







一、简介
PageRank,又称网页排名、谷歌左侧排名、PR,是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法。
佩奇排名本质上是一种以网页之间的超链接个数和质量作为主要因素粗略地分析网页的重要性的算法。其基本假设是:更重要的页面往往更多地被其他页面引用(或称其他页面中会更多地加入通向该页面的超链接)。 其将从A页面到B页面的链接解释为“A页面给B页面投票”,并根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票对象的等级来决定被投票页面的等级。简单的说,一个高等级的页面可以提升其他低等级的页面。
二、概述
PageRank是一种链接分析算法,它通过对超链接集合中的元素用数字进行权重赋值,实现“衡量集合范围内某一元素的相关重要性”的目的。该算法可以应用于任何含有元素之间相互引用的情况的集合实体。
PageRank的结果来源于一种基于图论的数学算法。它将万维网上所有的网页视作节点(node),而将超链接视作边(edge),并且考虑到了一些权威的网站,类似CNN。每个节点的权重值表示对应的页面的重要度。通向该网页的超链接称做“对该网页的投票(a vote of support)”。每个网页的权重值大小被递归地定义,依托于所有链接该页面的页面的权重值。例如,一个被很多页面的链接的页面将会拥有较高的权重值(high PageRank)。
三、算法
假设一个由4个网页组成的集合:A,B,C和D。同一页面中多个指向相同的链接视为同一个链接,并且每个页面初始的PageRank值相同,最初的算法将每个网页的初始值设定为1。但是在后来的版本以及下面的示例中,为了满足概率值位于0到1之间的需要,我们假设这个值是0.25。
在每次迭代中,给定页面的PR值(PageRank值)将均分到该页面所链接的页面上。
如果所有页面都只链接至A,那么A的PR值将是B,C及D的PR值之和,即:
P R ( A ) = P R ( B ) + P R ( C ) + P R ( D ) PR(A)=PR(B)+PR(C)+PR(D) PR(A)=PR(B)+PR(C)+PR(D)
重新假设B链接到A和C,C链接到A,并且D链接到A,B,C。最初一个页面总共只有一票。所以B给A ,C每个页面半票。以此类推,D投出的票只有三分之一加到了A的PR值上:
P R ( A ) = P R ( B ) 2 + P R ( C ) 1 + P R ( D ) 3 PR(A)={\frac {PR(B)}{2}}+{\frac {PR(C)}{1}}+{\frac {PR(D)}{3}} PR(A)=2PR(B)+1PR(C)+3PR(D)
换句话说,算法将根据每个页面连出总数 L ( X ) L(X) L(X)平分该页面的PR值,并将其加到其所指向的页面:
P R ( A ) = P R ( B ) L ( B ) + P R ( C ) L ( C ) + P R ( D ) L ( D ) PR(A)={\frac {PR(B)}{L(B)}}+{\frac {PR(C)}{L(C)}}+{\frac {PR(D)}{L(D)}} PR(A)=L(B)PR(B)+L(C)PR(C)+L(D)PR(D)
或者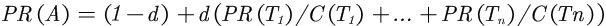
- PR(A) 是页面A的PR值
- PR(Ti)是页面Ti的PR值,在这里,页面Ti是指向A的所有页面中的某个页面
- C(Ti)是页面Ti的出度,也就是Ti指向其他页面的边的个数
- d 为阻尼系数,其意义是,在任意时刻,用户到达某页面后并继续向后浏览的概率,
该数值是根据上网者使用浏览器书签的平均频率估算而得,通常d=0.85
最后,所有这些PR值被换算成百分比形式再乘上一个修正系数 d d d。由于“没有向外链接的网页”传递出去的PR值会是0,而这会递归地导致指向它的页面的PR值的计算结果同样为零,所以赋给每个页面一个最小值 ( 1 − d ) / N (1-d)/N (1−d)/N(N为页面的总数)
P R ( A ) = ( P R ( B ) L ( B ) + P R ( C ) L ( C ) + P R ( D ) L ( D ) + ⋯ ) d + 1 − d N PR(A)=\left({\frac {PR(B)}{L(B)}}+{\frac {PR(C)}{L(C)}}+{\frac {PR(D)}{L(D)}}+\,\cdots \right)d+{\frac {1-d}{N}} PR(A)=(L(B)PR(B)+L(C)PR(C)+L(D)PR(D)+⋯)d+N1−d
- 需要注意的是,在Sergey Brin和Lawrence Page的1998年原版论文中给每一个页面设定的最小值是 1 − d 1-d 1−d,而不是这里的 ( 1 − d ) / N (1-d)/N (1−d)/N,这将导致集合中所有网页的PR值之和为N(N为集合中网页的数目)而非所期待的1。
因此,一个页面的PR值直接取决于指向它的的页面。如果在最初给每个网页一个随机且非零的PR值,经过重复计算,这些页面的PR值会趋向于某个定值,也就是处于收敛的状态,即最终结果。这就是搜索引擎使用该算法的原因。
那么什么时候,迭代结束哪?一般要设置收敛条件:比如上次迭代结果与本次迭代结果小于某个误差,我们结束程序运行;比如还可以设置最大循环次数。
四、PageRank的缺点
PageRank算法的主要缺点在于旧的页面的排名往往会比新页面高。因为即使是质量很高的新页面也往往不会有很多外链,除非它是某个已经存在站点的子站点。这也是PageRank需要多项算法结合以保证其结果的准确性的原因。
五、Python实现迭代法
下面仅仅实现迭代法,代码如下,需要用到Python的numpy库用于矩阵乘法:
# 输入为一个*.txt文件,例如
# A B
# B C
# B A
# ...表示前者指向后者
import numpy as np
if __name__ == '__main__':
# 读入有向图,存储边
f = open('input_1.txt', 'r')
edges = [line.strip('\n').split(' ') for line in f]
print(edges)
# 根据边获取节点的集合
nodes = []
for edge in edges:
if edge[0] not in nodes:
nodes.append(edge[0])
if edge[1] not in nodes:
nodes.append(edge[1])
print(nodes)
N = len(nodes)
# 将节点符号(字母),映射成阿拉伯数字,便于后面生成A矩阵/S矩阵
i = 0
node_to_num = {}
for node in nodes:
node_to_num[node] = i
i += 1
for edge in edges:
edge[0] = node_to_num[edge[0]]
edge[1] = node_to_num[edge[1]]
print(edges)
# 生成初步的S矩阵
S = np.zeros([N, N])
for edge in edges:
S[edge[1], edge[0]] = 1
print(S)
# 计算比例:即一个网页对其他网页的PageRank值的贡献,即进行列的归一化处理
for j in range(N):
sum_of_col = sum(S[:,j])
for i in range(N):
S[i, j] /= sum_of_col
print(S)
# 计算矩阵A
alpha = 0.85
A = alpha*S + (1-alpha) / N * np.ones([N, N])
print(A)
# 生成初始的PageRank值,记录在P_n中,P_n和P_n1均用于迭代
P_n = np.ones(N) / N
P_n1 = np.zeros(N)
e = 100000 # 误差初始化
k = 0 # 记录迭代次数
print('loop...')
while e > 0.00000001: # 开始迭代
P_n1 = np.dot(A, P_n) # 迭代公式
e = P_n1-P_n
e = max(map(abs, e)) # 计算误差
P_n = P_n1
k += 1
print('iteration %s:'%str(k), P_n1)
print('final result:', P_n)
输入的input_1.txt文本内容为:
A B
A C
A D
B D
C E
D E
B E
E A
结果为:
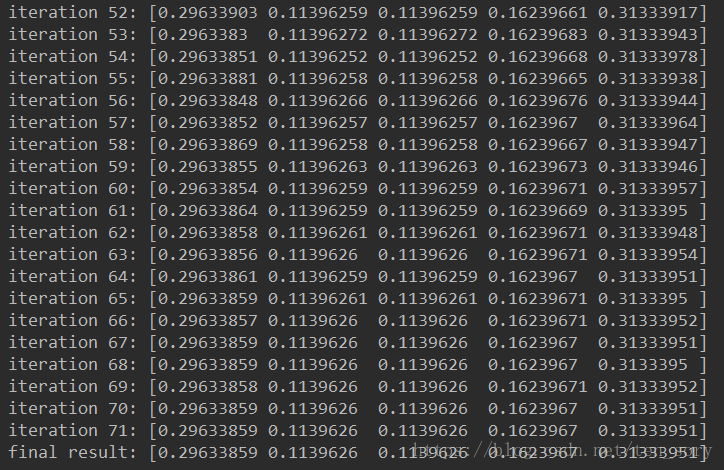
最后的一个数组,分别为A, B, C, D, E的PageRank值,其中E最高, A第二高, B和C相同均最低。
参考文献
[1] PageRank算法原理与实现
















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









