, chars):赋值操作。把串T赋值为chars
StrCopy(&T, S):复制操作。由串S复制得到串T
StrEmpty(S):判空操作。若S为空串, 则返回TRUE, 否则返回FALSE
Strcompare(S, T):比较操作。若S > T, 则返回值 > 0; 若s = T, 则返回值 = 0; 若s < T, 则返回值 < 0
StrLength(S) :求串长。返回串S的元素个数
SubString(&Sub, S, pos, len):求子串。用Sub返回串S的第pos个字符起长度为len的子串
Concat(&T, S1, S2):串联接。用T返回由S1和S2联接而成的新串
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0
clearString(&S):清空操作。将S清为空串
DestroyString(&S):销毁串。将串S销毁
例:在串S中第pos个字符之后查找是否存在串T,若有,返回第一个这样的子串在S中的位置,否则返回0
int Index(String S, String T, int pos) {
if (pos > 0) {
n = StrLength(S);//n为主串S的长度
m = StrLenght(T);//m为子串T的长度
while (pos <= n - m + 1) {
SubString(&sub, S, pos, m);//用Sub返回串S的第pos个字符起长度为m的子串
if(StrCompare(sub,T)!=0)//若匹配成功返回值为0
pos++;
else
return pos;
}
}
return 0;
}
三.存储结构
1.定长顺序存储表示
与顺序表类似
#define MAXLEN 255
typedef struct {
char ch[MAXLEN];
int length;
}SString;
串超过MAXLEN的部分会被舍去(截断)
2.堆分配存储表示
堆分配存储表示仍然以一组地址连续的存储单元存放串值的字符序列,但它们的存储空间是在程序执行过程中动态分配得到的
typedef struct {
char *ch;
int length;
}HString;
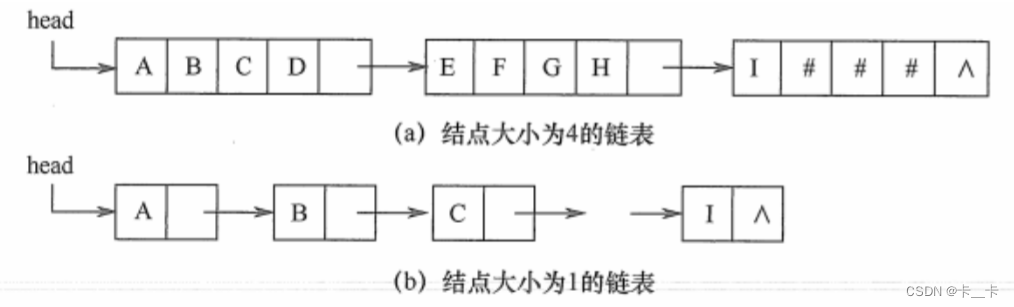
3.块链存储表示
类似于单链表,每个结点既可以存放一个字符,也可以存放多个字符。每个结点称为块,整个链表称为块链结构。最后一个结点不满时用“#”填补
四.模式匹配算法
(一)基础

未匹配成功,再对比下一个子串

直到成功或最后未找到
(二)进阶
1.如果主串长度为n,则长度为m的子串共有n-m+1个,因此最多对比次数n-m+1
2.代码原理

i和j同时后移,逐个对比是否匹配成功

此时i=6=j
在第6个位置匹配失败,继续重新对比下一个子串
指针移动:
i=i-j+2(现在i指向2)
j=1

直到结束
此时i和j指向的字符一直相等,不断后移,当j超出模式串长度(T.length)时匹配成功

3.代码实现
int Index(SString S, SString T) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (S.ch[i] == T.ch[j]) {
++i;
++j;
}
else {
i = i - j + 2;
j = 1;
}
}
if (j > T.length)
return i - T.length;
else
return 0;
}
4.时间复杂度
主串长度为n,模式串长度为m,一般来说n>>m
最坏:O((n-m+1)m)=O(nm)
最好(匹配成功): O(m)
最好(匹配失败): O(n-m+1)=O(n)
五.KMP算法
若1-5匹配成功,6匹配失败
则可知道1-5为abaab

即

此时i=j=6
继续后移比较,后两次比较显然匹配失败
(2-1失败)

(4-2失败)

再次后移比较,可以看到,此时需要继续探索?处的数据,且直接比较6-3即可。
为提高效率,我们省略刚刚两次显然失败的比较,直接跳转到此处,并让i指向6,j指向3

即

此时,i=6,j=3
原来:i=6,j=6
可以看到,在起初第5次匹配失败的情况后,保持i指针位置不动,j指针指向3,可以达到更好的效率,这就是KMP算法
(原来i=j=6,第5次匹配失败情况↑)
以上是第5次匹配失败的情况,下面我们再探究其他情况
1.第4次匹配失败情况
此时i=j=4

跳过↓
(2-1失败)

继续后移

此时i=4,j=2
原来i=4=j
即在第4次匹配失败后,下次比较:i不变,j移动到2
2.第3次匹配失败
此时i=j=3

跳过
(2-1失败)

继续后移

此时i=3,j=1
原来:i=3=j
即在第3次匹配失败后,下次比较:i不变,j移动到1
3.第2次匹配失败

此时i=j=2
继续后移

此时i=2,j=1
即在第2次匹配失败后,下次比较:i不变,j移动到1
4.第1次匹配失败

此时i=j=1
继续后移

为了方便表示,先让j=0,然后i和j同时+1
即在第1次匹配失败后,下次比较:j=0,i++,j++

可以看到,规律(指针移动)的得出是由模式串决定的,与主串无关,因此该规律对于相同的模式串在所有匹配中是通用的
总结

KMP算法中主串指针i是不回溯的,而朴素模式匹配算法中i需要回溯
将其用一个next数组表示,next数组也只和模式串有关,与主串无关
next[i]表示第i个元素匹配失败

【代码实现】
int Index_KMP(SString S, SString T, int next[]) {//需要传入next数组
int i = 1, j = 1;
while (i <= S.length && j <= T.length)
{
if (j == 0 || S.ch[i] == T.ch[j])
{ //相等就继续比较,j=0时同时++
++i;
++j;
}
else
j = next[j];//匹配失败,j根据next数组移动,i不变(j=0时在上面)
}
if (j > T.length)
return i - T.length;//匹配成功,返回子串在主串中的位置(第一个字符位置)
else
return 0;//匹配失败
}
【效率分析】
主串长度为n,模式串长度为m
求next数组的时间复杂度O(m)
模式匹配过程最坏时间复杂度O(n)
故KMP算法时间复杂度O(m+n)
【求next数组】
1.通过刚才的分析,对于任意的模式串,当第一个元素匹配失败时,令j=0,然后i和j一起后移,故j需要移动到0的位置,next[1]=0成立
2.当第二个元素匹配失败时,模式串后移一次,next[2]=1成立
(具体情况具体分析)

其他同上
【练习】

【解析】在KMP算法中,为了使公式更简洁,如果串的位序是从1开始的,则next数组需要整体加1;如果串的位序是从0开始的,则next数组不需要整体加1。本题中选项均为-1起,说明串的位序从1开始,next数组整体加1
【答案】C
















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











