






1. 前言
2. 环境准备
3. 编写爬虫
4. 结果展示
5. 总结
6. 脚本下载
7. 参考资料
1. 前言
简单分析了每个博客的文章分类,阅读排行榜,评论排行榜及推荐排行榜,最后统计汇总并生成词云。正好这也算是一篇非常好的Python爬虫入门教程了。
2. 环境准备
2.1 操作系统及浏览器版本
Windows 10
Chrome 62
2.2 Python版本
Python 2.7
2.3 用到的lib库
1. requests Http库
2. re 正则表达式
3. json json数据处理
4. BeautifulSoup Html网页数据提取
5. jieba 分词
6. wordcloud 生成词云
7. concurrent.futures 异步并发
所有模块均可使用pip命令安装,如下:
pip install requests pip install beautifulsoup4 pip install jieba pip install wordcloud pip install futures
3. 编写爬虫
上面的环境准备好之后,我们正式开始编写爬虫,但是写代码之前,我们首先需要对需要爬取的页面进行分析。
3.1 页面分析
3.1.1 博客园首页推荐博客排行
1. 运行Chrome浏览器,按快捷键F12打开开发者工具,打开博客园首页:https://www.cnblogs.com/
2. 在右侧点击Network,选中XHR类型,点击下面的每一个请求都可以看到详细的Http请求信息
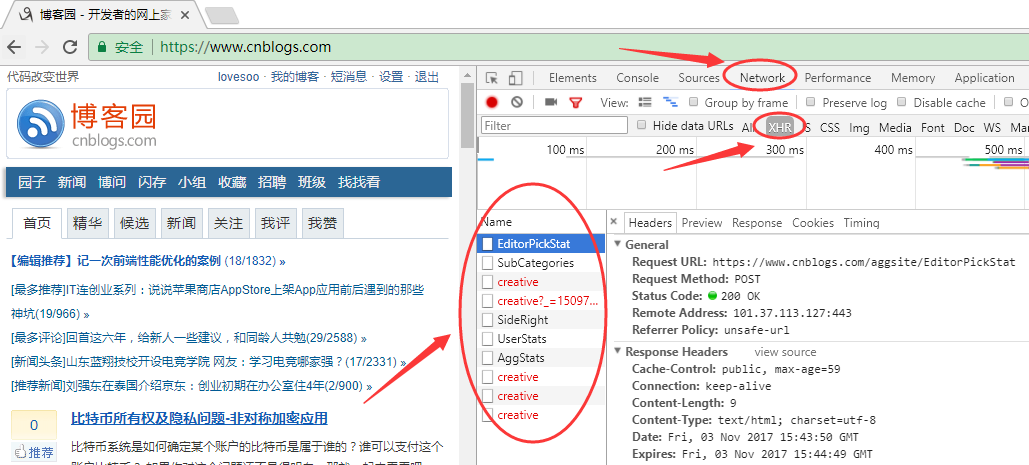
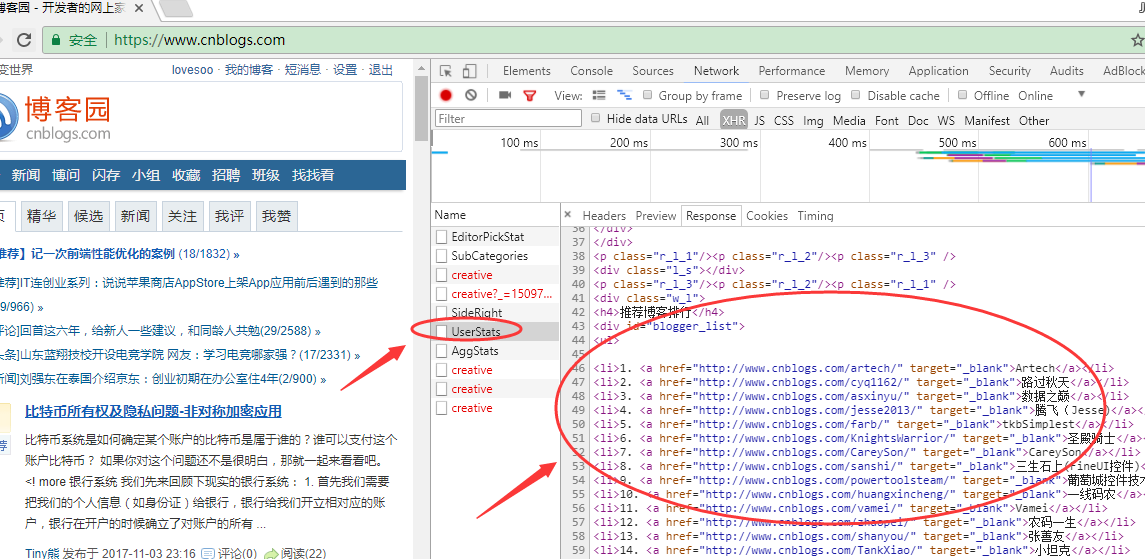
3. 依次选中右侧的Response,查看接口响应,筛选我们需要的接口,这里我们找到了UserStats接口,可以看到这个接口返回了我们需要的“推荐博客排行”信息
4. 点击右侧Headers查看详细的接口信息,可以看到这是一个简单的Http GET接口,不需要传递任何参数:https://www.cnblogs.com/aggsite/UserStats

5. 这样我们使用requests编写简单的请求就可以获取首页“推荐博客排行”信息
#coding:utf-8
import requests
r=requests.get('https://www.cnblogs.com/aggsite/UserStats')
print r.text
返回结果如下:
![]()
View Code
可以看到返回的内容是HTML格式,这里我们有两种方法可以获取“推荐博客排行”,一种是使用Beautiful Soup解析Html内容,另外一种是使用正则表达式筛选内容。代码如下:
#coding:utf-8
import requests
import re
import json
from bs4 import BeautifulSoup
# 获取推荐博客列表
r = requests.get('https://www.cnblogs.com/aggsite/UserStats')
# 使用BeautifulSoup解析
soup = BeautifulSoup(r.text, 'lxml')
users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']]
print json.dumps(users,ensure_ascii=False)
# 也可以使用使用正则表达式
user_re=re.compile('<a href="(http://www.cnblogs.com/.+)" target="_blank">(.+)</a>')
users=[(name,url) for url,name in re.findall(user_re,r.text) if 'AllBloggers.aspx' not in url and 'expert' not in url]
print json.dumps(users,ensure_ascii=False)
运行结果如下:
View Code
其中BeautifulSoup解析时,我们使用的是CSS选择器.select方法,查找id="blogger_list" > ul >li下的所有a标签元素,同时对结果进行处理,去除了"更多推荐博客"及""博客列表(按积分)链接。
使用正则表达式筛选也是同理:我们首先构造了符合条件的正则表达式,然后使用re.findall找出所有元素,同时对结果进行处理,去除了"更多推荐博客"及""博客列表(按积分)链接。
这样我们就完成了第一步,获取了首页推荐博客列表。
3.1.2 博客随笔分类
1. 同理,我们使用Chrome开发者工具,打开博客页面进行分析
2. 我们找到了接口sidecolumn.aspx,这个接口返回了我们需要的信息:随笔分类
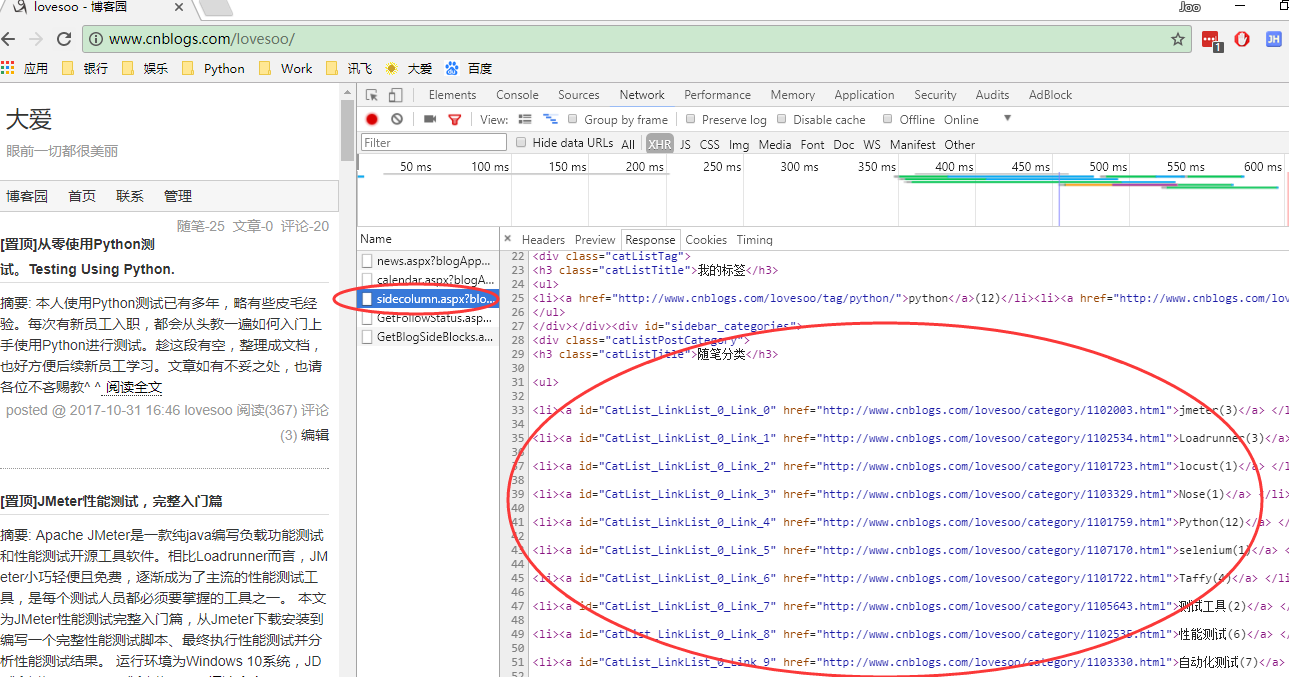
3. 点击Headers查看接口调用信息,可以看到这也是一个GET类型接口,路径含有博客用户名,且传入参数blogApp=用户名:http://www.cnblogs.com/lovesoo/mvc/blog/sidecolumn.aspx?blogApp=lovesoo

4. 使用Requests发送GET请求,获取“随笔分类”示例代码如下:
#coding:utf-8
import requests
user='lovesoo'
url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user)
blogApp = user
payload = dict(blogApp=blogApp)
r = requests.get(url, params=payload)
print r.text
返回结果如下:
View Code
同理,我们使用BeautifulSoup解析获取分类信息,同时使用正则表达式获取分类名及文章数目,代码如下:
#coding:utf-8
import requests
import re
import json
from bs4 import BeautifulSoup
# 获取博客随笔分类
user='lovesoo'
category_re = re.compile('(.+)\((\d+)\)')
url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user)
blogApp = user
payload = dict(blogApp=blogApp)
r = requests.get(url, params=payload)
soup = BeautifulSoup(r.text, 'lxml')
category = [re.search(category_re, i.text).groups() for i in soup.select('.catListPostCategory > ul > li') if re.search(category_re, i.text)]
print json.dumps(category,ensure_ascii=False)
返回结果如下:
![]()
View Code
这样我们就完成了第二步,获取了博客的分类目录及文章数量信息。
3.1.3 博客阅读\评论\推荐排行榜
1. 下面我们开始获取博客的排行榜信息,同理我们找到了接口GetBlogSideBlocks.aspx,它返回了我们需要的排行榜信息
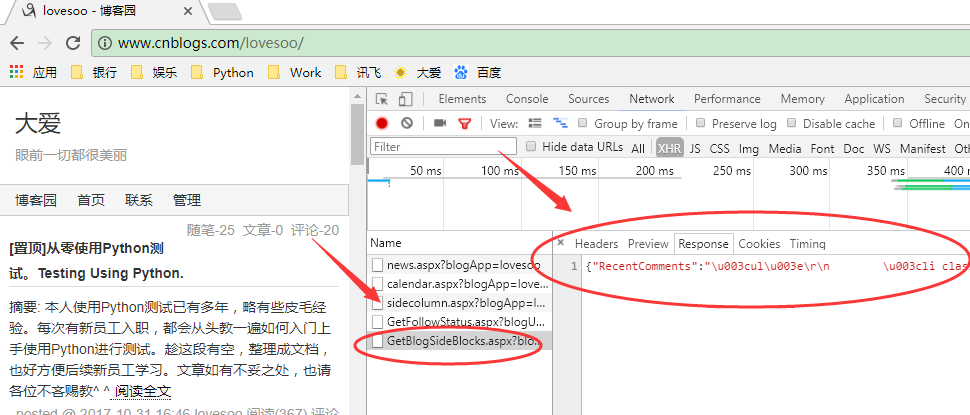
2. 点击Headers查看接口调用信息,可以看到这是一个GET请求接口,传入参数有2个,分别是blogApp和showFlag,其中blogApp是博客用户名,showFlag是显示标记,默认值为ShowRecentComment,ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts分别代表返回最新评论,阅读排行榜,评论排行榜,推荐排行榜。根据需要我们配置只返回3个排行榜信息即可:http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx?blogApp=lovesoo&showFlag=ShowTopViewPosts%2CShowTopFeedbackPosts%2CShowTopDiggPosts
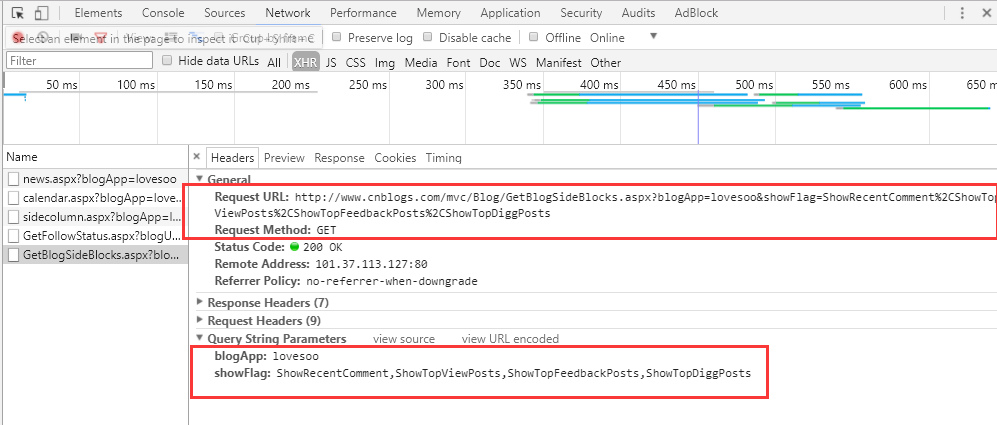
3. 使用Requests调用GET接口获取排行榜信息,示例代码如下:
#coding:utf-8 import requests import json # 获取博客阅读排行榜,评论排行榜及推荐排行榜信息 user='lovesoo' url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx' blogApp = user showFlag = 'ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts' payload = dict(blogApp=blogApp, showFlag=showFlag) r = requests.get(url, params=payload) print json.dumps(r.json(),ensure_ascii=False)
返回结果如下:
![]()
View Code
可以看出,这个接口返回数据格式与前2个不同,返回的是json格式,有四个key:RecentComments,TopViewPosts,TopFeedbackPosts,TopDiggPosts分别对应最新评论,阅读排行榜,评论排行榜,推荐排行榜,而每个key里的value又是html格式,针对这个value我们编写统一的信息提取方法:使用BeautifulSoup解析获取文本及链接信息,同时使用正则表达式获取文章标题及次数,示例代码如下:
#coding:utf-8
import requests
import re
import json
from bs4 import BeautifulSoup
def getPostsDetail(Posts):
# 获取文章详细信息:标题,次数,URL
post_re = re.compile('\d+\. (.+)\((\d+)\)')
soup = BeautifulSoup(Posts, 'lxml')
return [list(re.search(post_re, i.text).groups()) + [i['href']] for i in soup.find_all('a')]
# 获取博客阅读排行榜,评论排行榜及推荐排行榜信息
user='lovesoo'
url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx'
blogApp = user
showFlag = 'ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts'
payload = dict(blogApp=blogApp, showFlag=showFlag)
r = requests.get(url, params=payload)
TopViewPosts = getPostsDetail(r.json()['TopViewPosts'])
TopFeedbackPosts = getPostsDetail(r.json()['TopFeedbackPosts'])
TopDiggPosts = getPostsDetail(r.json()['TopDiggPosts'])
print json.dumps(dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts),ensure_ascii=False)
运行结果如下:
View Code
至此,我们完成了第三步也是最重要的,提取博客排行榜信息。下面我们开始使用异步并发抓取100位大佬的博客信息。
3.2 异步并发抓取
我们把上面的三步提取信息操作均封装成函数,并将博客提取信息的两步(提取分类及排行榜)封装成一个统一的函数供异步并发调用即可。这里我们推荐使用多进程的方式,配置的并发数与CPU核数一致即可,示例代码如下:
# coding:utf-8
import requests
import re
import json
from bs4 import BeautifulSoup
from concurrent import futures
def getUsers():
# 获取推荐博客列表
r = requests.get('https://www.cnblogs.com/aggsite/UserStats')
# 使用BeautifulSoup解析
soup = BeautifulSoup(r.text, 'lxml')
users = [(i.text, i['href']) for i in soup.select('#blogger_list > ul > li > a') if 'AllBloggers.aspx' not in i['href'] and 'expert' not in i['href']]
# 也可以使用使用正则表达式
# user_re=re.compile('<a href="(http://www.cnblogs.com/.+)" target="_blank">(.+)</a>')
# users=[(name,url) for url,name in re.findall(blog_re,r.text) if 'AllBloggers.aspx' not in url and 'expert' not in url]
return users
def getPostsDetail(Posts):
# 获取文章详细信息:标题,次数,URL
post_re = re.compile('\d+\. (.+)\((\d+)\)')
soup = BeautifulSoup(Posts, 'lxml')
return [list(re.search(post_re, i.text).groups()) + [i['href']] for i in soup.find_all('a')]
def getViews(user):
# 获取博客阅读排行榜,评论排行榜及推荐排行榜信息
url = 'http://www.cnblogs.com/mvc/Blog/GetBlogSideBlocks.aspx'
blogApp = user
showFlag = 'ShowTopViewPosts,ShowTopFeedbackPosts,ShowTopDiggPosts'
payload = dict(blogApp=blogApp, showFlag=showFlag)
r = requests.get(url, params=payload)
TopViewPosts = getPostsDetail(r.json()['TopViewPosts'])
TopFeedbackPosts = getPostsDetail(r.json()['TopFeedbackPosts'])
TopDiggPosts = getPostsDetail(r.json()['TopDiggPosts'])
return dict(TopViewPosts=TopViewPosts, TopFeedbackPosts=TopFeedbackPosts, TopDiggPosts=TopDiggPosts)
def getCategory(user):
# 获取博客随笔分类
category_re = re.compile('(.+)\((\d+)\)')
url = 'http://www.cnblogs.com/{0}/mvc/blog/sidecolumn.aspx'.format(user)
blogApp = user
payload = dict(blogApp=blogApp)
r = requests.get(url, params=payload)
soup = BeautifulSoup(r.text, 'lxml')
category = [re.search(category_re, i.text).groups() for i in soup.select('.catListPostCategory > ul > li') if re.search(category_re, i.text)]
return dict(category=category)
def getTotal(url):
# 获取博客全部信息,包括分类及排行榜信息
# 初始化博客用户名
print 'Spider blog:\t{0}'.format(url)
user = url.split('/')[-2]
return dict(getViews(user), **getCategory(user))
def mutiSpider(max_workers=4):
try:
# with futures.ThreadPoolExecutor(max_workers=max_workers) as executor: # 多线程
with futures.ProcessPoolExecutor(max_workers=max_workers) as executor: # 多进程
for blog in executor.map(getTotal, [i[1] for i in users]):
blogs.append(blog)
except Exception as e:
print e
if __name__ == '__main__':
blogs = []
# 获取推荐博客列表
users = getUsers()
print json.dumps(users, ensure_ascii=False)
# 多线程/多进程获取博客信息
mutiSpider()
print json.dumps(blogs,ensure_ascii=False)
运行结果:略
3.3 数据处理
数据处理主要是对上面生成的好的大批量数据进行处理,主要是数据合并分组,其中相对复杂的是分类数据,基本处理逻辑如下:
1. 第一步,将所有的分类数据合并保存在一个list中,示例代码:
# 获取所有分类目录信息 category = [category for blog in blogs if blog['category'] for category in blog['category']]
2. 第二步,合并计算相同目录(由于不用的博客可能存在相同的分类,如都有叫做Python的分类,则该分类文章数量需要累加计算),示例代码如下
def countCategory(category, category_name):
# 合并计算目录数
n = 0
for name, count in category:
if name.lower() == category_name:
n += int(count)
return n
# 获取所有分类目录信息
category = [category for blog in blogs if blog['category'] for category in blog['category']]
# 合并相同目录
new_category = {}
for name, count in category:
# 全部转换为小写
name = name.lower()
if name not in new_category:
new_category[name] = countCategory(category, name)
3. 第三步,根据数量进行排序,直接使用sorted方法根据count数进行排序即可,示例代码如下:
sorted(new_category.items(), key=lambda i: int(i[1]), reverse=True)
排行榜数据处理相对比较简单,只需先合并成一个list后再进行排序即可,如阅读排行榜数据处理示例代码:
TopViewPosts = [post for blog in blogs for post in blog['TopViewPosts']] sorted(TopViewPosts, key=lambda i: int(i[1]), reverse=True
3.4 生成词云
生成词云主要步骤如下:
1. 使用join方法拼接list为长文本
2. 使用jieba进行中文分词
3. 使用wordcloud生成词云并保存及展示相关图片
示例代码如下:
# 拼接为长文本
contents = ' '.join([i[0] for i in words])
# 使用结巴分词进行中文分词
cut_texts = ' '.join(jieba.cut(contents))
# 设置字体为黑体,最大词数为2000,背景颜色为白色,生成图片宽1000,高667
cloud = WordCloud(font_path='C:\Windows\Fonts\simhei.ttf', max_words=2000, background_color="white", width=1000, height=667, margin=2)
# 生成词云
wordcloud = cloud.generate(cut_texts)
# 保存图片
wordcloud.to_file('wordcloud\{0}.png'.format(file_name))
# 展示图片
wordcloud.to_image().show()















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









