






Java如何实现敏感词过滤
Trie树(算法实现)
Trie 树,也叫字典树或前缀树,是一种用来存储字符串集合的数据结构。 它是由多个节点组成的树状结构,每个节点代表一个字符,从根节点开始到叶子节点,可以组成一个字符串。Trie 树的一个特点是它可以高效地支持字符串的插入、查找和删除操作。
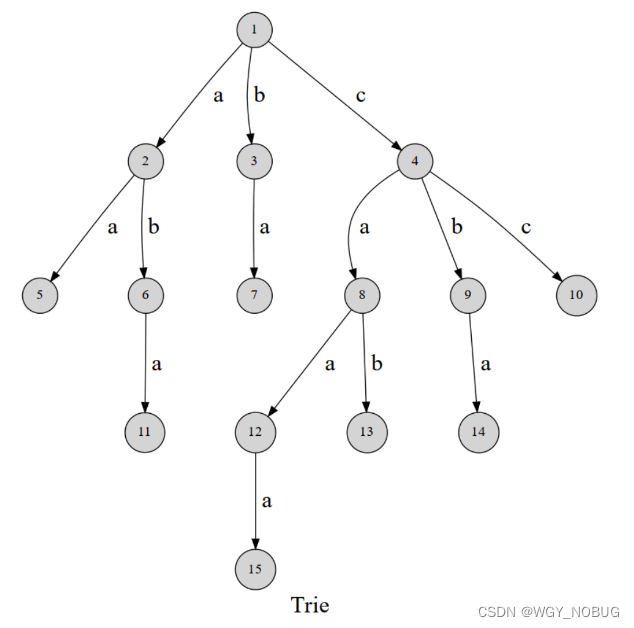
如何通过Trie树过滤出是否存在敏感词,假设咱们的敏感词库中,包含以下四个敏感词,通过Trie树的形式进行筛选 ,(桃色电影,桃色网址,日本片,日本av)
那么Trie树的基本结构如下图所示:
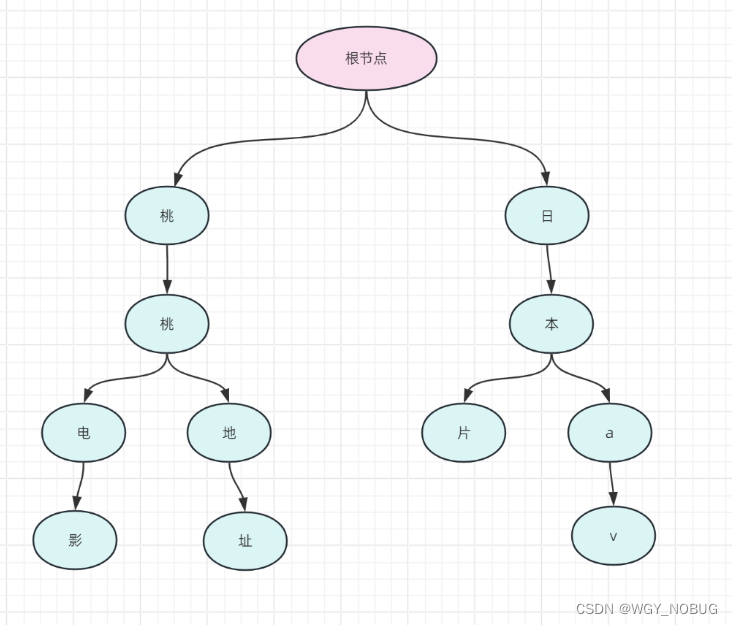
问题:筛选出桃色电影,如下图所示,会将其切分为桃、色、电、影,从根节点开始匹配。
总结:Trie 树算法的核心原理,通过公共前缀来提高匹配效率。
实现:关于 Trie 树的实现,在 Apache Commons Collections 这个库中就有现成的,通过添加如下依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
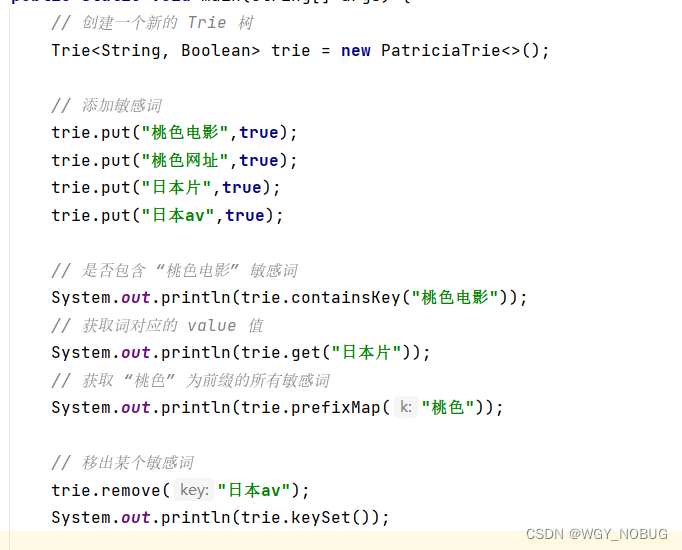
如下图代码所示,根据提供的api可筛选并移出拦截的敏感词

ToolGood 库
要想实现敏感词过滤功能,我们可以借助一些开源的第三库,它们内部已经将相关算法都封装好了。
ToolGood官方地址
介绍
ToolGood 是一款高性能敏感词(非法词/脏字)检测过滤组件,附带繁体简体互换,支持全角半角互换,汉字转拼音,模糊搜索等功能。
依赖
<!-- 敏感词过滤 -->
<dependency>
<groupId>io.github.toolgood</groupId>
<artifactId>toolgood-words</artifactId>
<version>3.1.0.1</version>
</dependency>
敏感词库
在 ToolGood 官方 GitHub 仓库中,我们可以找到一份体积大小为 200 多 kb 的敏感词库 txt 文件,如下图所示:
下载到本地,并在 /resources 目录下,新建一个 word 文件夹,将该 txt 文件复制进去,
以下代码作用:
此配置类主要作用是,将 ToolGood 库中的 IllegalWordsSearch 敏感词搜索类,加载到 Spring 容器中,方便后续在业务层中直接使> > 用,具体逻辑如下:
初始化 IllegalWordsSearch 敏感词搜索类; 读取 /resource 文件夹下的 sensi_words.txt 敏感词库,一行一行的读取并添加; 调用 IllegalWordsSearch 类的 SetKeywords() 方法来设置敏感词;
import com.google.common.collect.Lists;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ResourceLoader;
import toolgood.words.IllegalWordsSearch;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
@Configuration
@Slf4j
public class ToolGoodConfig {
@Bean
public IllegalWordsSearch illegalWordsSearch(ResourceLoader resourceLoader) throws IOException {
log.info("==> 开始初初始化敏感词工具类 ...");
IllegalWordsSearch illegalWordsSearch = new IllegalWordsSearch();
log.info("==> 加载敏感词 txt 文件 ...");
// 读取 /resource 目录下的敏感词 txt 文件
List<String> sensitiveWords = Lists.newArrayList();
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(resourceLoader.getResource("classpath:word/sensi_words.txt").getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
if (StringUtils.isNotBlank(line.trim())) {
sensitiveWords.add(line.trim());
}
}
}
// 设置敏感词
illegalWordsSearch.SetKeywords(sensitiveWords);
log.info("==> 初始化敏感词工具类成功 ...");
return illegalWordsSearch;
}
}
如何使用?
一,先自动注入 IllegalWordsSearch 敏感词搜索类;
二,若开启了敏感词过滤功能,则调用 ContainsAny() 方法,检测评论内容是否包含词库中的敏感词;
三,若检测到了敏感词,则将状态设置为审核不通过;
四,通过 FindAll() 方法,拿到匹配到的所有敏感词组,将其转换为字符串集合;
五,设置 reason 审核不通过的原因,以及包含的敏感词;
代码如下:
// 代码上下逻辑处使用 ------>>>>>>>
// 评论内容是否包含敏感词
boolean isContainSensitiveWord = false;
// 是否开启了敏感词过滤
if (isCommentSensiWordOpen) {
// 校验评论中是否包含敏感词
isContainSensitiveWord = wordsSearch.ContainsAny(content);
if (isContainSensitiveWord) {
// 若包含敏感词,设置状态为审核不通过
status = CommentStatusEnum.EXAMINE_FAILED.getCode();
// 匹配到的所有敏感词组
List<IllegalWordsSearchResult> results = wordsSearch.FindAll(content);
List<String> keywords = results.stream().map(result -> result.Keyword).collect(Collectors.toList());
// 不同过的原因
reason = String.format("系统自动拦截,包含敏感词:%s", keywords);
log.warn("此评论内容中包含敏感词: {}, content: {}", keywords, content);
}
}















 841
841











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











