







问题疑问
1.为什么要叫写入时复制集合?
2.CopyOnWriteArrayList 实现原理是什么?
3.CopyOnWriteArrayList 和 ArrayList 有什么区别?
4.CopyOnWriteArrayList 复制是怎么进行复制的?
接下来就让我们带着这几个问题,从源码入手,来进一步了解写入时复制的原理和过程吧!
一:源码分析
CopyOnWriteArrayList基本结构

参数介绍
*1.基于数组实现
*2.使用了ReentrantLock互斥锁
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
/** 数据有变动时使用 */
final transient ReentrantLock lock = new ReentrantLock();
/** 数组 只能通过 getArray/setArray 访问 */
private transient volatile Object[] array;
final Object[] getArray() {
return array;
}
// 将数组指向传入的新数组
final void setArray(Object[] a) {
array = a;
}
}
构造函数
*在初始化CopyOnWriteArrayList时,创建了一个object类型的数组
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
add方法
1.通过互斥锁(ReentrantLock),保证了在写的时候只能有一个线程可以去写。
*2.新增元素时,先试用Arrays.copyOf(elements,len+1)的新数组
*3.添加新元素到新数组
*4.然后再将原数组对象指向新数组
public boolean add(E e) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 获取当前数组
Object[] elements = getArray();
int len = elements.length;
// 创建一个新数组,并将原数组数据复制到新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 添加的新元素到数组尾部
newElements[len] = e;
// 将数组指向新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
add方法图解:

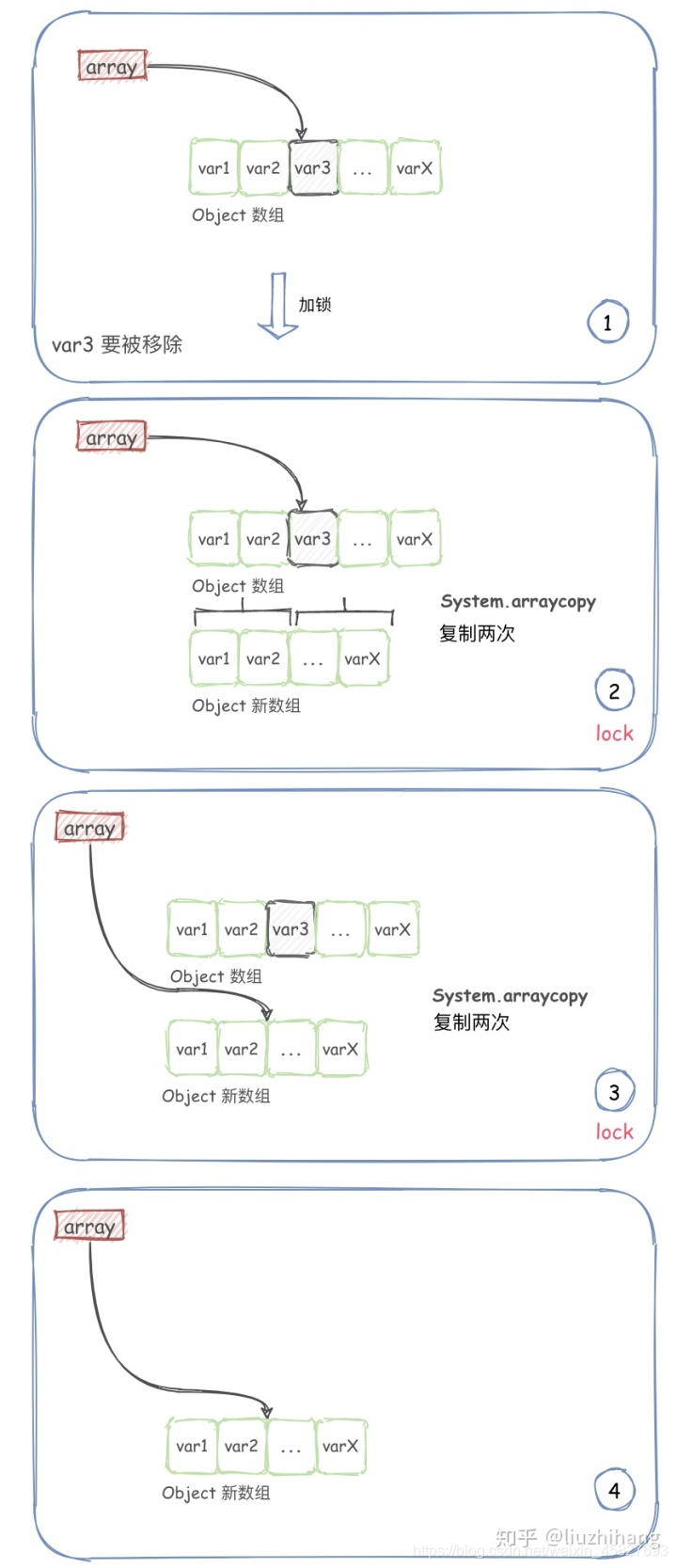
remove方法
public E remove(int index) {
// 加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 原数组
Object[] elements = getArray();
int len = elements.length;
// 移除的值
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
// 如果移除最后一个元素
// 直接复制前面的元素即可
setArray(Arrays.copyOf(elements, len - 1));
else {
// 移除中间的元素,进行两次复制
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
*1.加了互斥锁,保证在写的时候只能同时有一个线程可以移除元素。
*2.如果移除的是最后一个元素,则直接复制前面的元素到新数组,并指向新数组即可。
*3.如果移除的是中间的元素,则需要进行两次复制,然后指向新数组。
remove方法图解:
get方法
*1.获取元素并没有进行加锁
*2.从原数组获取的元素
public E get(int index) {
return get(getArray(), index);
}
数组的复制Arrays.copyOf和System.arraycopy
1.Arrays.copyOf
读过源码我们会发现,其底层也是System.arraycopy实现的嗷
public class Arrays {
// 其他方法省略 ...
/**
* original 要复制的数组
* newLength 新数组的长度
*/
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
/**
* original 要复制的数组
* newLength 新数组的长度
*/
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
// 创建一个新数组,长度是指定的长度
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
// 创建具有指定的组件类型和长度的新数组
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
// 调用 System.arraycopy 复制数组
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
}
2.System.arraycopy
可以看到 System.arraycopy 是一个 native 方法,这个是 JVM 内部实现的,想深入了解的小伙伴可以自行阅读相关资料哈
public final class System {
// 其他方法省略 ...
/**
* src 源数组
* srcPos 源数组起始位置
* dest 目标数组
* destPos 目标数组的起始位置
* length 要复制的元素数量
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
}
总结:
通过对源码的阅读,我们现在既可以回答文章开始提到的那几个问题了0.0
1.为什么要叫写入时复制集合?
因为在 add、remove 操作时会复制出来一个新数组。
2.CopyOnWriteArrayList 实现原理是什么?
在 add、remove 操作时会进行加锁,然后复制出来一个新数组,操作的都是新数组,而此时原数组是可以提供查询的。当操作结束之后,会将对象指针指向新数组。
3.CopyOnWriteArrayList 和 ArrayList 有什么区别?
CopyOnWriteArrayList 在读多写少的场景下可以提高效率,而 ArrayList 只是普通数组集合,并不适用于并发场景,而如果对 ArrayList 加锁,则会影响一部分性能。
同样对 CopyOnWriteArrayList 而言,仅能保证最终一致性。因为刚写入的数据,是写到的复制的数组中,此时并不能立即查询到。如果要保证实时性可以尝试使用 Collections.synchronizedList 或者加锁等方式。
4. CopyOnWriteArrayList 复制是怎么进行复制的?
内部使用的是本地方法 System.arraycopy 进行数组的复制。
这次的讨论就到这里了哈,欢迎小伙伴们留言讨论!















 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









