







文章目录
如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在?

有小伙伴知道其他解决方案可以在评论区打出来!
而我今天要说的方式是布隆过滤器
一、什么是布隆过滤器?
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难
布隆过滤器可以用于解决缓存击穿的问题,那么问题来了?什么是缓存击穿呢?

二、什么是缓存穿透?
缓存穿透是指查询内存和数据库都不存在的数据,每次请求都会打到数据库上,从而压垮数据库
2.1 缓存穿透具体是怎么产生的呢?

在这种情况下,因为数据库值不存在,所以肯定不会写入 Redis,那么下一次查询相同的 key 的时候,肯定还是会再到数据库查一次,这种因为每次查询的值都不存在导致的 Redis 失效的情况,这种现象叫做缓存穿透。
2.2 那么我们如何解决呢?
思路:我们有没有什么办法避免应用到数据库查询呢?
**方案1:**给key缓存特殊字符串,比如&& 或则缓存空字符串
我们可以在数据库缓存一个空字符串,或者缓存一个特殊的字符串,那么在应用里面拿到这个特殊字符串的时候,就知道数据库没有值了,也没有必要再到数据库查询了。
方案1问题:
1)会导致我redis的内存中无效数据过大
2)本来数据库中没有这条记录,假设数据库已经新增了这一条记录,由于缓存中缓存的是特殊字符串,应用也还是拿不到值
这个问题我们应该怎么去解决呢?
上面我们说了可以用布隆过滤器解决缓存击穿的问题,我们是这样解决的:
准备一个足够长的数组,将值存入数据库的时候,同时将key存入布隆过滤器
查找key的时候,先去布隆过滤器中获取这个key的三个hash值,在根据hash值去布隆过滤器中获取值,三个值中有一个0,代表数据肯定不存在,如果三个值都是1,代表可能存在,再去数据库查找数据
除此之外 我们还可以通过缓存null来解决缓存穿透的问题
分析
了解了布隆过滤器,那么问题拉回来:我们如何在海量元素中(例如 10 亿无序、不定长、不重复)快速判断一个元素是否存在呢?
特点:
- 数据量特别大
- 快速判断
解决方案:不使用数据库,将数据加载到内存中
问题来了:如果我们直接把这些元素的值放到基本的数据结构(List、Map、Tree)里面,比如一个元素 1 字节(1byte)的字段,10 0000 0000 (10亿)的数据大概需要 900G 的内存空间,这个对于普通的服务器来说是承受不了的。
所以,我们存储这几十亿个元素,不能直接存值,我们应该找到一种最简单的最节省空间的数据结构,用来标记这个元素有没有出现。
这个数据结构就是位图(bitmap),他是一个有序的数组,只有两个值,0 和 1。0 代表不存在,1 代表存在。
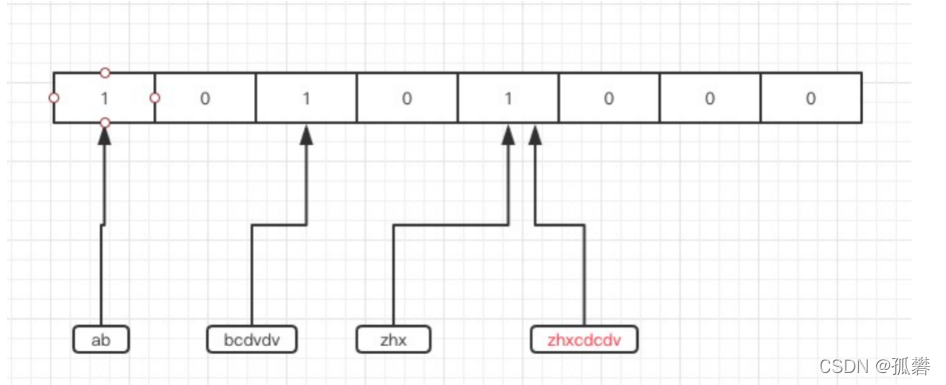
那我们怎么用这个数组里面的有序的位置来标记这10亿个元素是否存在呢?我们是不是必须要有一个映射方法把元素映射到一个下标位置上?
对于这个映射方法,我们有几个基本的要求:
1)因为我们的值长度是不固定的,我希望不同长度的输入,可以得到固定长度的输出。
2)转换成下标的时候,我希望他在我的这个有序数组里面是分布均匀的,不然的话全部挤到一对去了,我也没法判断到底哪个元素存了,哪个元素没存。
这就得使用哈希函数(比如 MD5、SHA-1 等等这些都是常见的哈希算法)。
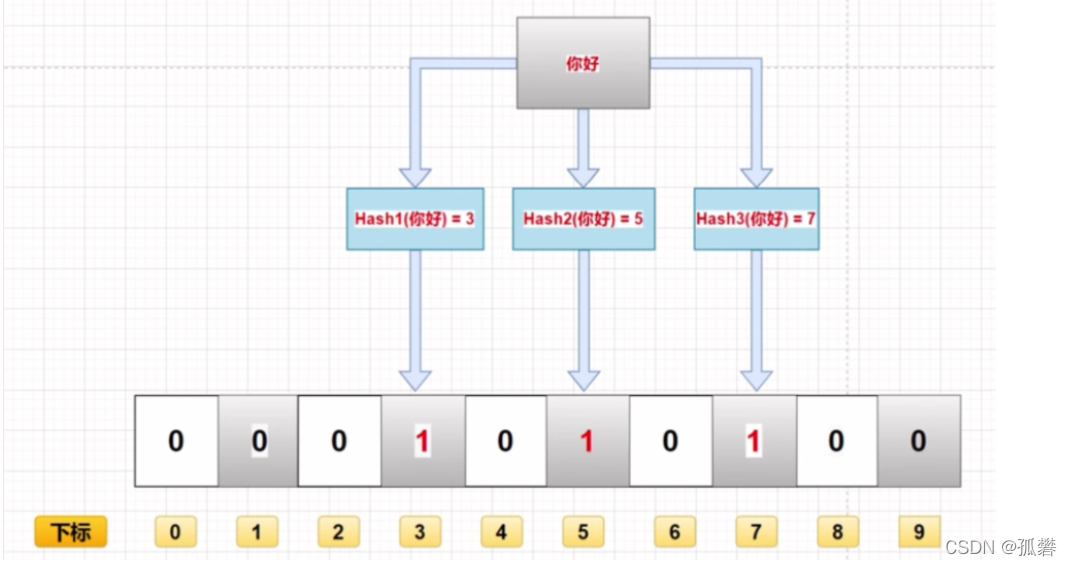
比如,下图就是"你好",经过哈希函数,得到了相应的下标。
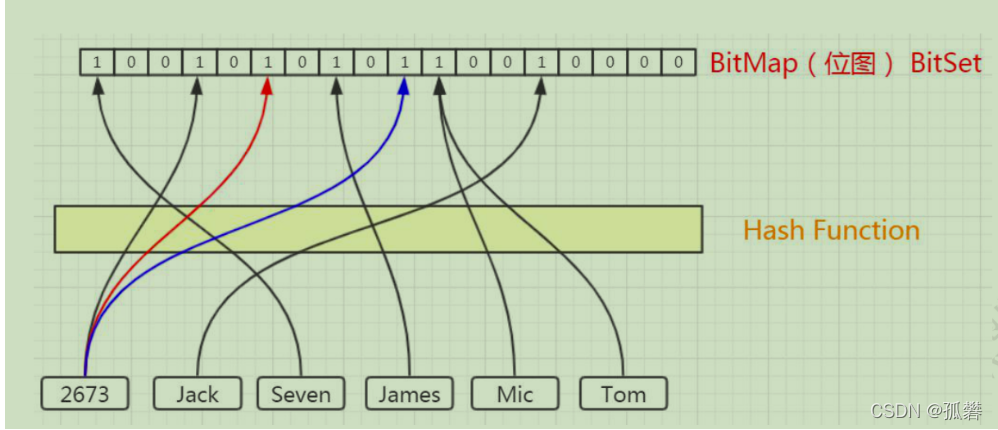
比如,这 6 个元素,我们经过哈希函数和位运算,得到了相应的下标。
3.1 hash碰撞
这个时候,Tom 和 Mic 经过计算得到的哈希值是一样的,那么再经过位运算得到的下标肯定是一样的,我们把这种情况叫做哈希冲突或者哈希碰撞。
如果发生了哈希碰撞,这个时候对于我们的容器存值肯定是有影响的,我们可以通过哪些方式去降低哈希碰撞的概率呢?
1)第一种就是扩大维数组的长度或者说位图容量。因为我们的函数是分布均匀的,所以,位图容量越大,在同一个位置发生哈希碰撞的概率就越小。
是不是位图容量越大越好呢?不管存多少个元素,都创建一个几万亿大小的位图,
当然不行,因为越大的位图容量,意味着越多的内存消耗,所以我们要创建一个合适大小的位图容量。
2)除了扩大位图容量,我们还有什么降低哈希碰撞概率的方法呢?
如果两个元素经过一次哈希计算,得到的相同下标的概率比较高,我可以不可以计算多次呢? 原来我只用一个哈希函数,现在我对于每一个要存储的元素都用多个哈希函数计算,这样每次计算出来的下标都相同的概率就小得多了。
同样的,我们能不能引入很多个哈希函数呢?比如都计算 100 次,都可以吗?当然也会有问题,第一个就是它会填满位图的更多空间,第二个是计算是需要消耗时间的。
综上:我们既要节省空间,又要很高的计算效率,就必须在位图容量和函数个数之间找到一个最佳的平衡。
比如说:我们存放 100 万个元素,到底需要多大的位图容量,需要多少个哈希函数呢?
https://hur.st/bloomfilter/?n=1000000&p=0.03&m=&k=
3.2布隆过滤器的原理
当然,这个事情早就有人研究过了,在 1970 年的时候,有一个叫做布隆的前辈对于 判断海量元素中元素是否存在的问题进行了研究,也就是到底需要多大的位图容量和多 少个哈希函数,它发表了一篇论文,提出的这个容器就叫做布隆过滤器。
我们来看一下布隆过滤器的工作原理。
首先,布隆过滤器的本质就是我们刚才分析的,一个位数组,和若干个哈希函数。
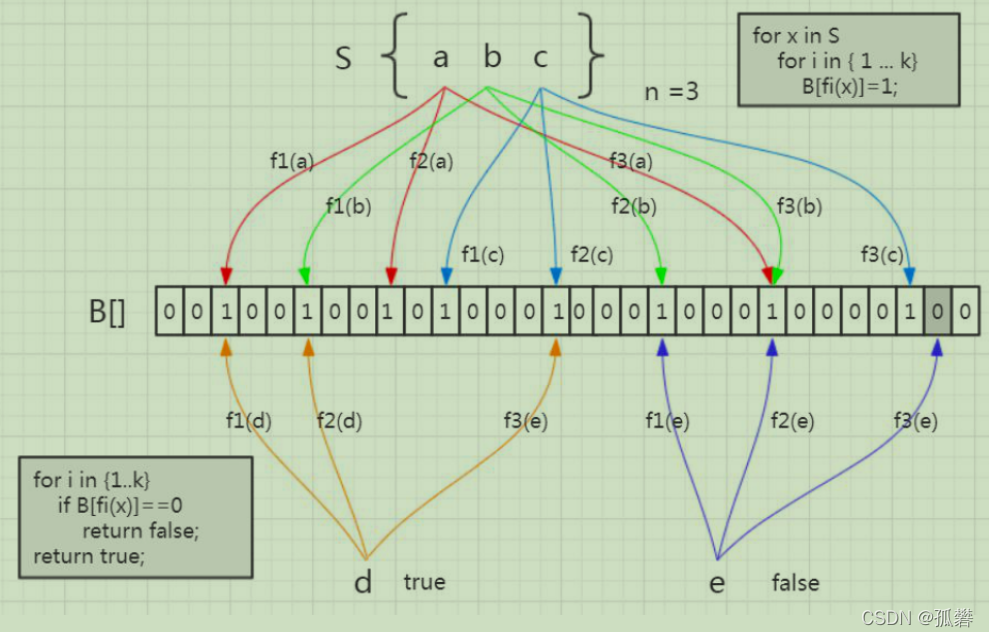
集合里面有 3 个元素,要把它存到布隆过滤器里面去,应该怎么做?首先是 a 元素,这里我们用 3 次计算。b、c 元素也一样。
元素已经存进去之后,现在我要来判断一个元素在这个容器里面是否存在,就要使用同样的三个函数进行计算。
比如d元素,我用第一个函数 f1 计算,发现这个位置上是 1,没问题。第二个位置也是 1,第三个位置也是 1 。如果经过三次计算得到的下标位置值都是 1,这种情况下,能不能确定 d 元素一定在这个容器里面呢?
实际上是不能的。比如这张图里面,这三个位置分别是把 a,b,c 存进去的时候置成 1 的,所以即使 d 元素之前没有存进去,也会得到三个 1,判断返回 true。
所以,这个是布隆过滤器的一个很重要的特性,因为哈希碰撞不可避免,所以它会存在一定的误判率。这种把本来不存在布隆过滤器中的元素误判为存在的情况,我们把 它叫做假阳性(False Positive Probability,FPP)。
我们再来看另一个元素,e 元素。我们要判断它在容器里面是否存在,一样地要用这三个函数去计算。第一个位置是 1,第二个位置是 1,第三个位置是 0。e 元素是不是一定不在这个容器里面呢? 可以确定一定不存在。如果说当时已经把 e 元素存到布隆过滤器里面去了,那么这三个位置肯定都是 1,不可能出现 0。
总结:布隆过滤器的特点:
1.从容器的角度来说:
- 如果布隆过滤器判断元素在集合中存在,这个元素可能存在
- 如果布隆过滤器判断元素不存在,这个元素一定不存在
2.从元素的角度来说:
- 如果元素实际存在,布隆过滤器一定判断存在
- 如果元素实际不存在,布隆过滤器可能判断存在
利用第二个特性,我们就能解决持续从数据库查询不存在的值的问题
4.布隆过滤器-代码实现
4.1 布隆过滤器的实现
4.1.1 入门案例
目标:实现布隆过滤器的基本使用
实现思路:使用guava的自带的布隆过滤器
操作步骤:
- 导入jar包
- 编写代码
- 创建布隆过滤器
- 产生随机uuid
- 放入布隆过滤器
- 判断是否存在,并打印结果
【第一步】谷歌的 Guava 里面就提供了一个现成的布隆过滤器。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
【第二步】编写测试类
- 创建布隆过滤器
- 产生随机uuid
- 放入布隆过滤器
- 判断是否存在,并打印结果
package com.czxy.demo02;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.text.NumberFormat;
import java.util.*;
/**
*
* 测试布隆过滤器的基本使用:存放数据和判断数据是否存在
*
*/
public class BloomFilterDemo01 {
private static final int insertions = 1000000;
public static void main(String[] args) {
// 1 初始化一个存储string数据的布隆过滤器,初始化大小为100W
// 默认误判率是0.03
BloomFilter<String> bf = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8), insertions);
// 向布隆过滤器中初始化100W个随机并且唯一的字符串
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
if (bf.mightContain(uuid+"7899")) {
System.out.println("存在:" + uuid);
}else{
System.out.println("不存在"+uuid);
}
}
}
4.1.2 进阶使用-布隆过滤器的误判率到底怎样?
实现思路:
package com.czxy.demo02;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.text.NumberFormat;
import java.util.*;
/**
*
* 测试布隆过滤器的正确判断和误判
* 往布隆过滤器里面存放100万个元素
* 测试100个存在的元素和9900个不存在的元素
*
*/
public class BloomFilterDemo02 {
private static final int insertions = 1000000;
public static void main(String[] args) {
// 初始化一个存储string数据的布隆过滤器,初始化大小为100W
// 默认误判率是0.03
BloomFilter<String> bf = BloomFilter.create(
Funnels.stringFunnel(Charsets.UTF_8), insertions);
// 用于存放所有实际存在的key,可以取出使用
List<String> lists = new ArrayList<String>(insertions);
// 向三个容器初始化100W个随机并且唯一的字符串
for (int i = 0; i < insertions; i++) {
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
lists.add(uuid);
}
int right = 0; // 正确判断的次数
int wrong = 0; // 错误判断的次数
for (int i = 0; i < 10000; i++) {
// 可以被100整除的时候,取一个存在的数。否则随机生成一个UUID
// 0-10000之间,可以被100整除的数有100个(100的倍数)
String data = i % 100 == 0 ? lists.get(i / 100) : UUID.randomUUID().toString();
if (bf.mightContain(data)) {
if (lists.contains(data)) {
// 判断存在实际存在的时候,命中
right++;
continue;
}
// 判断存在却不存在的时候,错误
wrong++;
}
}
//保留小数
// NumberFormat percentFormat =NumberFormat.getPercentInstance();
// percentFormat.setMaximumFractionDigits(2); //最大小数位数
float percent = (float) wrong / 9900;
float bingo = (float) right / 9900;
System.out.println("在100W个元素中,判断100个实际存在的元素,布隆过滤器认为存在的:"+right);
System.out.println("在100W个元素中,判断9900个实际不存在的元素,误认为存在的:"+wrong+"" );
}
}
4.2 布隆过滤器在项目中的使用
4.2.1 布隆过滤器的工作位置:
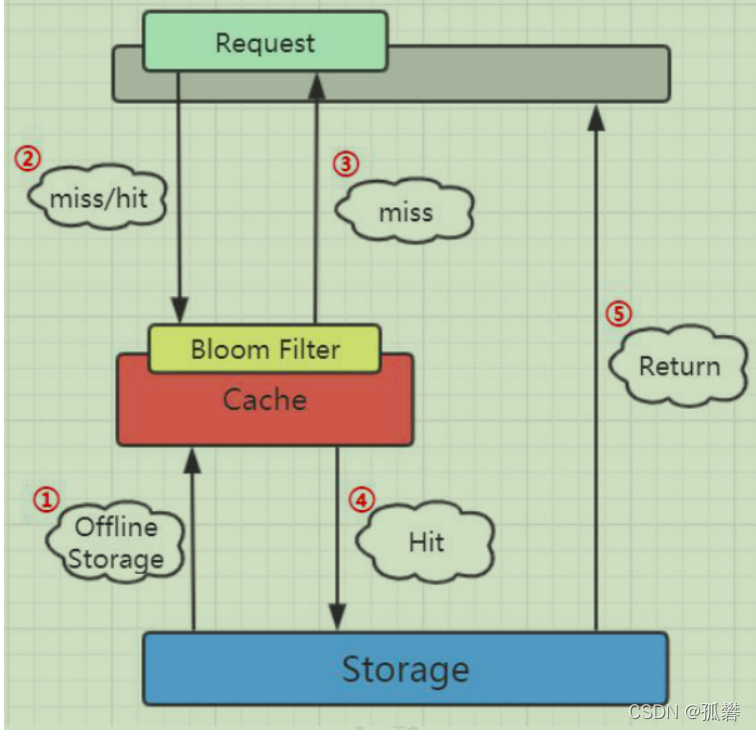
因为要判断数据库的值是否存在,所以第一步是加载数据库所有的数据。在去 Redis查询之前,先在布隆过滤器查询,如果 bf 说没有,那数据库肯定没有,也不用去查了。 如果 bf 说有,才走之前的流程。
4.2.1 准备工作-创建项目,导入数据
【第一步】创建数据库,并且导入表
`create database bloom01;
use bloom01;
CREATE TABLE `user` (
`id` int(36) NOT NULL AUTO_INCREMENT,
`account` varchar(96) DEFAULT NULL,
`name` varchar(20) DEFAULT NULL,
`age` int(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=100001 DEFAULT CHARSET=utf8;`
【第二步】创建项目bloom-test01
【第三步】导入jar包
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.6</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- Guava布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
<!-- CountingBloomFilter 带计数器的布隆过滤器-->
<!-- https://mvnrepository.com/artifact/com.baqend/bloom-filter -->
<dependency>
<groupId>com.baqend</groupId>
<artifactId>bloom-filter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.21</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Junit依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<!--MyBatis-Plus代码生成器需要的依赖,开始-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.4.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.velocity/velocity-engine-core -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.freemarker/freemarker -->
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.30</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
<!-- swagger start -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.6.0</version>
</dependency>
<!-- swagger end -->
</dependencies>
【第三步】配置yml文件
server:
port: 8090
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/bloom01?useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
【第四步】引入工具类
【第五步】编写实体类
package com.czxy.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* 用户实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
@TableId(type = IdType.AUTO)
private Integer id; // ID,数据库自增
private String account; // 登录账号,UUID生成
private String name; // 姓名
private Integer age; // 年龄
}
【第六步】创建mapper
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.czxy.pojo.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
【第七步】创建service接口
import com.baomidou.mybatisplus.extension.service.IService;
import com.czxy.pojo.User;
public interface UserService extends IService<User> {
}
【第八步】创建service实现类
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.czxy.mapper.UserMapper;
import com.czxy.pojo.User;
import com.czxy.service.UserService;
import org.springframework.stereotype.Service;
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
【第九步】创建测试类,生成10000条数据,插入数据库
package com.czxy;
import com.czxy.mapper.UserMapper;
import com.czxy.pojo.User;
import com.czxy.service.impl.UserServiceImpl;
import com.czxy.util.NameUtil;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.jdbc.core.BatchPreparedStatementSetter;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.UUID;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
public class UserBatchInsert01 {
@Autowired
private UserServiceImpl userService;
List<User> list;
private static final int USER_COUNT = 10000; // 数量过大可能导致内存溢出,多运行几次
@Test
public void test() {
long start = System.currentTimeMillis();
list = new ArrayList<>();
for (int i=0; i< USER_COUNT; i++){
User user = new User();
String account = UUID.randomUUID().toString();
user.setAccount(account);
int min=18;
int max=60;
Random random = new Random();
// 年龄范围在18-60之间
int age = random.nextInt(max)%(max-min+1) + min;
user.setAge(age);
user.setName(NameUtil.getRandomName());
list.add(user);
}
userService.saveBatch(list);
long end = System.currentTimeMillis();
System.out.println("批量插入"+USER_COUNT+"条用户数据完毕,总耗时:" + (end - start) + " 毫秒");
}
}
【第十步】测试,成功
4.2.3 项目中使用
3.2.3.1 流程分析
3.2.3.2 代码编写
【第一步】编写UserService
public interface UserService extends IService<User> {
public List<User> getUserByAccount(String account);
}
【第二步】在UserserviceImpl中实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public List<User> getUserByAccount(String account) {
//创建一个QueryWrapper的对象
QueryWrapper<User> wrapper = new QueryWrapper<>();
//通过QueryWrapper设置条件
//ge gt le lt
//查询age>=30的记录
//第一个参数是字段的名称 , 第二个参数是设置的值
wrapper.eq("account" , account);
List<User> users = userMapper.selectList(wrapper);
return users;
}
}
【第三步】编写测试代码
package com.czxy.demo03;import com.czxy.pojo.User;import com.czxy.service.UserService;import com.google.common.base.Charsets;import com.google.common.hash.BloomFilter;import com.google.common.hash.Funnels;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.autoconfigure.EnableAutoConfiguration;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.data.redis.core.ValueOperations;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import javax.annotation.PostConstruct;import javax.annotation.Resource;import java.text.SimpleDateFormat;import java.util.Date;import java.util.List;/** * 布隆过滤器并发测试,在redis和数据库之间 */@RunWith(SpringJUnit4ClassRunner.class)@SpringBootTest@EnableAutoConfigurationpublic class BloomTestsConcurrency { @Resource private StringRedisTemplate redisTemplate; @Autowired private UserService userService; static BloomFilter<String> bf; static List<User> allUsers; @PostConstruct public void init() { // 从数据库获取数据,加载到布隆过滤器 long start = System.currentTimeMillis(); allUsers = userService.list(); if (allUsers == null || allUsers.size() == 0) { return; } // 创建布隆过滤器,默认误判率0.03,即3%// bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), allUsers.size()); // 误判率越低,数组长度越长,需要的哈希函数越多 bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), allUsers.size(), 0.0001); // 将数据存入布隆过滤器 for (User user : allUsers) { bf.put(user.getAccount()); } long end = System.currentTimeMillis(); System.out.println("加载"+allUsers.size()+"条数据到布隆过滤器完毕,总耗时:"+(end -start ) +"毫秒"); } @Test public void cacheBreakDownTest() { String randomUser = "26b0b7b7-c87c-43cb-8a07-a16cadcc02af"; Date date1 = new Date(); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); // 如果布隆过滤器中不存在这个用户直接返回,将流量挡掉 if (!bf.mightContain(randomUser)) { System.out.println(sdf.format(date1)+" 布隆过滤器中不存在,非法请求"); return; } // 查询缓存,如果缓存中存在直接返回缓存数据 ValueOperations<String, String> operation = redisTemplate.opsForValue(); Object cacheUser = operation.get(randomUser); if (cacheUser != null) { Date date2 = new Date(); System.out.println(sdf.format(date2)+" 命中redis缓存"); return; } // 如果缓存不存在查询数据库 List<User> user = userService.getUserByAccount(randomUser); if (user == null || user.size() == 0) { System.out.println("Redis缓存不存在,查询数据库也不存在,发生缓存穿透"); return; } // 将mysql数据库查询到的数据写入到redis中 Date date3 = new Date(); System.out.println(sdf.format(date3)+" 缓存不存在,从数据库查询并写入Reids"); operation.set(user.get(0).getAccount(), user.get(0).getAccount()); }}
4.3 布隆过滤器其他应用场景
布隆过滤器解决的问题是什么?如何在海量元素中快速判断一个元素是否存在。所以除了解决缓存穿透的问题之外,我们还有很多其他的用途。
1、比如爬虫,爬过的 url 不需要重复爬,那么在几十亿的 url 里面,怎么判断一个 url 是不是已经爬过了?
2、邮箱服务器,判断邮件账号是否是垃圾账号
总结
核心:布隆过滤器,判断可能存在,或者一定不存在














 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









